






# Diffusion4D
首个4D视频生成扩散模型!Diffusion4D数分钟内实现4D内容生成,超81K的4D数据集已开源
本文介绍由多伦多大学,北京交通大学,德克萨斯大学奥斯汀分校和剑桥大学团队最新提出的4D生成扩散模型,该方法可以在几分钟之内可以完成时空一致的4D内容生成。
Diffusion4D(Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models)整理筛选了约81K个4D assets,利用8卡GPU共16线程,花费超过30天渲染得到了约四百万张图片,包括静态3D物体环拍、动态3D物体环拍以及动态3D物体前景视频。
该方法是首个利用大规模数据集,训练视频生成模型生成4D内容的框架,目前项目已经开源所有渲染的4D数据集以及渲染脚本。
- 项目地址:https://vita-group.github.io/Diffusion4D/
- 论文地址:https://arxiv.org/abs/2405.16645
一、 研究背景
过去的方法采用了2D、3D预训练模型在4D(动态3D)内容生成上取得了一定的突破,但他们主要依赖于分数蒸馏采样(SDS)或者生成的伪标签进行优化,同时利用多个预训练模型获得监督不可避免的导致时空上的不一致性以及优化速度慢的问题。
4D内容生成的一致性包含了时间上和空间上的一致性,它们分别在视频生成模型和多视图生成模型中被探索过。基于这个洞见,Diffusion4D将时空的一致性嵌入在一个模型中,并且一次性获得多时间戳的跨视角监督。
具体来说,使用仔细收集筛选的高质量4D数据集,Diffusion4D训练了一个可以生成动态3D物体环拍视图的扩散模型,而后利用已有的4DGS算法得到显性的4D表征,该方法实现了基于文本、单张图像、3D到4D内容的生成。
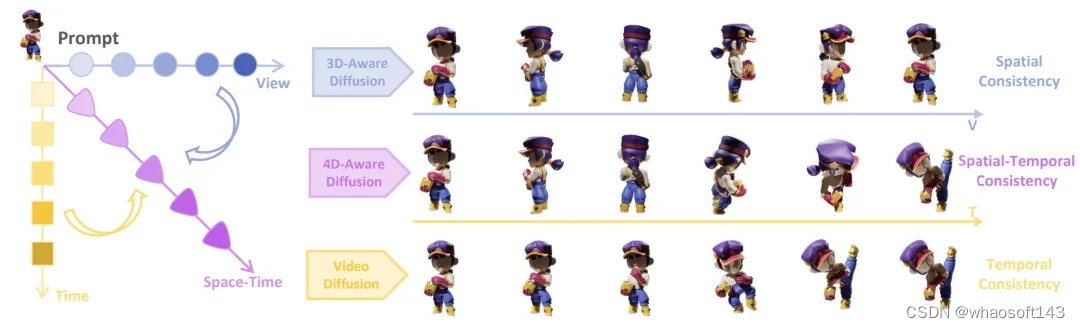
二、 4D数据集
为了训练4D视频扩散模型,Diffusion4D收集筛选了高质量的4D数据集。已开源的Objaverse-1.0包含了42K运动的3D物体,在Objaverse-xl中包含323K动态3D物体。然而这些数据包含着大量低质量的样本,研究者们设计了运动程度检测、边界溢出检查等筛选方法,选取了共81K的高质量4D资产。
对于每一个4D资产,渲染得到了24个静态视角的图(上图第一行),24个动态视角的环拍图(上图第二行),以及24个正面动态图(上图第三行)。总计得到了超过四百万张图片,总渲染消耗约300 GPU天。其他数据集细节可以参考项目主页,目前所有渲染完的数据集和原始渲染脚本已开源,更多数据集使用方法值得探索!
三、 方法
有了4D数据集之后,Diffusion4D训练具有4D感知的视频扩散模型(4D-aware video diffusion model)。
过去的视频生成模型通常不具备3D几何先验信息,但近期工作如SV3D,VideoMV等探索了利用视频生成模型得到静态3D物体的多视图,因此Diffusion4D选用了VideoMV作为基础模型进行微调训练,使得模型能够输出动态环拍视频。
此外设计了如运动强度(motion magnitude)控制模块、3D-aware classifier-free guidance等模块增强运动程度和几何质量。得益于视频模态具备更强的连贯性优势,输出的结果具有很强的时空一致性。
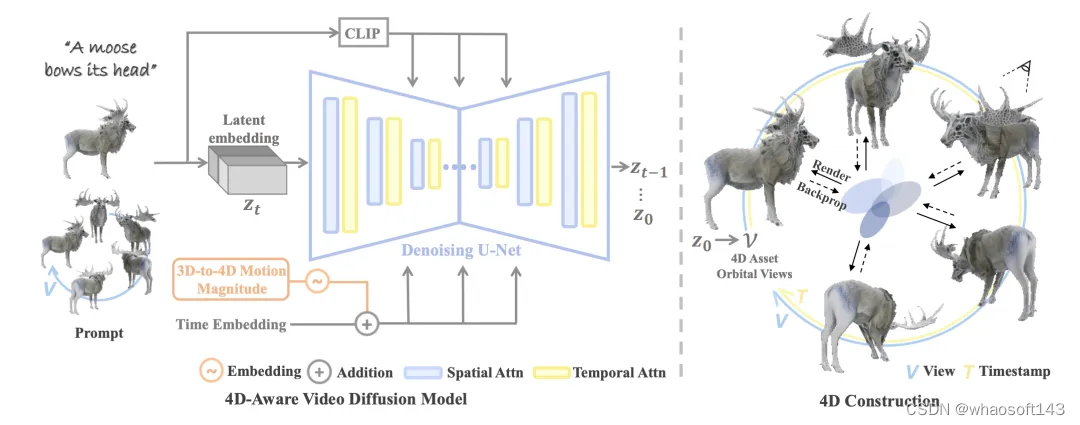
输出得到动态视角环拍视频后,Diffusion4D借助已有的4D重建算法将视频建模得到4D表达。具体来说采用了4DGS的表征形式,以及使用粗粒度、细粒度的两阶段优化策略得到最终的4D内容。从生产环拍视频到重建4D内容的两个步骤仅需花费数分钟时间,显著快于过去需要数小时的借助SDS的优化式方法。
四、 结果
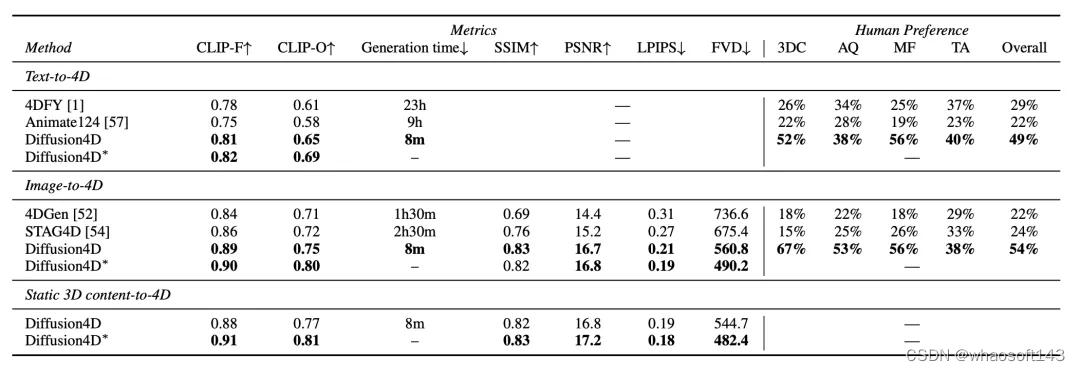
根据提示信息的模态,Diffusion4D可以实现从文本、图像、3D到4D内容的生成,在定量指标和user study上显著优于过往方法。在生成质量上,Diffusion4D有着更好的细节,更为合理的几何信息以及更丰富的动作。更多可视化结果可以参考项目主页。
五、 总结
Diffusion4D是首个利用视频生成模型来实现4D内容生成的框架,通过使用超81K的数据集、以及精心设计的模型架构实现了快速且高质量的4D内容。未来,如何最大程度发挥4D数据集价值,如何生成多物体、复杂场景的4D内容仍有很大的探索空间!
