







awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本号: awk、nawk和gawk,未作特别说明,一般指gawk。
awk程序的报告生成能力通经常使用来从大文本文件里提取数据元素并将它们格式化成可读的报告。最完美的样例是格式化日志文件。
awk的用法
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
第一步:运行BEGIN{ commands }语句块中的语句。
第二步:从文件或标准输入(stdin)读取一行。然后运行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行反复这个过程。直到文件所有被读取完成。
第三步:当读至输入流末尾时。运行END{ commands }语句块。
BEGIN语句块在awk開始从输入流中读取行之前被运行,这是一个可选的语句块,比方变量初始化、打印输出表格的表头等语句通常能够写在BEGIN语句块中。
END语句块在awk从输入流中读取全然部的行之后即被运行。比方打印全部行的分析结果这类信息汇总都是在END语句块中完毕,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,它也是可选的。假设没有提供pattern语句块,则默认运行{ print },即打印每个读取到的行。awk读取的每一行都会运行该语句块。
这三个部分缺少任何一部分都可以。
内建变量
列出某个目录的文件:
[root@localhost profile.d]# ls -lh
total 136K
-rwxr-xr-x 1 root root 766 Jul 22 2011 colorls.csh
-rwxr-xr-x 1 root root 727 Jul 22 2011 colorls.sh
-rw-r--r-- 1 root root 92 Feb 23 2012 cvs.csh
-rwxr-xr-x 1 root root 78 Feb 23 2012 cvs.sh
-rwxr-xr-x 1 root root 192 Mar 25 2009 glib2.csh
-rwxr-xr-x 1 root root 192 Mar 25 2009 glib2.sh
-rw-r--r-- 1 root root 218 Jun 6 2013 krb5-devel.csh
-rw-r--r-- 1 root root 229 Jun 6 2013 krb5-devel.sh
-rw-r--r-- 1 root root 218 Jun 6 2013 krb5-workstation.csh
-rw-r--r-- 1 root root 229 Jun 6 2013 krb5-workstation.sh
-rwxr-xr-x 1 root root 3.0K Feb 22 2012 lang.csh
-rwxr-xr-x 1 root root 3.4K Feb 22 2012 lang.sh
-rwxr-xr-x 1 root root 122 Feb 23 2012 less.csh
-rwxr-xr-x 1 root root 108 Feb 23 2012 less.sh
-rwxr-xr-x 1 root root 97 Mar 6 2011 vim.csh
-rwxr-xr-x 1 root root 293 Mar 6 2011 vim.sh
-rwxr-xr-x 1 root root 170 Jan 7 2007 which-2.sh
试一下awk的使用
ls -lh | awk '{print $1}'
在这里awk 后面没有BEGIN和END,跟着的是pattern,也就是每一行都会经过这个命令,在awk中$n,表示第几列,在这里表示打印每一行的第一列。
- $0 当前记录(这个变量中存放着整个行的内容)
- 1 n 当前记录的第n个字段,字段间由FS分隔
- FS 输入字段分隔符 默认是空格或Tab
- NF 当前记录中的字段个数,就是有多少列
- NR 已经读出的记录数,就是行号,从1开始,如果有多个文件话,这个值也是不断累加中。
- FNR 当前记录数,与NR不同的是,这个值会是各个文件自己的行号
- RS 输入的记录分隔符, 默认为换行符
- OFS 输出字段分隔符, 默认也是空格
- ORS 输出的记录分隔符,默认为换行符
- FILENAME 当前输入文件的名字
如打印每一行的行数:
[root@localhost profile.d]# ls -lh | awk '{print NR " " $1}'
1 total
2 -rwxr-xr-x
3 -rwxr-xr-x
4 -rw-r--r--
5 -rwxr-xr-x
6 -rwxr-xr-x
7 -rwxr-xr-x
8 -rw-r--r--
9 -rw-r--r--
10 -rw-r--r--
11 -rw-r--r--
12 -rwxr-xr-x
13 -rwxr-xr-x
14 -rwxr-xr-x
15 -rwxr-xr-x
16 -rwxr-xr-x
17 -rwxr-xr-x
18 -rwxr-xr-x
这样再来看这段语句应该就很容易理解了:
root@ubuntu:~# awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenumber:2,columns:7,linecontent:daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/usr/sbin/nologin
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/usr/sbin/nologin
filename:/etc/passwd,linenumber:5,columns:7,linecontent:sync:x:4:65534:sync:/bin:/bin/sync
filename:/etc/passwd,linenumber:6,columns:7,linecontent:games:x:5:60:games:/usr/games:/usr/sbin/nologin
变量
除了awk的内置变量,awk还可以自定义变量。
如下引入变量sum,统计py文件的大小:
root@ubuntu:~# ls -l *.py | awk '{sum+=$5} END {print sum}'
574
语句
awk中的条件语句是从C语言中借鉴来的,见如下声明方式:
if语句
if (expression) {
statement;
statement;
... ...
}
if (expression) {
statement;
} else {
statement2;
}
if (expression) {
statement1;
} else if (expression1) {
statement2;
} else {
statement3;
}
循环语句
awk中的循环语句同样借鉴于C语言,支持while、do/while、for、break、continue,这些关键字的语义和C语言中的语义完全相同。
数组
因为awk中数组的下标可以是数字和字母,数组的下标通常被称为关键字(key)。值和关键字都存储在内部的一张针对key/value应用hash的表格里。由于hash不是顺序存储,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等。
使用数组,统计重复出现的次数:
[root@localhost cc]# cat test.txt
a 00
b 01
c 00
d 02
[root@localhost cc]# awk '{sum[$2]+=1}END{for(i in sum)print i"\t"sum[i]}' test.txt
00 2
01 1
02 1
站点日志分析
以下使用Linux中的Awk对tomcat中日志文件做一些分析,主要统计pv,uv等。
日志文名称:access_2013_05_30.log,大小57.7 MB 。
这次分析仅仅是简单演示,所以不是太精确地处理数据。
日志地址:http://download.csdn.net/detail/u011204847/9496357
日志数据演示样例:
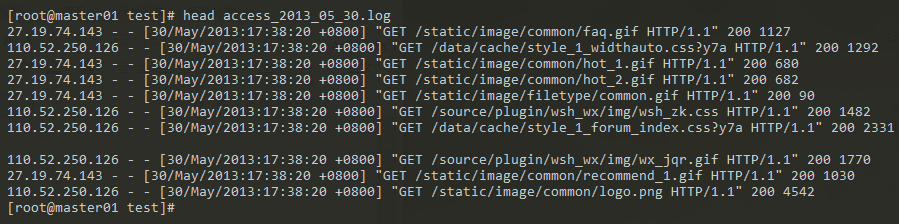
日志总行数:

