







本来我是想直接看moco的,但是我发现moco大量引用了这篇文章,所以就决定先看了这篇文章。
这是2018年CVPR的一篇文章,它是做对比学习的一篇文章 基于非参数实例判别的无监督特征学习。
概览
首先这篇文章的任务是做一个无监督的分类,也就是只考虑一个新来的图片是否类似于已有的某个图片(图片),而不考虑语义上它属于哪个分类。说白了也就是新来一张图像,它的特征和哪张现有图像的特征最像。提出了个体判别。
其次这篇文章用无监督的方法,重点在学习一个特征提取器,使得相似图片的特征更相关,不相关图片的特征更不相关。
第三,这篇文章提出了几种特别有名的方法,包括memory bank和noise-contrastive estimation(NCE)。
简介 - 个体判别

提出了个体判别任务,作者将每一张图片都看作是一个类别,希望模型可以学习图片的表征,从而把各种图片都区分出来。
InstDisc的工作是受到了有监督学习结果的启发,如果把豹子的图片喂给一个已经用有监督学习方式训练好的分类器,会发现它给出来的分类结果排名前几的全部都是跟豹子相关的(比如猎豹和雪豹),而排名靠后的判断往往是和豹子一点关系也没有的类别。
说明模型学习到的并不是语义标记,而是数据本身的相似使得某些类更为相近。简单的来说,他们就是长得像,他们就是得在一起。比如后面那些就是和原图片不像。
因此,作者将这种有监督的任务发挥到极致,提出了个体判别任务,作者将每一张图片都看作是一个类别,希望模型可以学习图片的表征,从而把各种图片都区分出来。