# 2024国际计算机视觉与模式识别会议
视觉 AI 的「Foundation Model」,已经发展到哪一步?丨CVPR 2024 现场直击
“CV 的未来是什么景象,斗胆预测(或者是一种希望)未来将 from ‘virtual’ to ‘physical’,可能以各种不同的形式。”
2024 年美国时间 6 月 17 日至 21 日,IEEE 国际计算机视觉与模式识别会议(CVPR)在美国西雅图召开。
如大家预料,视觉 Foundation Model 成为今年 CVPR 除自动驾驶、3D 视觉等传统研究课题以外的核心会议主题。
此外,由于会议召开前后,国内快手「可灵」开放图生视频功能火爆出圈、Runway 时隔一年推出新模型 Gen-3 Alpha,文生视频也成为 CVPR 2024 的一大热词。
今年, CVPR 的两篇最佳论文都颁给了 AIGC。从论文接收数量的角度看,图像和视频合成与生成(Image and video synthesis and generation)以329 篇论文成功占据榜首。而文生视频也属于视觉 Foundation Model 的研究讨论范畴。
事实上,Foundation Model 在人工智能领域的最早出圈就是在计算机视觉领域。
2021 年 8 月,斯坦福大学百位学者联名发表 Foundation Model 综述,作者队列里就有多位计算机视觉领域的翘楚,如李飞飞、Percy Liang 等。但OpenAI 凭借一己之力,在自然语言处理领域的 Foundation Model 上率先弯道超车,通过堆参数量与拼算力,将语言大模型做到极致,语言基座模型的风头也在 2023 年一度盖过了视觉基座模型。
然而,由于 Sora 与可灵等工作的炫丽效果,CV 领域内关于视觉「Foundation Model」的话题又重回牌桌。
在 CVPR 2024 的大会现场,AI 科技评论走访了多位从事过视觉基座模型的研究者,试图求解在现阶段领域内的专家人士如何看待「Foundation Model」。
我们发现:
- 视觉 Foundation Model 的研究思路也借鉴 OpenAI 的路线,将下一步重要突破放在如预测下一个 visual token、扩大算力规模等思路上;
- 不止一位研究者认为,无论是语言还是视觉,Foundation Model 的概念崛起后,AI 已经从一个开放的研究问题变成了一条实实在在的「工业生产线」,研究员的目标只有两个——「搞数据」与「搞算力」;
- 「多模态」成为视觉基础模型研究的一门显学,但视觉与语言两派的合作通道仍未有效建立。
除了 Foundation Model,我们也访谈了自动驾驶、3D 视觉领域的相关人士。我们也发现,诸如 CVPR 等从论文接收截止到会议召开时间长度跨越半年的学术会议,或许已不再适用于跟踪如今变化万象、日新月异的研究成果。
当 AI 研究中工业界与产业界的隔阂越来越小、融合越来越多时,哪怕是一个传统的学术会议也要有跟上时代潮流的意识。
1 「Foundation Model」 的瓶颈与突破
事实上,基于 Transformer 开发通用的视觉基础模型并不是 2023 年 ChatGPT 火起来后才有的研究思路。
国外从微软 Swin Tranformer 到谷歌 ViT,再到国内上海人工智能实验室的「书生」(Intern)系列,都很早开始了通用视觉智能的探索。只不过与 BERT 被 GPT-3 碾压的命运一样,它们都被后来出现的 Sora 光芒掩盖;同时,由于 Sora 的技术路径独辟蹊径,也开始学习 Sora、借鉴 Sora。
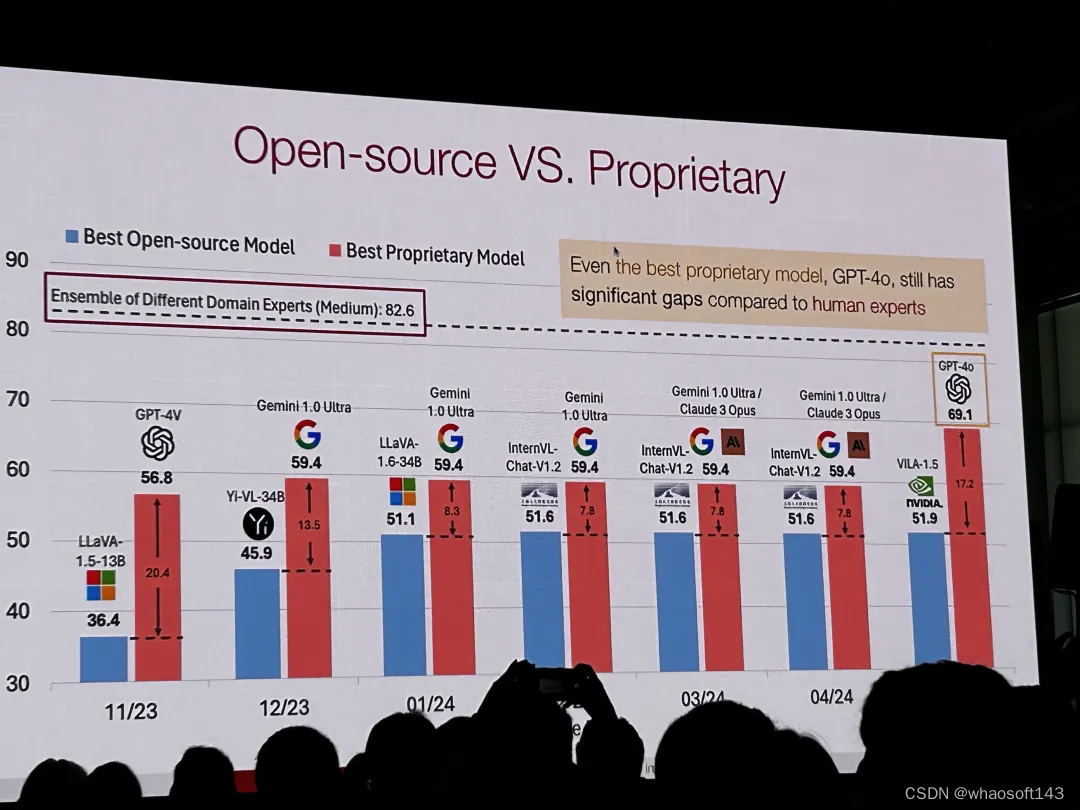
