







回溯法
回溯算法与深度优先遍历
以下是维基百科中「回溯算法」和「深度优先遍历」的定义。
回溯法 采用试错的思想,它尝试分步的去解决一个问题。在分步解决问题的过程中,当它通过尝试发现现有的分步答案不能得到有效的正确的解答的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。回溯法通常用最简单的递归方法来实现,在反复重复上述的步骤后可能出现两种情况:
- 找到一个可能存在的正确的答案;
- 在尝试了所有可能的分步方法后宣告该问题没有答案。
深度优先搜索 算法(英语:Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法。这个算法会 尽可能深 的搜索树的分支。当结点 v 的所在边都己被探寻过,搜索将 回溯 到发现结点 v 的那条边的起始结点。这一过程一直进行到已发现从源结点可达的所有结点为止。如果还存在未被发现的结点,则选择其中一个作为源结点并重复以上过程,整个进程反复进行直到所有结点都被访问为止。
我刚开始学习「回溯算法」的时候觉得很抽象,一直不能理解为什么递归之后需要做和递归之前相同的逆向操作,在做了很多相关的问题以后,我发现其实「回溯算法」与「 深度优先遍历 」有着千丝万缕的联系。
个人理解
「回溯算法」与「深度优先遍历」都有「不撞南墙不回头」的意思。我个人的理解是:「回溯算法」强调了「深度优先遍历」思想的用途,用一个 不断变化 的变量,在尝试各种可能的过程中,搜索需要的结果。强调了 回退 操作对于搜索的合理性。而「深度优先遍历」强调一种遍历的思想,与之对应的遍历思想是「广度优先遍历」。至于广度优先遍历为什么没有成为强大的搜索算法,我们在题解后面会提。
在「力扣」第 51 题的题解《回溯算法(第 46 题 + 剪枝)》 中,展示了如何使用回溯算法搜索 44 皇后问题的一个解,相信对大家直观地理解「回溯算法」是有帮助。
搜索与遍历
我们每天使用的搜索引擎帮助我们在庞大的互联网上搜索信息。搜索引擎的「搜索」和「回溯搜索」算法里「搜索」的意思是一样的。
搜索问题的解,可以通过 遍历 实现。所以很多教程把「回溯算法」称为爆搜(暴力解法)。因此回溯算法用于 搜索一个问题的所有的解 ,通过深度优先遍历的思想实现。
与动态规划的区别
共同点
用于求解多阶段决策问题。多阶段决策问题即:
- 求解一个问题分为很多步骤(阶段);
- 每一个步骤(阶段)可以有多种选择。
不同点
动态规划只需要求我们评估最优解是多少,最优解对应的具体解是什么并不要求。因此很适合应用于评估一个方案的效果;
回溯算法可以搜索得到所有的方案(当然包括最优解),但是本质上它是一种遍历算法,时间复杂度很高。
从全排列问题开始理解回溯算法
我们尝试在纸上写 33 个数字、44 个数字、55 个数字的全排列,相信不难找到这样的方法。以数组 [1, 2, 3] 的全排列为例。
- 先写以 1 开头的全排列,它们是:[1, 2, 3], [1, 3, 2],即 1 + [2, 3] 的全排列(注意:递归结构体现在这里);
- 再写以 2 开头的全排列,它们是:[2, 1, 3], [2, 3, 1],即 2 + [1, 3] 的全排列;