简介 - 模型
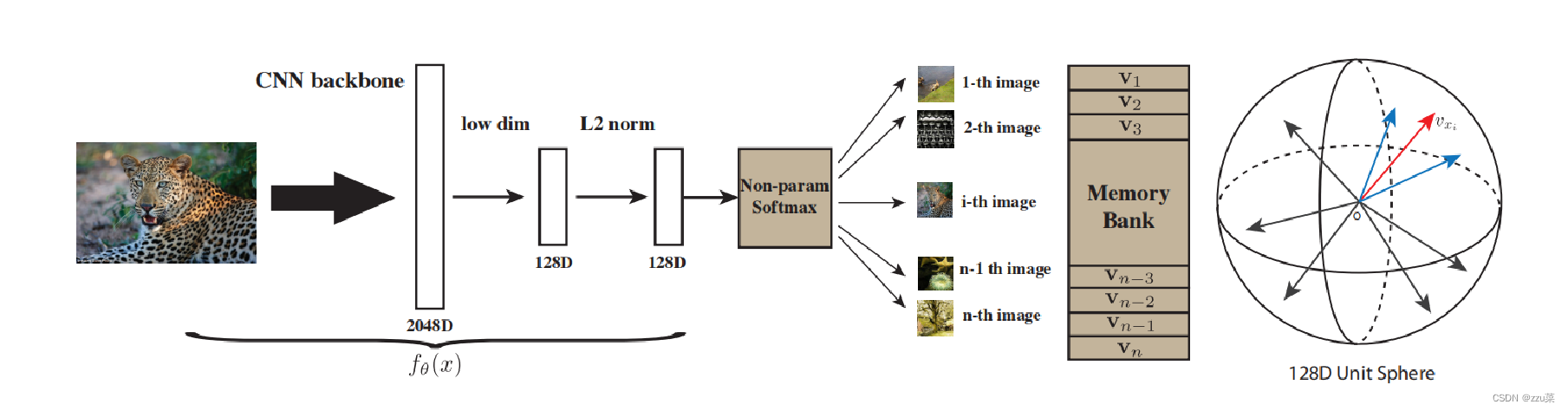
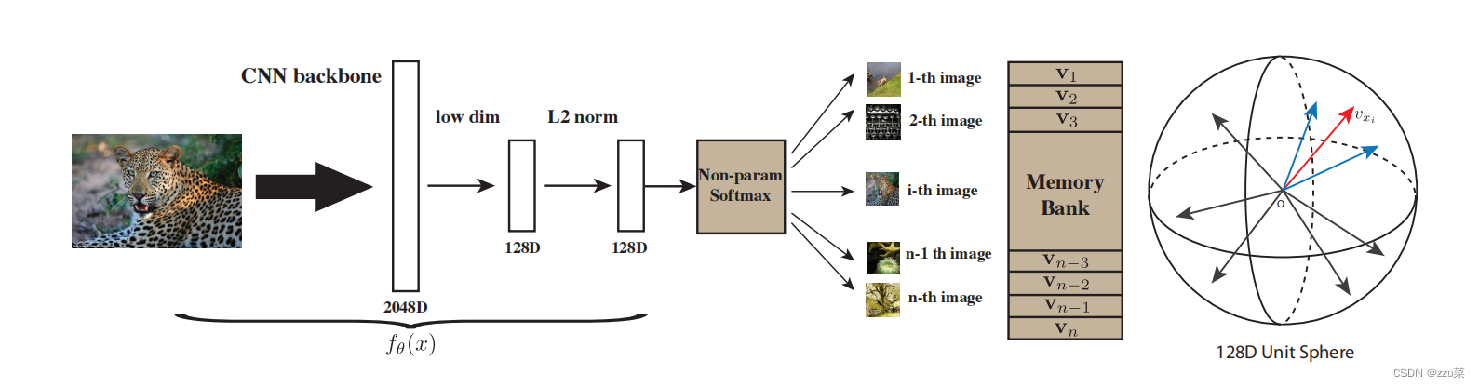
用无监督的方法,重点在学习一个特征提取器,使得相似图片的特征更相关,不相关图片的特征更不相关。
简单概括InstDisc的思想,通过一个卷积神经网络来将图片进行编码成一个低维特征,然后使得这些特征在特征空间上都尽可能的区分开,因为个体判别认为每张图片都是自成一类。
训练这个神经网络的方法是对比学习,所以需要有正样本,需要有负样本。正样本就是图像本身,可能经过数据增强,负样本就是数据集中其余的所有图片的特征,该文章使用一个memroy bank存储这些负样本,imagenet中有128w的数据,意味着memory bank有128w行,因为负样本太多了,如果使用较高的维度表示图片的话,对于负样本的存储代价过高,因此作者让向量维度为128维。
简单的走一下这个前向传播的过程,假设模型的batchsize是256,有256张图片进入CNN网络,将256张图片编码为128维的向量。因为batchsize是256,因此有256个正样本。负样本来自memory bank,每次从memory bank中随机采样出4096个负数样本,利用infoNCE loss去更新CNN的参数。本次更新结束后,会将CNN编码得到的向量替换掉memory bank中原有的存储。就这样循环往复的更新CNN和memory bank,最后让模型收敛,就训练好一个CNN encoder了。