在今年的 CVPR 上,上海人工智能实验室的通用视觉团队(OpenGVLab)展示了他们最新的视觉多模态基础模型研究成果 InternVL-1.5。该工作凭借强大的视觉编码器 InternViT-6B、高动态分辨率,以及高质量双语数据集,在业内广受追捧。CMU、面壁智能等国内外的多个开源对比数据也表示,InternVL 的效果名列前茅:
上海人工智能实验室OpenGVLab「书生」多模态大模型团队认为,视觉基础模型区别于以往工作的一个直接体现是多模态对话系统的构建。
InternVL-26B 的研究始于 2023 年 3 月。此前,视觉基础模型的相关研究代表工作是 OpenAI 在 2021 年发表的CLIP。「CLIP 作为古早的视觉基础模型,通过与 BERT 对齐,使 ViT 获得一定程度的语言表征对齐能力,但参数量只有 300 M 左右,规模太小,且对齐的对象不是 LLM。(多模态对话系统的构造)必须使用更多训练数据才能进行表征对齐。」
这启发了上海 AI Lab 团队开始研究 InternVL。他们的目标是在保持基础模型强大性和多功能性的前提下,将其作为对话系统的 backbone,既支持图像检测、分割,也能够像 CLIP 支持多模态任务,例如图文检索。最开始是研究了一个 6+7 的 13B 模型(即 InternVL-Chat-V1.2),但由于在对话系统的实际应用中表现一般,又投入大量精力优化对话功能,又得出了一个 26B 模型,即风靡一时的 InternVL-Chat-V1.5。
从 InternVL-1.5 技术报告得知,视觉基础模型研究的三个关键点是:
一,视觉模型必须接驳能力与之相媲美的语言模型。比如,他们一开始的 7B 语言模型无法充分发挥 6B 视觉模型的优势,但在他们将语言模型的规模扩大到 20B 后,问题得到了大幅改善。InternVL-Chat-V1.5 采用的是书生·浦语的 20B 模型,使模型具备了强大的中文识别能力;二是要适配高分辨率;三是要采用高质量数据集。
在今年的 CVPR 上,GPT-4o 团队作者首次公开分享了背后的技术路线:GPT-4o 的文字转图像采用了 DALL·E 路线,文字转文字是 GPT,文字转语音是 TTS。InternVL 研究员评价,GPT-4o 注重不同模型间的跨模态转化,但 InternVL 的路线是专注于同一个模型上不同模态的输入与文本理解的输出。OpenAI 路线并不是所有视觉Foundation Model 研究的权威路线。
目前领域内有一种声音认为,视觉基础模型应具备更强的离散化特性,即各个模态(包括视觉、语音和3D输入)都转换为离散表示、而非高维向量,并将其存储在同一框架下,解耦对外感知侧模型和 LLM 大脑模型,如此一来,多模态更加统一,训练更加独立,不用再关注视觉模型是否传梯度。
对此,研究员认为,「这是对原生多模态支持的一种尝试,便于进行端到端的训练和跨模态能力的支持。离散压缩可能会损失一些细微但关键的信息,此技术路线还有很多关键问题有待探索。」
针对视觉基础模型的瓶颈与突破方向,思谋科技研究员、香港中文大学 DV Lab 实验室成员张岳晨也提出了相似的看法。
他认为,目前视觉基础模型的难点主要在于大规模高质量数据如何收集和助力大规模的训练。不仅如此,视觉基础模型如何跳出模型输出语言的限制,支持原生多模态(如GPT-4o)也是接下来值得思考与研究的问题。
据 AI 科技评论了解,目前 DV Lab 自研的视觉基座 Mini-Gemini 在开源社区引起了广泛的关注和反响,一度保持 SOTA 的位置,获得了 3k+ 的 stars。在今年的 CVPR 上,贾佳亚 DV Lab 团队的 LISA 模型、Video-P2P 等工作也获得了高度评价。
