









“ ETL是建立数据仓库最重要的处理过程,是Extract、Transform、Load三个英文单词首字母的简写,中文意为抽取、转换、装载。”
数据的ETL过程
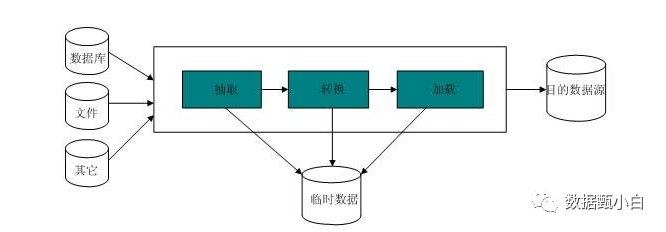
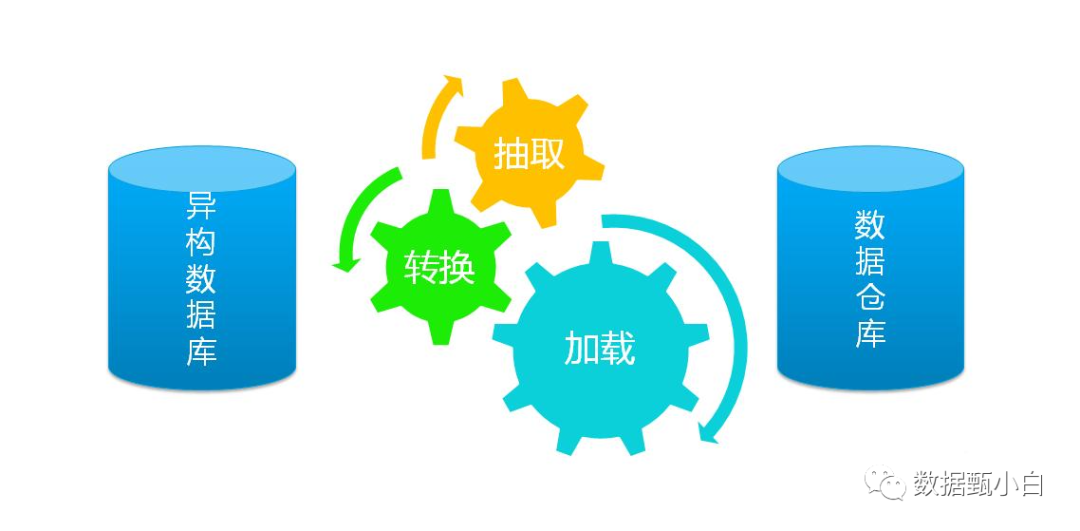
在日常的开发或交流中,会多次提到了ETL一词,它是Extract、Transform、Load三个英文单词首字母的简写,中文意为抽取、转换、装载。ETL是建立数据仓库最重要的处理过程,也是最体现工作量的环节,一般会占到整个数据仓库项目工作量的一半以上。
其中:
-
抽取:从操作型数据源获取数据。
-
转换:转换数据,使之转变为适用于查询和分析的形式和结构。
-
装载:将转换后的数据导入到最终的目标数据仓库。
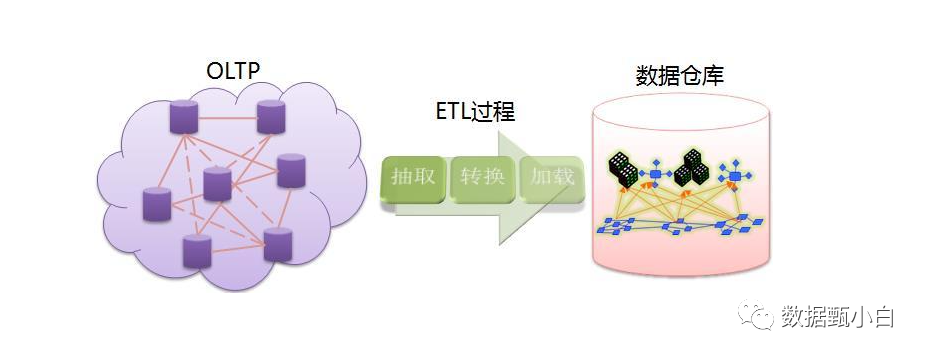
建立一个数据仓库,就是要把来自于多个异构的源系统的数据集成在一起,放置于一个集中的位置用于数据分析。如果一开始这些源系统数据就是兼容的当然最好,但情况往往不是这样。ETL系统的工作就是要把异构的数据转换成同构的。如果没有ETL,不可能对异构的数据进行程序化的分析。
ETL-E:抽取
抽取操作从源系统获取数据给后续的数据仓库环境使用。这是ETL处理的第一步,也是最重要的一步。数据被成功抽取后,才可以进行转换并装载到数据仓库中。能否正确地获取数据直接关系到后面步骤的成败。设计和建立数据抽取过程,在ETL处理乃至整个数据仓库处理过程中,一般是较为耗时的任务。源系统很可能非常复杂并且缺少相应的文档,因此只是决定需要抽取哪些数据可能就已经非常困难了。通常数据都不是只抽取一次,而是需要以一定的时间间隔反复抽取,通过这样的方式把数据的所有变化提供给数据仓库,并保持数据的及时性。除此之外,源系统一般不允许外部系统对它进行修改,也不允许外部系统对它的性能和可用性产生影响,数据仓库的抽取过程要能适应这样的需求。
如果已经明确了需要抽取的数据,下一步就该考虑从源系统抽取数据的方法了。对抽取方法的选择高度依赖于源系统和目标数据仓库环境的业务需要。一般情况下,不可能因为需要提升数据抽取的性能,而在源系统中添加额外的逻辑,也不能增加这些源系统的工作负载。有时,用户甚至都不允许增加任何“开箱即用”的外部应用系统,这叫做对源系统具有侵入性。对于数据抽取,一般会有两块方式:逻辑抽取和物理抽取。
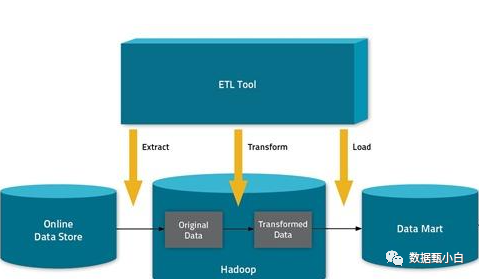
逻辑抽取
逻辑抽取又包含两种抽取类型:全量抽取和增量抽取。
(1)全量抽取
源系统的数据全部被抽取。因为这种抽取类型影响源系统上当前所有有效的数据,所以不需要跟踪自上次成功抽取以来的数据变化。源系统只需要原样提供现有的数据而不需要附加的逻辑信息(比如时间戳等)。
(2)增量抽取
只抽取某个事件发生的特定时间点之后的数据。通过该事件发生的时间顺序能够反映数据的历史变化,它可能是最后一次成功抽取,也可能是一个复杂的业务事件,但必须能够标识出特定时间点之后所有的数据变化。
物理抽取
依赖于选择的逻辑抽取方法和能够对源系统所做的操作和所受的限制,存在两种物理数据抽取机制:直接从源系统联机抽取或者间接从一个脱机结构抽取数据。这个脱机结构有可能已经存在,也可能需要由抽取程序生成。