方法 - Non-Parametric Softmax Classifie
背景:
目标是无需监督信息学习一个特征映射:
v
=
f
θ
(
x
)
v = f_θ (x)
v=fθ(x)是以θ为参数的卷积神经网络,将图片 x 映射成特征 v ,维度为 d。
这里讲作者在模型中所采用的的方法 - 无参数softmax分类器。
这里先说一下背景,也就是上一张模型图的输入 图片为 x 经过 函数f 输出 特征v。
下面是个softmax原理图,其实也就是归一化实现多分类。
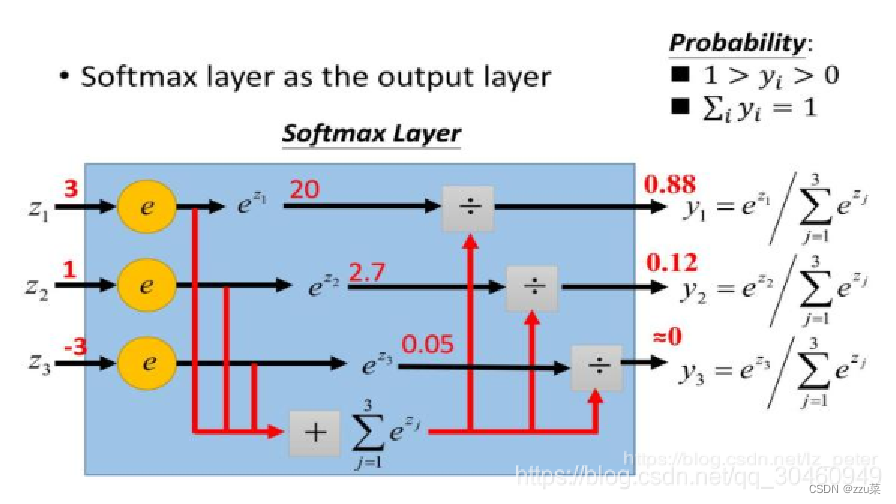
有参数的 softmax 分类器 ,参数指的是类别个数 n(注意这里每张图片是一类,图片数量多时参数过多,ImageNet 120w)
假设我们有n个图像
x
1
,
…
,
x
n
x_1,…, x_n
x1,…,xn在n个类中,以及它们的特性
v
1
,
…
,
v
n
v_1,…, v_n
v1,…,vn,
v
i
=
f
θ
(
x
i
)
v_i = f_θ(x_i)
vi=fθ(xi)在常规参数softmax公式下,对于特征
v
=
f
θ
(
x
)
v = f_θ(x)
v=fθ(x)的图像x,作为第i个图片被识别的概率为
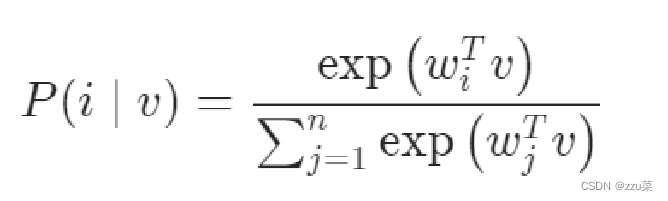
全连接层: W d ∗ n W^{d∗n} Wd∗n