而南洋理工大学副教授张含望则认为,在视觉基础模型的研究中,大家经常忽视“理解任务”和“生成”任务本质是互斥的问题:前者是要让大模型丢掉视觉信息,而后者是让大模型尽可能保留视觉信息。然而,在语言大模型当中,这种互斥现象确从来没存在过。
张教授认为,症结就在于目前visual token 只是简单地把视觉信号“分块”,这种块状的空间序列和语言的“递归结构”是有本质区别。「如果不把图片或是视频变成递归序列 token 的话,是无法接入大语言模型的,而大语言模型是一个很重要的推理机器。但目前这一块,从行业来看,还没有特别好的研究成果出现,未来值得加大投入研究力度。」
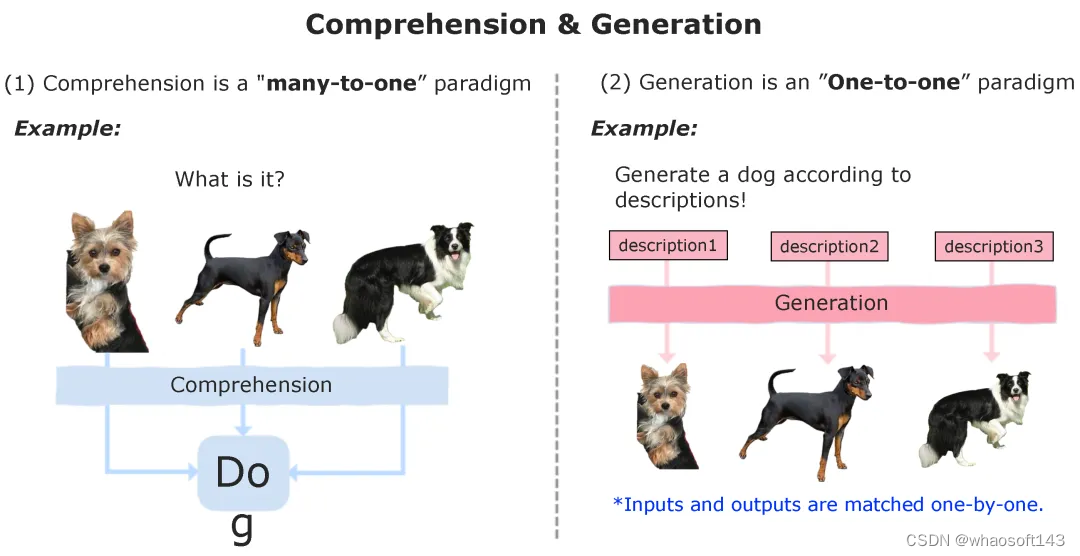
图注:「理解」与「生成」的区别,来自南洋理工大学张含望教授的分享
此外,不止一位研究者认为,无论是语言还是视觉,Foundation Model 的概念崛起后,AI 已经从一个开放的研究问题变成了一条实实在在的「工业生产线」,研究员的目标只有两个——「搞数据」与「搞算力」。
接近 OpenAI 的知情人士也称,一开始冲着OpenAI 的 AGI 光环加入的顶级高校博士毕业生在加入研究后,也发生自己在实际研究中也更多扮演着螺丝钉般的角色,比如花大量的时间处理数据。一句逐渐在 OpenAI 内部成为经典的 Slogan 是:
There is no magic。
2 自动驾驶、端侧 AI
自动驾驶在今年的 CVPR 上占据了非常重要的位置,将语言大模型落地到自动驾驶是特色。
其中,核心就在于如何把大模型放到自动驾驶的场景中,因为驾驶需要理解环境、预测下一个时刻该如何前行,遇到边缘场景(corner case)的时候能否确保安全性等,这些都是自动驾驶领域接下来要重点研究的方向。
今年自动驾驶的一个探索趋势就是,大语言模型为自动驾驶端到端技术的算法和infra提供了新的思路和解决方案。以仿真平台为例,之前的仿真平台,多半是以计算机图形学的能力去做固定引擎,从而生成仿真平台,今年就有多家公司通过生成式AI的方式去做仿真平台。
CVPR 2024 自动驾驶国际挑战赛是业界和学界都关注的重要赛事。该比赛由上海人工智能实验室联合清华大学、图宾根大学、美团等国内外高校和科技企业共同举办,围绕当前自动驾驶领域的前沿技术、实践落地场景难题等共设置了 7 大赛道,吸引了全球近 500 支队伍参赛。
挑战赛要求参赛者开发一个端到端的 AV 模型,使用 nuPlan 数据集进行训练,根据传感器数据生成行驶轨迹。据 AI 科技评论了解,端到端自动驾驶是今年 7 大赛道中竞争最为激烈的赛道之一,冠军来自于英伟达联合复旦大学的自动驾驶算法参赛团队,亚军则是来自中国的零一汽车自动驾驶研发团队。
英伟达的研究人员告诉 AI 科技评论,L2++ 级别的端到端自动驾驶,其能力主要体现于两大板块,分别是 Planning 和 Percetion。
在自动驾驶领域中非常重要的多模态数据集 nuScenes,其中有 93% 的数据只是包含直行在内的简单驾驶场景,天然无法实现工业界产品级别的自动驾驶。这些场景多为自动跟车、自动泊车,以及静态环境信息,如交通标志、道路标示线、交通灯位置等。
Perception 是自动驾驶系统中的感知部分,负责通过各种传感器来感知周围环境的能力。它相当于自动驾驶车辆的“眼睛”,为系统提供关于道路、车辆、行人、障碍物等元素的信息。而 Planning 模块相当于自动驾驶系统中的“大脑”,负责决策和规划车辆的行驶路径。它接收来自上游模块(如地图、导航、感知、预测)的信息,并在当前周期内进行思考并做出判断。