(1)联机抽取
数据直接从源系统抽取。抽取进程或者直连源系统数据库,访问它们的数据表,或者连接到一个存储快照日志或变更记录表的中间层系统。注意这个中间层系统并不需要必须和源系统物理分离。
(2)脱机抽取
数据不从源系统直接抽取,而是从一个源系统以外的过渡区抽取。过渡区可能已经存在(例如数据库备份文件、关系数据库系统的重做日志、归档日志等),或者抽取程序自己建立。
应该考虑以下的存储结构:
-
数据库备份文件。一般需要数据还原操作才能使用。
-
备用数据库。
-
平面文件。数据定义成普通格式,关于源对象的附加信息(列名、数据类型等)需要另外处理。
-
导出文件。关系数据库大都自带数据导出功能,如Oracle的exp/expdp程序和MySQL的mysqldump程序,都可以用于生成导出数据文件。
-
重做日志和归档日志。每种数据库系统都有自己的日志格式和解析工具。
ETL-T:转换
数据从操作型源系统获取后,需要进行多种转换操作。如统一数据类型、处理拼写错误、消除数据歧义、解析为标准格式等。数据转换通常是最复杂的部分,也是ETL开发中用时最长的一步。数据转换的范围极广,从单纯的数据类型转化到极为复杂的数据清洗技术。
在数据转换阶段,为了能够最终将数据装载到数据仓库中,需要在已经抽取来的数据上应用一系列的规则和函数。有些数据可能不需要转换就能直接导入到数据仓库。
数据转换一个最重要的功能是清洗数据,目的是只有“合规”的数据才能进入目标数据仓库。这步操作在不同系统间交互和通信时尤其必要。
ETL-L:装载
ETL的最后步骤是把转换后的数据装载进目标数据仓库。这步操作需要重点考虑两个问题,一是数据装载的效率问题,二是一旦装载过程中途失败了,如何再次重复执行装载过程。要提高装载的效率,加快装载速度,可以从以下几方面入手。首先保证足够的系统资源。数据仓库存储的都是海量数据,所以要配置高性能的服务器,并且要独占资源,不要与别的系统共用。在进行数据装载时,要禁用数据库约束(唯一性、非空性,检查约束等)和索引,当装载过程完全结束后,再启用这些约束,重建索引,这种方法会很大的提高装载速度。
在数据仓库环境中,一般不使用数据库来保证数据的参考完整性,即不使用数据库的外键约束,它应该由ETL工具或程序来维护。数据装载过程可能由于多种原因而失败,比如装载过程中某些源表和目标表的结构不一致而导致失败,而这时已经有部分表装载成功了。在数据量很大的情况下,如何能在重新执行装载过程时只装载失败的部分是一个不小的挑战。对于这种情况,实现可重复装载的关键是要记录下失败点,并在装载程序中处理相关的逻辑。还有一种情况,就是装载成功后,数据又发生了改变,这时需要重新再执行一遍装载过程,已经正确装载的数据可以被覆盖,但相同数据不能重复新增。简单的实现方式是先删除再插入,或者用replaceinto、mergeinto等类似功能的操作。装载到数据仓库里的数据,经过汇总、聚合等处理后交付给多维立方体或数据可视化、仪表盘等报表工具、BI工具做进一步的数据分析。



















 6178
6178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