W
i
T
v
W_i^Tv
WiTv 表示v和第i类图片的相似程度。
假设特征维度是128,图片数目为120万,这一层的参数数目超过15亿。
由于上面提到的问题,本文的作者提出了无参softmax分类器。
研究者们提出了非参数的公式:用
v
j
T
v
v_j^Tv
vjTv取代
w
j
T
v
w_j^Tv
wjTv。并且通过L2正则化使得∥ v ∥ = 1(是为了让向量v分布在半径为1的球面上)
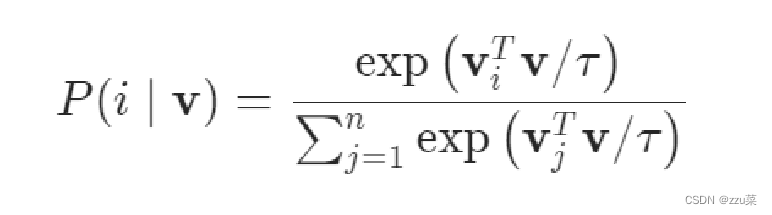
,这里比较的是 v i v_i vi和 v v v之间的匹配程序. vi是memory bank里面存储的特征 v是通过 函数f 出来的特征
τ是个温度参数 控制分布的集中程度。
下面那个就是目标函数,最小化。
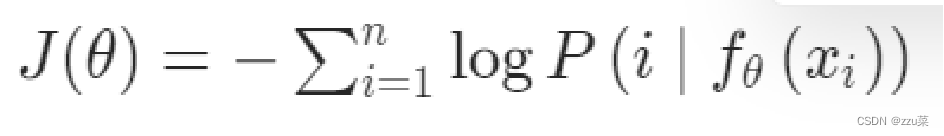
我们的非参数公式消除了计算和存储{wj}梯度的需要
方法 - Noise-Contrastive Estimation Computing
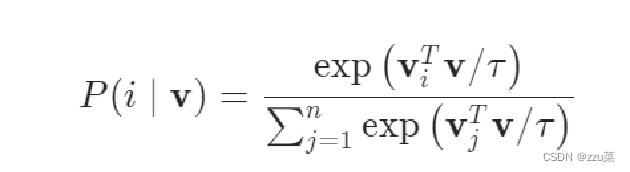
虽然我们使用了无参构造器的方法,但是当类n的数量非常大时,例如在数百万的规模下,计算非参数softmax的成本是令人望而却步的。
我们采用NCE来近似完整的softmax分布,为了解决计算训练集中所有实例的相似度的困难。研究人员将多分类任务转化为一系列二分类任务,二分类任务是判断样本是来自于真实数据还是噪声数据。