英伟达团队告诉 AI 科技评论,他们所作出的创新在于,在边缘场景的数据量不足够的情况下,使用基于规则的专家(rule-based expert)作为教师,将规则知识蒸馏给神经网络规划器。“我们认为,即便在数据量足够多的情况下,这一方法也将使得神经网络规划器变得更具有解释性。”
除了这些热门话题,在 CVPR 现场,还有很多厂商带来了亮眼的技术与产品,苹果就是其中一家。
从去年开始,苹果对大模型的投入力度肉眼可见地加大,尤其是生成式人工智能(GenAI)。虽然本身并不是一家 AI 能力特别强大的公司,但不懈的努力追赶后,苹果已然成功从一个三流水平的 AI 玩家挤进了二流水平战队。
今年 3 月,苹果正式发布多模态 LLM 系列模型,并在论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》中,通过构建大模型 MM1,阐述了多模态大模型预训练的方法、分析和见解,引起大众围观。
此次在 CVPR 大会上,论文的作者之一 Zhe Gan 现身大会论坛,系统介绍了苹果在更好地进行多模态大模型预训练所做的最新研究进展。他表示,大规模且与任务相关的数据对于训练高性能模型非常重要,因此,着重分析了如何通过基于模型的过滤和更多样化的数据源,来获得高质量的预训练数据。
据 Zhe Gan 介绍,在实验中,他们使用 45% 有字幕描述图像、45% 交错图像文本和 10% 的纯文本数据混合,作为预训练的数据混合,并为了评估,在各种字幕和 VQA 数据集使用 zero-shot (0-shot)和 few-shot (4-shot 和 8-shot)。

实验结果表明,交错数据对于 few-shot 和纯文本性能至关重要,而字幕数据提高了 zero-shot 性能;纯文本数据有助于提高 few-shot 和纯文本性能;精心混合图像和文本数据可以实现最佳多模态性能,同时保持强大的文本理解能力;合成数据有助于 few-shot 学习。
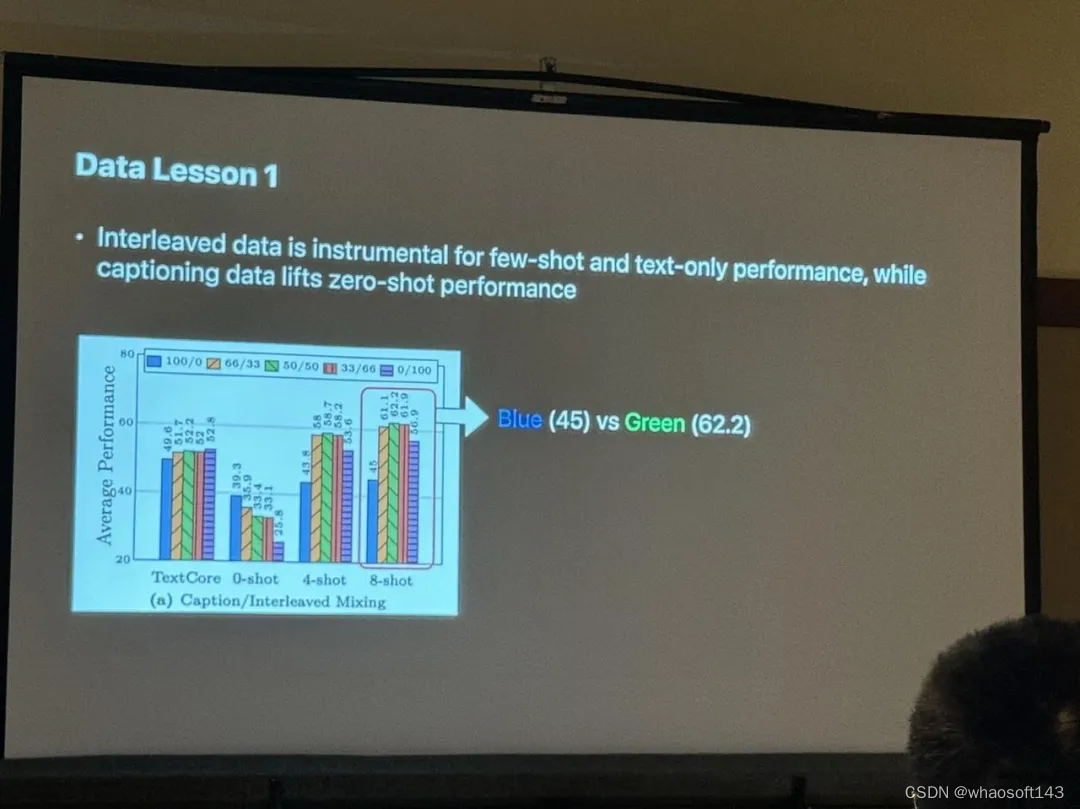
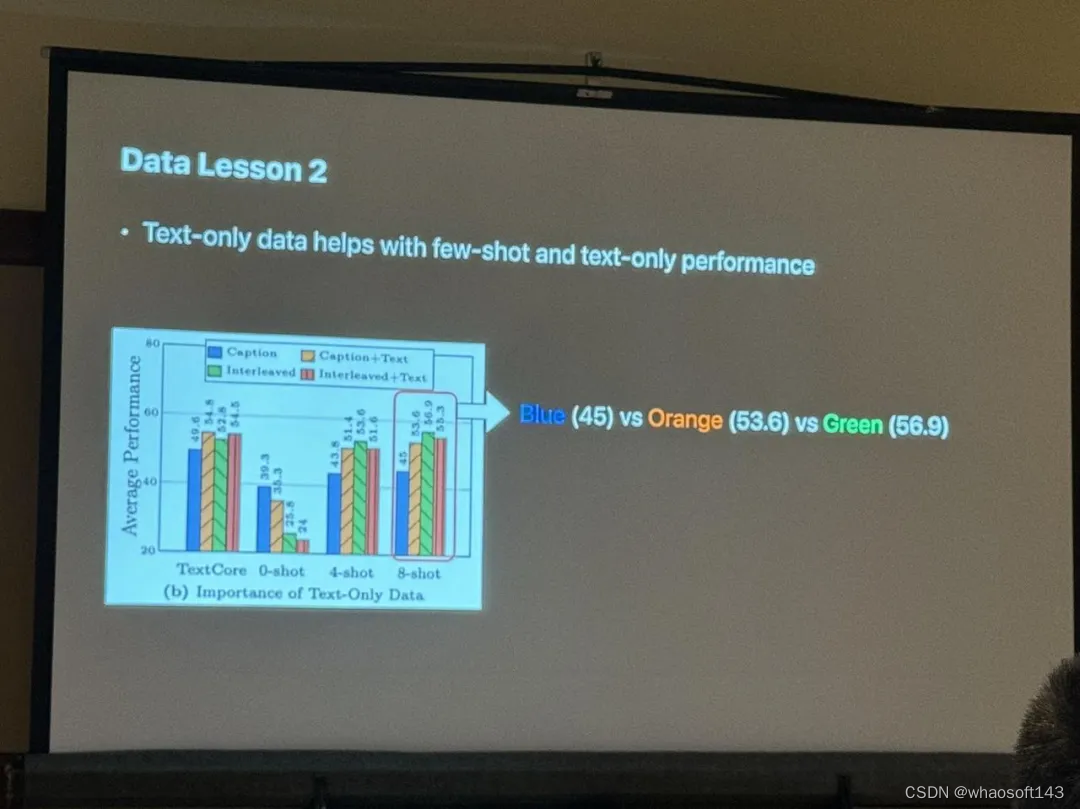
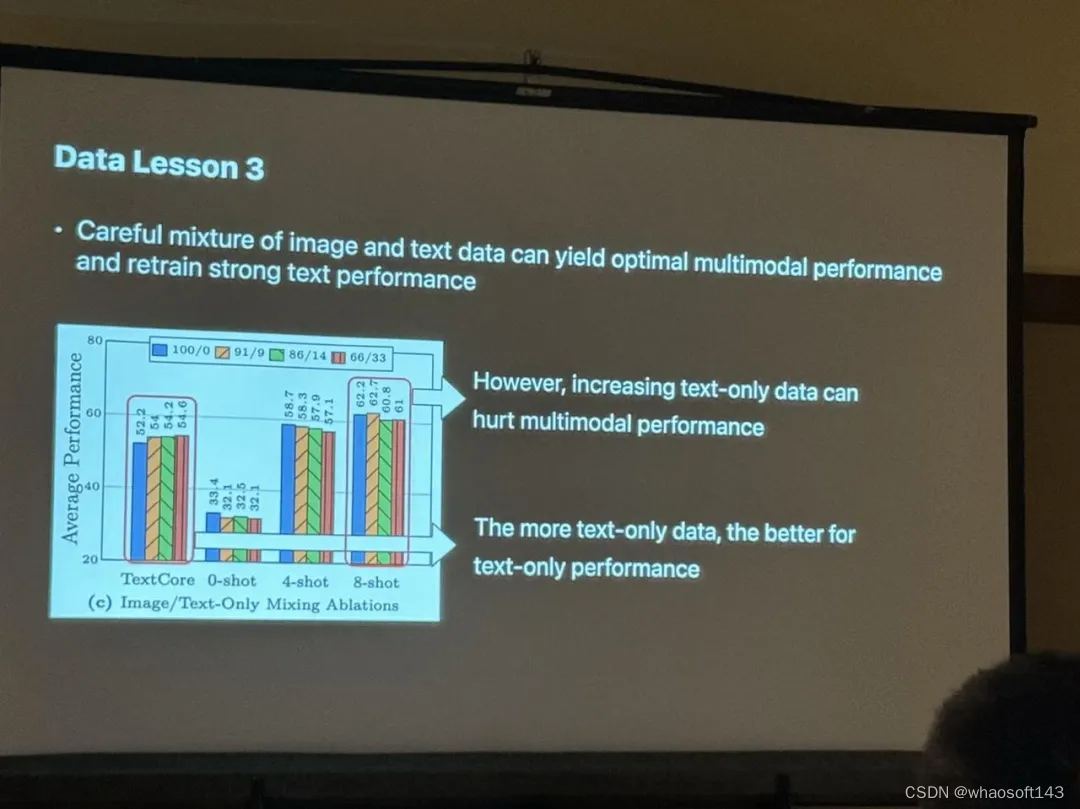
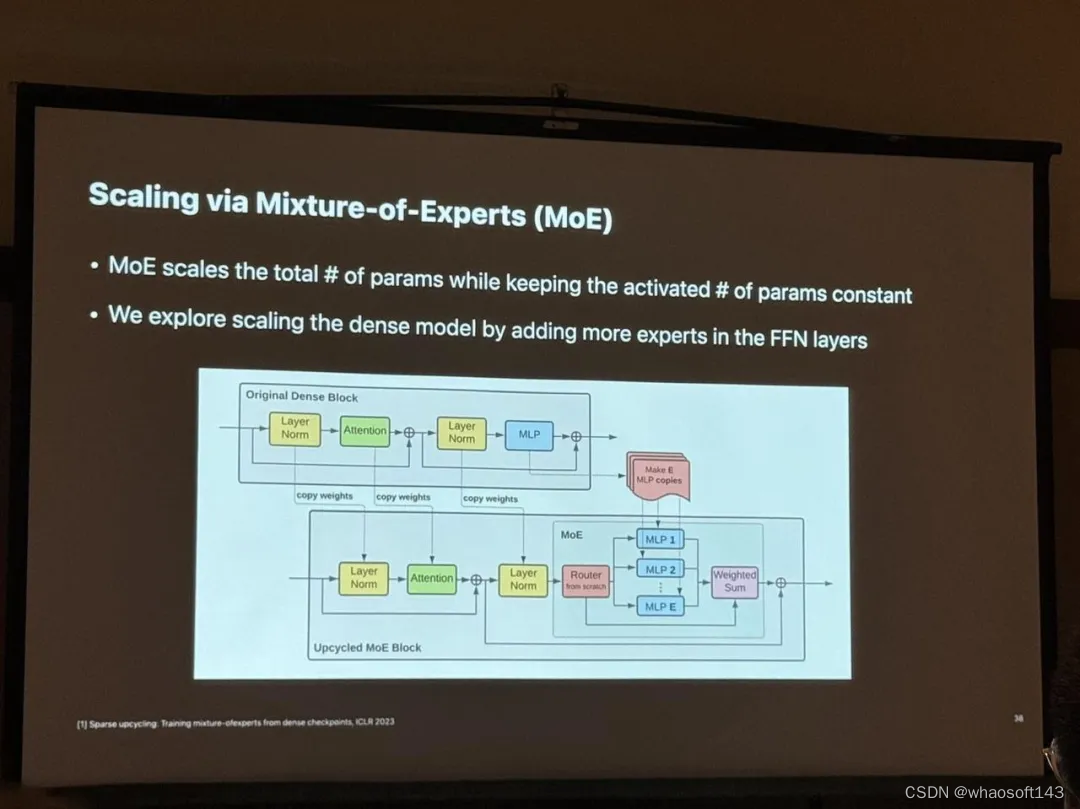
另外,Zhe Gan 表示,对于当前热门的 MoE 架构来说,可以在保持激活参数不变的情况下扩大模型总参数量,他们正在研究如何为多模态大模型设计更好的 MoE 架构。
3 写在最后
今年的 CVPR 是一场别开生面的盛会。
很多参会人员都向 AI 科技评论表示,相较于往年,今年 CVPR 的 AIGC 元素异常浓厚,新技术、新产品接连涌现,让人印象深刻。但也有一些学者认为,还应该有更多更新的技术出现。
香港中文大学深圳(CUHKSZ)助理教授韩晓光参加完此次 CVPR 之后,认为 CVPR 的论文投稿时可以考虑设置两条轨道,一个是工程轨道,以效果作为动机驱动点,一个是研究轨道,专门以好奇心为驱动。两条轨道都应该需要有最佳论文奖项,Sora 是他心里工程轨道的最佳研究,而今年的「Generative Image Dynamics」则满足了他对最佳研究论文的想象。
「一直思考 CV 的未来是什么景象,斗胆预测(或者是一种希望)未来将 from ‘virtual’ to ‘physical’,可能以各种不同的形式。」韩晓光说道。
# GaussianAvatar
教你网络“影分身术”,半小时生成专属数字人的GaussianAvatar