- 最后写以 3 开头的全排列,它们是:[3, 1, 2], [3, 2, 1],即 3 + [1, 2] 的全排列。
总结搜索的方法:按顺序枚举每一位可能出现的情况,已经选择的数字在 当前 要选择的数字中不能出现。按照这种策略搜索就能够做到 不重不漏。这样的思路,可以用一个树形结构表示。
看到这里的朋友,建议先尝试自己画出「全排列」问题的树形结构。
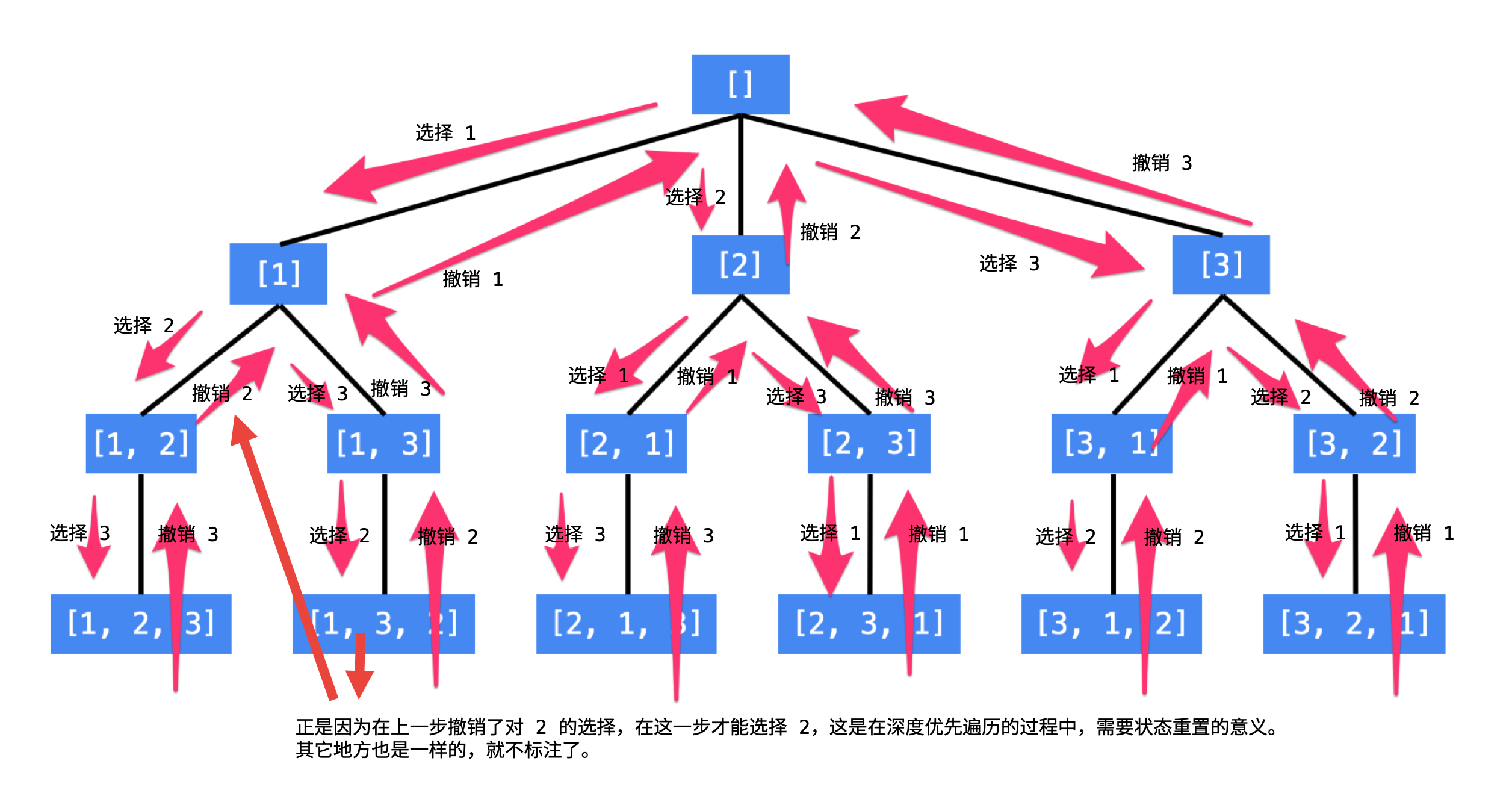
说明:
- 每一个结点表示了求解全排列问题的不同的阶段,这些阶段通过变量的「不同的值」体现,这些变量的不同的值,称之为「状态」;
- 使用深度优先遍历有「回头」的过程,在「回头」以后, 状态变量需要设置成为和先前一样 ,因此在回到上一层结点的过程中,需要撤销上一次的选择,这个操作称之为「状态重置」;
- 深度优先遍历,借助系统栈空间,保存所需要的状态变量,在编码中只需要注意遍历到相应的结点的时候,状态变量的值是正确的,具体的做法是:往下走一层的时候,path 变量在尾部追加,而往回走的时候,需要撤销上一次的选择,也是在尾部操作,因此 path 变量是一个栈;
- 深度优先遍历通过「回溯」操作,实现了全局使用一份状态变量的效果。
使用编程的方法得到全排列,就是在这样的一个树形结构中完成 遍历,从树的根结点到叶子结点形成的路径就是其中一个全排列。
设计状态变量
- 首先这棵树除了根结点和叶子结点以外,每一个结点做的事情其实是一样的,即:在已经选择了一些数的前提下,在剩下的还没有选择的数中,依次选择一个数,这显然是一个 递归 结构;
- 递归的终止条件是: 一个排列中的数字已经选够了 ,因此我们需要一个变量来表示当前程序递归到第几层,我们把这个变量叫做 depth,或者命名为 index ,表示当前要确定的是某个全排列中下标为 index 的那个数是多少;
- 布尔数组 used,初始化的时候都为 false 表示这些数还没有被选择,当我们选定一个数的时候,就将这个数组的相应位置设置为 true ,这样在考虑下一个位置的时候,就能够以 O(1)O(1) 的时间复杂度判断这个数是否被选择过,这是一种「以空间换时间」的思想。
这些变量称为「状态变量」,它们表示了在求解一个问题的时候所处的阶段。需要根据问题的场景设计合适的状态变量。
package 力扣;
import java.util.ArrayList;
import java.util.List;
class Solution {
public List<List<Integer>> permute(int[] nums) {
int len = nums.length;
// 使用一个动态数组保存所有可能的全排列
List<List<Integer>> res = new ArrayList<>();
if (len == 0) {
return res;
}
boolean[] used = new boolean[len];
List<Integer> path = new ArrayList<>();
dfs(nums, len, 0, path, used, res);
return res;
}
private void dfs(int[] nums, int len, int depth,