由于该方法把每一张图片都看成一个类别,每次训练的时候都要把所有图片都遍历一遍,很耗费时间,所以作者不遍历所有图片,只遍历m张,这m张是在除这张图片外所有图片中随意抽取。最后m取了4096。
下面那个公式表示 样本i来自与真实样本分布的概率为:
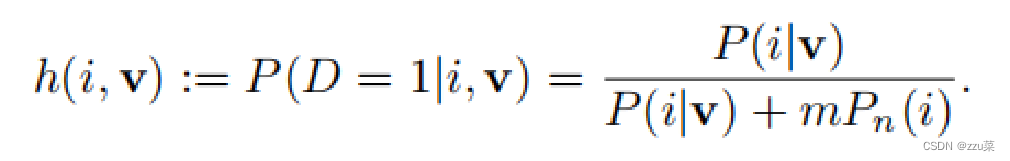
其目标函数为:
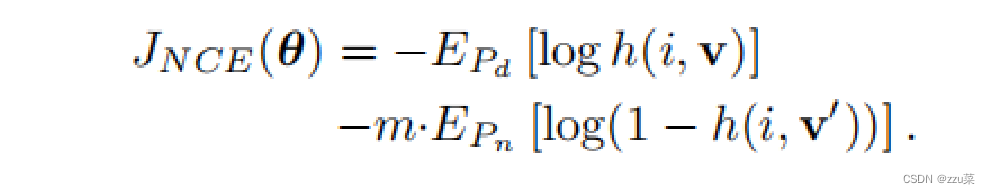
方法 - Proximal Regularization
近似正则化 给模型的训练增加了一个约束,从而可以让memory bank里面的特征进行动量式更新,保持一致性。
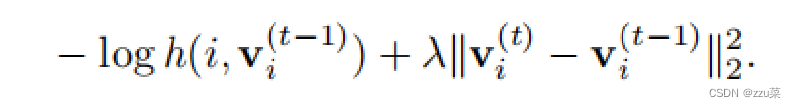
我的每个类只有一个实例.在每个训练epoch中,每类样本仅出现一次,训练过程由于随机采样的波动而震荡,我们采取如下的正则项保证训练过程的稳定,在当前迭代t,
x
i
x_{i}
xi
去保证训练过程的稳定.当学习收敛时,迭代之间的差异
v
i
(
t
)
−
v
i
(
t
−
1
)
v_i^{( t )}-v_i^{( t-1 )}
vi(t)−vi(t−1)逐渐消失,增加的损失减少到原来的损失。随着训练收敛,两次迭代过程中的特征差异也随之减少,最终的损失函数为:
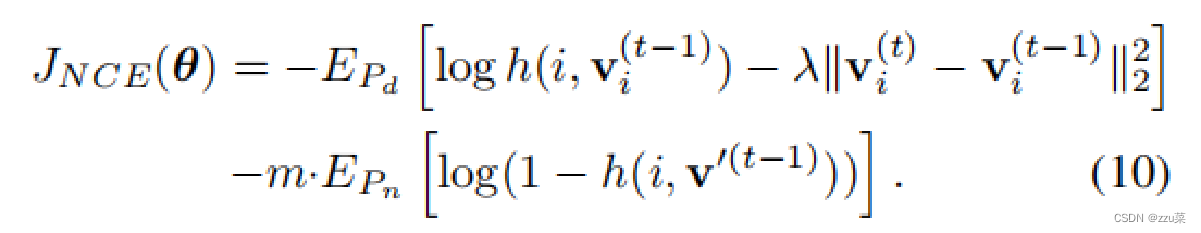
方法 - Proximal Regularization