3DGS相较于NeRF具有渲染质量高,速度快的优势,NeRF是之前单目人体数字化身建模任务的主流表达方式,如何将3DGS的优势扩展到这一任务中替代NeRF是一个非常有意思的方向。本文介绍如何将3DGS这种高效表达方式建模人体数字化身,为大家呈现一个趣味性极强的可实时驱动的数字化身。
项目地址:
https://huliangxiao.github.io/GaussianAvatar
关于作者
本文由原paper一作胡良校博士全权翻译写作,胡良校博士就读于哈尔滨工业大学,师从张盛平教授,主要研究方向为人体数字化身建模与驱动,有多项工作发布于顶会顶刊上,本篇paper入选了CVPR 2024。
个人主页:https://huliangxiao.github.io/https://huliangxiao.github.io/
01 背景简介
数字化身建模是最近热门的计算机视觉和图形学任务,基于单目视频的人体数字化身建模只是其中的一个小任务。它在元宇宙背景下是存在一定的商业价值的,快速高效建模的需求也使得其成为了一个不小的挑战。
神经辐射场(Neural Radiance Field, NeRF) 具有高真实感的渲染质量,是一个建模人体很好的表达方式,但其存在渲染速度和建模速度慢的问题。尽管神经辐射场后续工作尽可能地在弥补这个问题,但基于体渲染的方式依旧很难达到落地级别的建模和渲染速度。
3D高斯泼溅(3D Gaussian Splatting, 3DGS) 首先在建模速度和渲染速度上就比神经辐射场要好不少,这得益于其显式的参数化形式以及点云渲染方式。如何将3DGS应用到人体数字化身建模任务上着实是不小的期待。
02 方案提出
现有主流的单目人体数字化身建模算法大多基于NeRF,除了背景所述的建模和渲染速度较慢的问题,该类方法还有反向蒙皮过程中遇到的一对多问题,这也就导致初始人体姿态不准的问题很难被解决。我们这次提出的「基于可驱动3DGS的人体数字化身建模GaussianAvatar」,希望借助3DGS快速的建模和渲染速度,从单目视频中高效建模人体数字化身并实现实时驱动。同时,借助3DGS显式表达的特点,GaussianAvatar提出了标准姿态下的可驱动3DGS,通过前向蒙皮过程驱动人体高斯点云——前向蒙皮不仅避免了一对多问题,还使得人体姿态优化更为准确。

图1|GaussianAvatar实时驱动效果展示
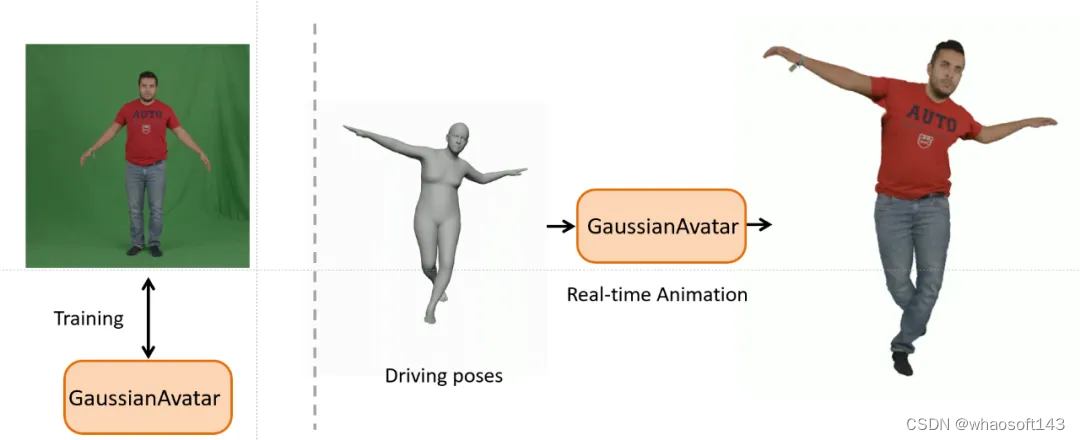
图2|GaussianAvatar任务定义
03 方法详析
方法流程如图2所示,对当前帧估计一个SMPL/SMPL-X模型,GaussianAvatar在其表面采样空间点并根据UV图关系存成一张位置UV图,其中每一个像素表示空间点的位置坐标。GaussianAvatar将其作为动作信号输入到一个位姿编码器获得动作特征,通过残差相加的方式和一个优化后的特征向量一起输入到高斯参数解码器中得到标准姿态下的高斯点云,然后通过线性混合蒙皮公式进行驱动并最终渲染成当前姿态下的图像。这其中主要包含以下几个技术细节:

图3|GaussianAvatar方法流程
3.1 可驱动3DGS
可驱动3DGS的本质就是将3DGS和人体模型SMPL/SMPL-X进行结合,可以用一个公式进行说明:
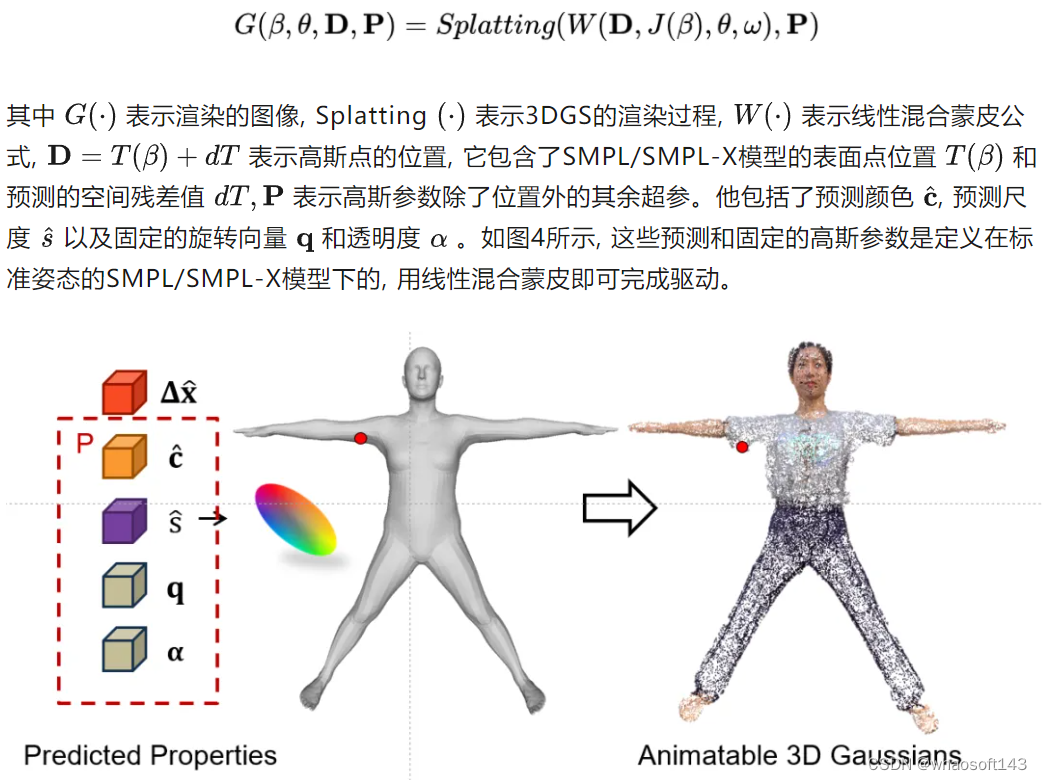
图4|可驱动3DGS
3.2 动态高斯参数预测
定义完可驱动3DGS,我们需要借助神经网络来预测这些属性参数。如图3所示,我们为此设计了一个动态外观网络和一个可优化特征向量。动态外观网络包括了一个姿态编码器U-Net和一个高斯参数解码器MLP。整个网络用公式表示如下:
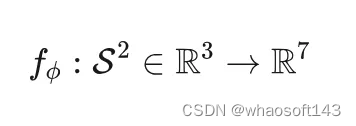
网络学习动作信号与动态高斯参数的映射关系。上诉提到,GaussianAvatar是将位置UV图作为动作信号,当人体动作发生变化时,位置UV图上的像素值也在发生变化,同时借助U-Net的CNN结构能够更好地表达高斯点的属性变化。
这里的预测的高斯参数和源3DGS参数有较大的偏差。源3DGS预测的是球谐系数,与视角方向有关,但是对于单目视频而言,相当于就只有一个视角,因此直接预测颜色的RGB值会比预测球谐系数更为简便有效。同时GaussianAvatar将高斯点云的各项异性改为各项同性,这是因为单目视频缺少多视角的监督,对于一个视频帧而言,神经网络更容易将高斯点过拟合到当前视角,当高斯点是一个各项同性的球体时会减小过拟合的影响。基于此,我们固定旋转向量和透明度,并且直接预测高斯球体的半径。如图5所示,基于各项同性的高斯点云在另一个视角的渲染结果更具合理性。
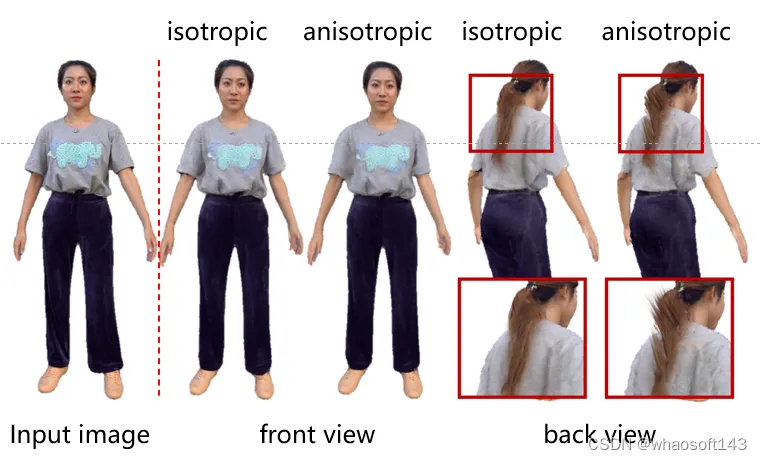
图5|各项同性高斯的影响
3.3 动作联合优化
如图3所示,我们对线性混合蒙皮公式用到的人体姿态进行联合优化,这是因为单目人体SMPL估计不准,需要进一步矫正。对此,我们对初始动作添加一个可优化残差,公式表示如下:

3.4 训练策略
GaussianAvatar的训练过程包括两个阶段,第一个阶段将姿态编码器固定,训练可优化特征向量,高斯参数解码器以及动作的可优化残差。这个阶段的损失函数如下:

经过这个阶段的训练,我们可以得到较为精确的人体姿态以及表示粗糙人体外观的特征向量。在第二个阶段,我们将姿态编码器也加入训练,同时固定特征向量和人体姿态。同时将替换成,用来约束姿态编码器的输出。
4 实验
4.1 实验设置
我们使用的数据集包括了People-Snapshot,NeuMan以及自己采集的DynVideo数据集。People-Snapshot数据集记录了不同人在单目相机前转圈的视频,NeuMan数据集采集了室外运动的人的视频,DynVideo使用手机采集了两组动作较为丰富的人体运动视频,具有相对较多的人体外观变化。
对比方法我们选择了两个基于NeRF的方法:HumanRF以及InstantAvatar。HumanRF维护了一个标准空间的神经辐射场以及一个运动场来表达数字化身;InstantAvatar使用Instant-NGP对NeRF进行加速,能够较快的建模和驱动数字化身。
4.2 定量实验对比

表1|People-Snapshot定量对比结果。Opt.表示动作联合优化,Dyn.表示动态外观建模
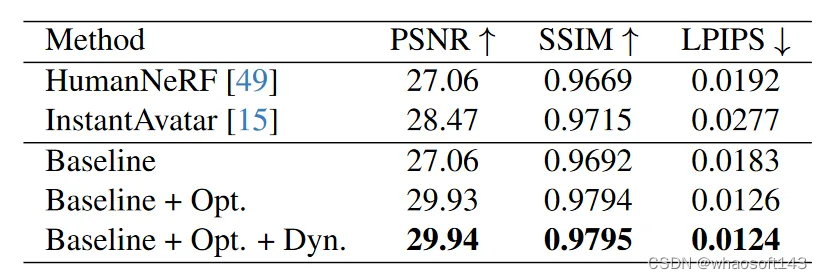
表2|NeuMan定量对比结果。Opt.表示动作联合优化,Dyn.表示动态外观建模
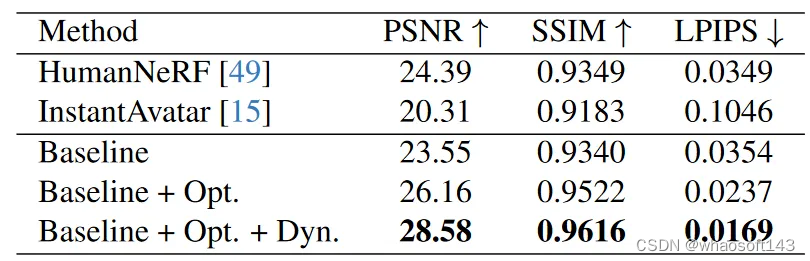
表3|DynVideo定量对比结果。Opt.表示动作联合优化,Dyn.表示动态外观建模
4.3 定性实验对比

图6|新视角定性实验对比结果

图7|定性消融实验结果:(a)是原图;(b)动作优化和动态外观建模联合结果;(c)只包含动作优化;(d)不包括动作优化和动态外观建模

图8|动作优化实验结果:(a)(d)是原图;(b)(e)动作优化后结果;(c)(f)初始姿态估计
05 总结
我们通过结合SMPL/SMPL-X模型提出了可驱动3DGS,这一方法能够实现高效建模和实时驱动,外观动作联合优化有效解决初始姿态不准的问题,给予动捕一个新的思路。