List<Integer> path, boolean[] used,
List<List<Integer>> res) {
if (depth == len) {
res.add(path);
return;
}
// 在非叶子结点处,产生不同的分支,这一操作的语义是:在还未选择的数中依次选择一个元素作为下一个位置的元素,这显然得通过一个循环实现。
for (int i = 0; i < len; i++) {
if (!used[i]) {
path.add(nums[i]);
used[i] = true;
dfs(nums, len, depth + 1, path, used, res);
// 注意:下面这两行代码发生 「回溯」,回溯发生在从 深层结点 回到 浅层结点 的过程,代码在形式上和递归之前是对称的
used[i] = false;
path.remove(path.size() - 1);
}
}
}
public static void main(String[] args) {
int[] nums = {1, 2, 3};
Solution solution = new Solution();
List<List<Integer>> lists = solution.permute(nums);
System.out.println(lists);
}
}
执行 main 方法以后输出如下:
[[], [], [], [], [], []]
原因出现在递归终止条件这里:
if (depth == len) {
res.add(path);
return;
}
变量 path 所指向的列表 在深度优先遍历的过程中只有一份 ,深度优先遍历完成以后,回到了根结点,成为空列表。
在 Java 中,参数传递是 值传递,对象类型变量在传参的过程中,复制的是变量的地址。这些地址被添加到 res 变量,但实际上指向的是同一块内存地址,因此我们会看到 66 个空的列表对象。解决的方法很简单,在 res.add(path); 这里做一次拷贝即可。
修改的部分:
if (depth == len) {
res.add(new ArrayList<>(path));
return;
}
剪枝
回溯算法会应用「剪枝」技巧达到以加快搜索速度。有些时候,需要做一些预处理工作(例如排序)才能达到剪枝的目的。预处理工作虽然也消耗时间,但能够剪枝节约的时间更多;
提示:剪枝是一种技巧,通常需要根据不同问题场景采用不同的剪枝策略,需要在做题的过程中不断总结。
由于回溯问题本身时间复杂度就很高,所以能用空间换时间就尽量使用空间。
总结
做题的时候,建议 先画树形图 ,画图能帮助我们想清楚递归结构,想清楚如何剪枝。拿题目中的示例,想一想人是怎么做的,一般这样下来,这棵递归树都不难画出。
在画图的过程中思考清楚:
分支如何产生;
题目需要的解在哪里?是在叶子结点、还是在非叶子结点、还是在从跟结点到叶子结点的路径?
哪些搜索会产生不需要的解的?例如:产生重复是什么原因,如果在浅层就知道这个分支不能产生需要的结果,应该提前剪枝,剪枝的条件是什么,代码怎么写?















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