打印的第七列数据为日志的URL:
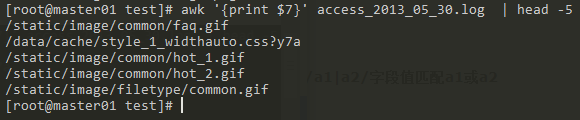
分析中用到的一些知识:
shell中的管道|
command 1 | command 2 #他的功能是把第一个命令command 1运行的结果作为command 2的输入传给command 2wc -l #统计行数
uniq -c #在输出行前面加上每行在输入文件里出现的次数
uniq -u #仅显示不反复的行
sort -nr
-n:按照数值的大小排序
-r:以相反的顺序来排序
-k:按照哪一列进行排序head -3 #取前三名
数据清洗:
1、第一次清洗:去除URL中以/static/开头的URL
awk '($7 !~ /^\/static\//){print $0}' access_2013_05_30.log > clean_2013_05_30.log
去除前:

去除后:

2、第二次清洗:去除图片、css和js
awk '($7 !~ /\.jpg|\.png|\.jpeg|\.gif|\.css|\.js/) {print $0}' clean_2013_05_30.log > clean2_201 3_05_30.log

PV
pv是指网页訪问次数
方法:统计全部数据的总行数
数据清洗:对原始数据中的干扰数据进行过滤
awk 'BEGIN{pv=0}{pv++}END{print "pv:"pv}' clean2_2013_05_30.log > pv_2013_05_30

UV
uv指的是訪问人数。也就是独立IP数
对ip反复的数据进行去重,然后再统计全部行数
awk ‘{print $1}’ clean2_2013_05_30.log |sort -n |uniq -u |wc -l > uv_2013_05_30

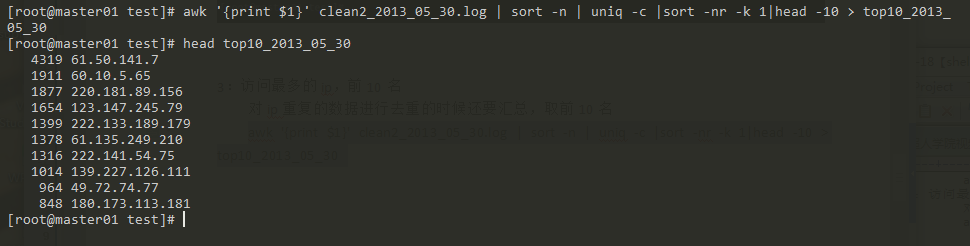
訪问最多的IP(前10名)
对ip反复的数据进行去重的时候还要汇总,取前10名
awk '{print $1}' clean2_2013_05_30.log | sort -n | uniq -c |sort -nr -k 1|head -10 > top10_2013_05_30
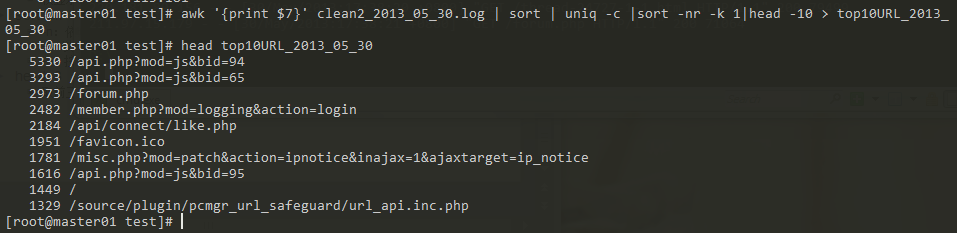
訪问前十的URL(能够用来分析站点哪个模块最受欢迎)
awk '{print $7}' clean2_2013_05_30.log | sort | uniq -c |sort -nr -k 1|head -10 > top10URL_2013_ 05_30
更多教程:阿猫学编程



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