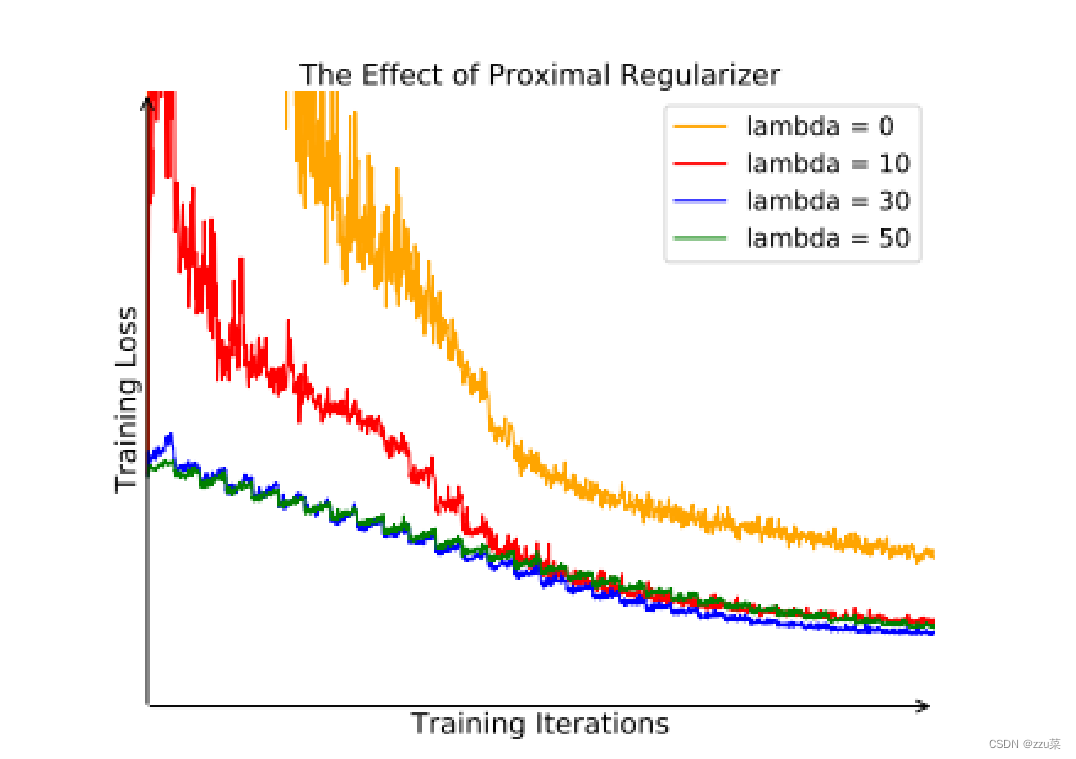
横坐标是训练迭代次数 纵坐标是训练损失
可以明显看出lambda = 0是波动较大 且训练效果不好
说明加入的lambda是有效的
实验 - Parametric vs. Non-parametric Softmax
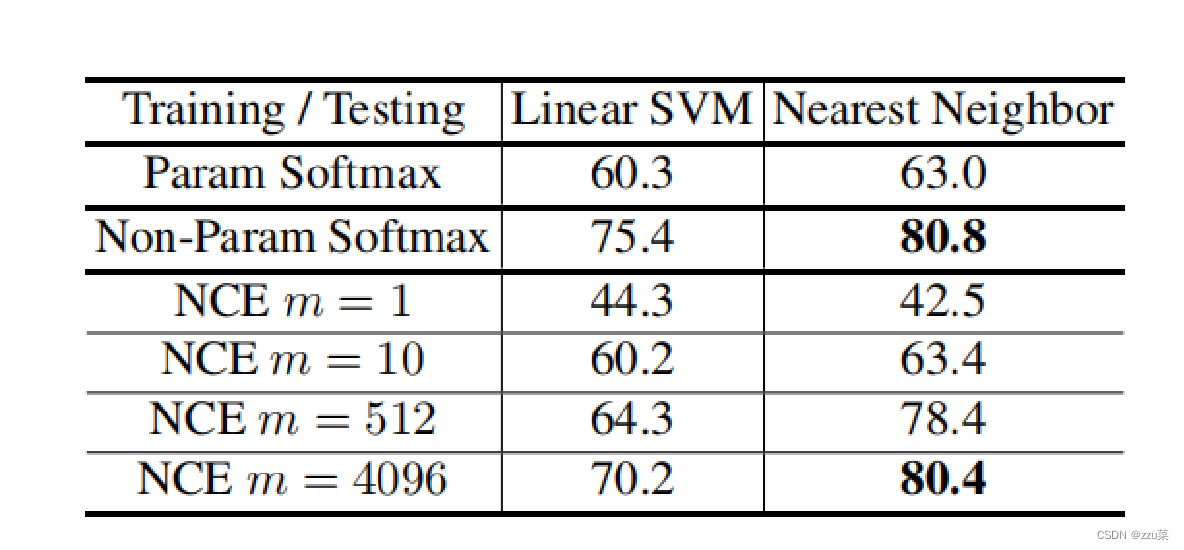
本文的一个关键的新颖性是非参数的softmax分类。我们比较了CIFAR-10上的参数化和非参数化形式,这是一个包含10个类中的50,000个训练实例的数据集。这个大小允许我们在不使用任何近似的情况下计算式(2)中的非参数的softmax。我们使用ResNet18作为骨干网络,其输出特征映射到128维向量.
通过在学习到的特征上应用线性 SVM 或 kNN 分类器在 CIFAR10 的 Top-1 准确率。本文提出的非参数化的 softmax 优于参数化的 softmax,并且用 NCE 方法 得到的准确率随 m 单调递增。
实验 - Image Classification
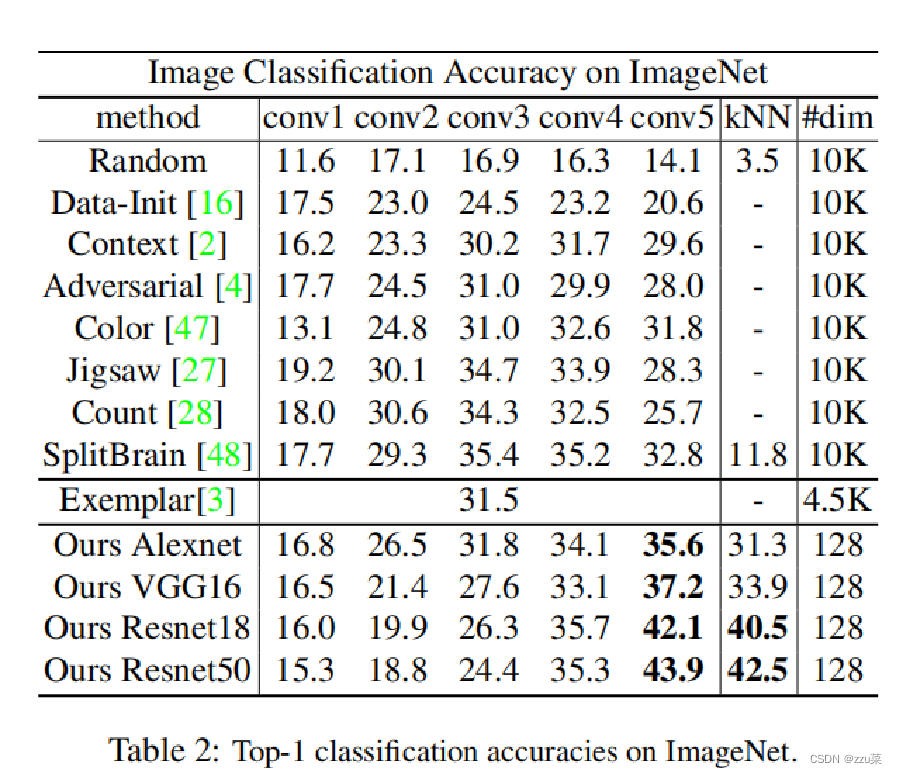
两种不同的标准评估性能:
1)对从 conv1 到 conv5 的中间特征运行线性 SVM。
2)对输出特征运行 kNN。
