







✨ 1: ChatTTS-Nuxt3 Webui
ChatTTS-Nuxt3 WebUI是基于ChatTTS开发的文本转语音Web应用,支持详细参数调整和移动视图。
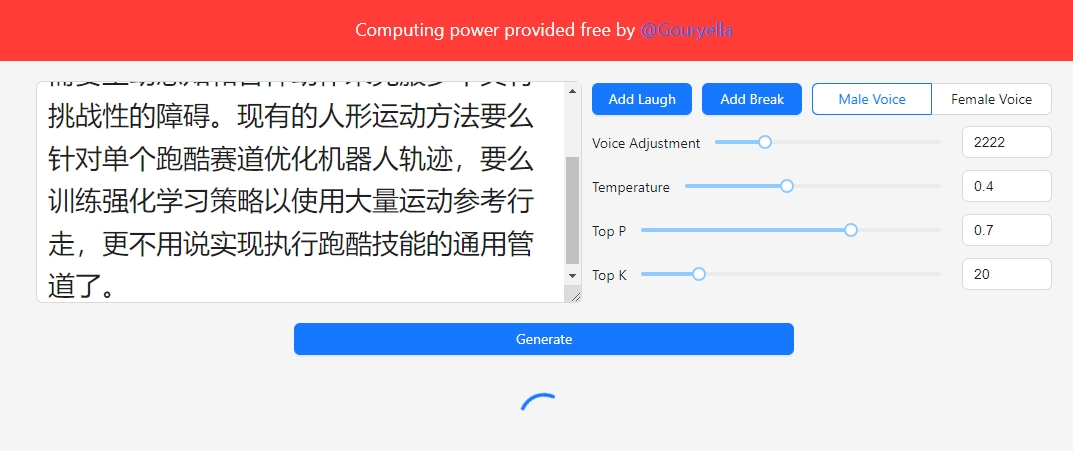
ChatTTS-Nuxt3 Webui 基于 ChatTTS 项目开发,由 @2noise 创建,WebUI 开发则由 @Gouryella 完成。你可以在 这里 免费试用该项目。
适合在:
将文本转换为自然流畅的语音,非常适用于语音助手、智能音箱等场景。
提供高质量的语音输出,帮助语言学习者通过听觉学习,提高听力和口语能力。
地址:https://github.com/Gouryella/ChatTTS-webui
✨ 2: Draw2Img
Draw2Img 是一个简单的网页界面工具,用于基于文本指导的图像生成,适合任何年龄和技能水平。

Draw2Img 是一个简单的 Web 用户界面,用于互动式的文本引导图像生成,适合任何年龄和技能水平的用户。该工具通过用户输入的文本来生成相应的图像,操作直观,使用便捷。
Draw2Img 项目完全开源,任何人均可贡献代码或提出改进意见。在使用过程中,请注意监督儿童,防止生成不适内容。
地址:https://github.com/GradientSurfer/Draw2Img
✨ 3: Groqbook
Groqbook是一款使用Groq和Llama3在几秒内生成整本书的streamlit应用。
Groqbook 是一个基于 Streamlit 的应用,利用 Groq 和 Llama3 模型,能够从一句提示中生成整本书。针对非小说类书籍,Groqbook 能在几秒内完成每一章的生成。该应用通过 Llama3-8b 和 Llama3-70b 两种模型的协作,使用较大模型生成书籍结构,较小模型生成内容。目前,模型仅使用章节标题的上下文生成内容,未来将扩展至整本书的上下文,以便生成高质量的小说类书籍。
地址:https://github.com/Bklieger/groqbook
✨ 4: MusePose
MusePose是一个通过图像生成受控信号虚拟人视频的框架。
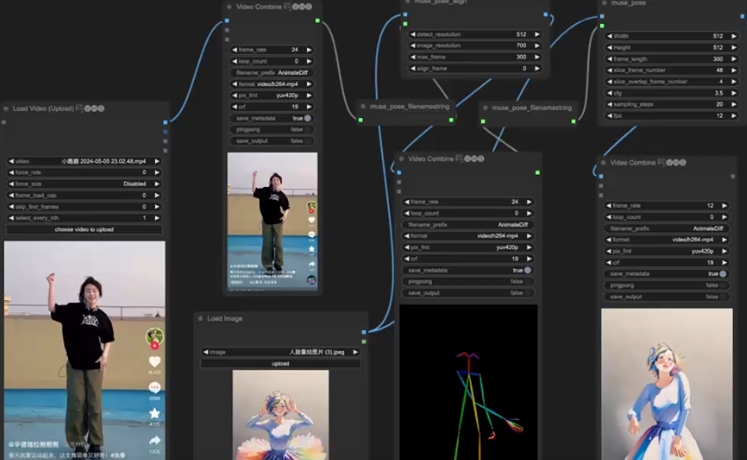
MusePose 是一个基于图像生成视频的框架,专为在控制信号(如姿态)下生成虚拟人类而设计。MusePose 是 Muse 开源系列的最后一个组成部分。结合 MuseV 和 MuseTalk,该系列旨在实现从端到端生成具备全身动作和交互能力的虚拟人类。我们希望社区能和我们一起向这个愿景迈进,并期待我们的下一个里程碑!
地址:https://github.com/TMElyralab/Comfyui-MusePose
✨ 5: FRIDA
FRIDA是一个协作机器人画家,可以根据语言描述或图像在画布上作画。
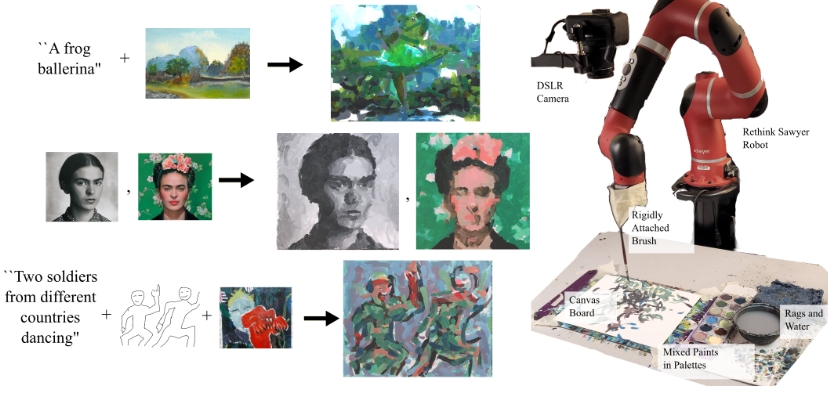
FRIDA(Framework and Robotics Initiative for Developing Arts)是由卡内基梅隆大学的机器人研究所开发的一个协作机器人画家系统,旨在通过与人类合作完成画作。人类用户只需提供简单的输入,如语言描述或图像,FRIDA 就能够生成相应的绘画。FRIDA 使用一个完全可微分的模拟环境来进行绘画,采用了从现实到模拟再回到现实(real2sim2real)的理念,从而可以计划并动态应对执行计划中的随机性。
地址:https://github.com/cmubig/Frida
更多AI工具,参考国内AiBard123,Github-AiBard123 公众号:每日AI新工具
















 1564
1564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