研究者将他们的方法与随机初始化的网络(作为下界)及各种无监督学习方法进行了比较,包括自监督学习 [2,47,27,48]、对抗学习 [4] 和 Exemplar CNN [3]。split-brain 自编码器 [48] 提供代表当前最佳水平的强大基线。
Feature generalization
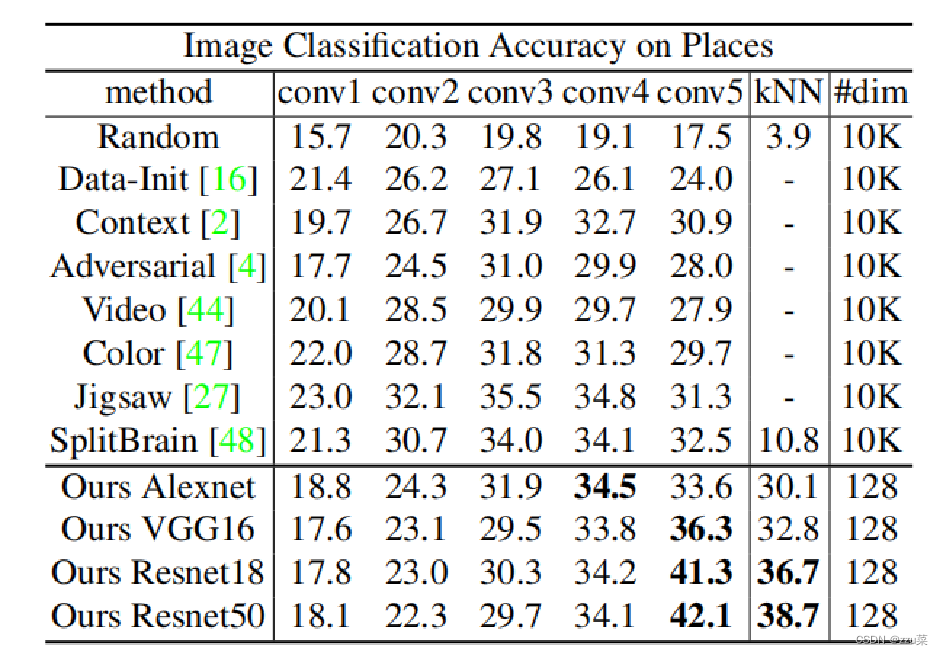
我们还研究了如何将学习到的特征表示推广到其他数据集。结果表明,该方法具有较强的泛化能力。直接基于在 ImageNet 上学习特征的、没有微调的在 Places 上的 Top-1 分类准确率。
The embedding feature size.

接着作者又讨论了特征的维度对准确性的影响,从32到256时,性能是如何变化的。表4显示,性能从32增加到128,趋于饱和,接近256。
Training set size.

讨论了数据集的大小对无监督学习的影响,明显可以看出特征学习方法受益于更大的训练集,并且随着训练集的增长,测试的准确性也会提高。这个特性对于成功的无监督学习是至关重要的.

为了说明所学习的特征,图显示了使用所学习的特征进行图像检索的结果。前四行显示了最好的情况.所有前10个结果都与查询属于相同的类别。下面四行显示的是最糟糕的情况,前10名都不在同一类别中。然而,即使在失败的情况下,检索到的图像仍然与查询非常相似,这证明了的非监督学习目标的有效性.















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