然而GaussianAvatar还存在一些问题,例如无法达到分钟级的建模速度,由于CNN的加入,GaussianAvatar需要几个小时才能在动态外观比较丰富的数据上进行拟合。此外,GaussianAvatar还无法解决宽松衣物的建模,在裙子等衣物上表现较差。建模复杂衣物一直都是数字化身建模的难点,当然这一问题并不是没有解决方案,我们相信在今后的算法中这一问题将会得到有效解决。
# Autoregressive Image Generation without Vector Quantization
何恺明新工作!加入MIT的首篇论文!打破自回归图像生成瓶颈,奥赛金牌得主参与!
巧妙地借鉴了扩散模型的思想,成功地将自回归模型从矢量量化的束缚中解放出来,实现了连续值生成图像的突破。
近日,深度学习领域的杰出研究者何恺明及其团队又放了个大招,推出其团队最新研究工作,在AI研究领域引起了广泛关注。
何恺明2024年加入麻省理工学院(MIT),在电气工程与计算机科学系担任教职。
何恺明团队联合Google DeepMind和清华大学,首次提出了一种无需矢量量化的自回归图像生成方法,彻底颠覆了人们对自回归生成技术的认知。
在传统的自回归图像生成中,矢量量化一直是不可或缺的一环。然而,这种方法的局限性在于,它依赖于离散的tokenizer,这在一定程度上限制了生成图像的灵活性和多样性。
而今,何恺明团队巧妙地借鉴了扩散模型的思想,成功地将自回归模型从矢量量化的束缚中解放出来,实现了连续值生成图像的突破。
一起看看这一创新是如何提高自回归图像生成的质量和多样性的,以及是如何改变AI领域的未来走向!
论文题目:
Autoregressive Image Generation without Vector Quantization
论文链接:
https://arxiv.org/abs/2406.11838
扩散损失引入自回归图像生成
自回归模型在自然语言处理中非常成功,人们普遍认为它们需要离散表示。因此,在将自回归模型应用于图像生成等连续值领域时,研究主要集中在如何将图像数据离散化,而不是直接在连续空间上建模。
但自回归的本质在于基于前面的token作为输入来预测序列中的下一个token,不禁疑惑:难道连续的token值就不能实现上述过程了吗?
何凯明团队将扩散过程中的损失函数引入到自回归图像生成过程,引入了扩散损失(Diffusion Loss)。

统一自回归和掩码生成模型的创新框架
何恺明团队还提出了一种统一标准自回归模型(AR)和掩码生成模型(MG)的广义自回归框架,具体表现为掩码自回归(MAR)模型。该模型利用双向注意力机制,在随机顺序下同时预测多个输出标记,同时保持自回归的特性。这一方法显著提高了生成速度。
传统的因果注意力机制,它通过限制每个标记只关注之前的标记来实现自回归。而双向注意力机制,它允许每个标记在序列中看到所有其他标记。掩码标记在中间层添加了位置嵌入,这种设置只在未知标记上计算损失,但允许序列中的标记之间进行全面的交流,从而在推理时能够逐个生成标记。同时,它还允许我们同时预测多个标记。

自回归+扩散 vs 自回归 vs 扩散
作为自回归模型和扩散模型的融合,其方法极具有创新性,那与传统自回归生成和扩散生成相比,性能如何呢?
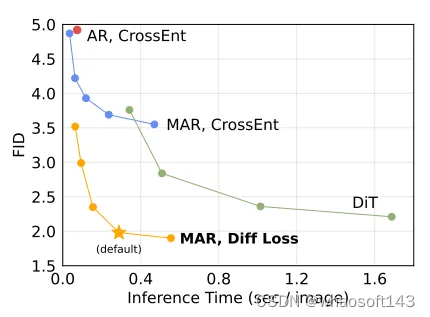
生成快且效果精
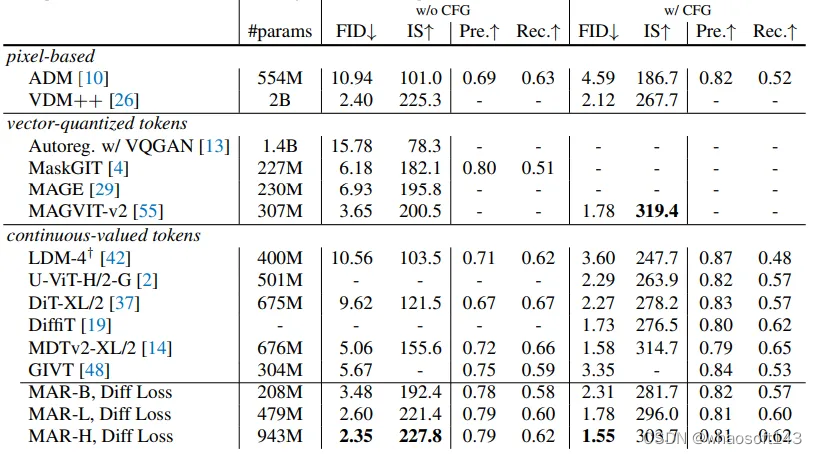
相比于传统的自回归(AR)模型和扩散Transformer(DiT)模型,MAR模型在使用扩散损失后,能够更快速且更准确地生成图像。具体来说,MAR模型的生成速度小于0.3秒每张图像,且在ImageNet 256×256数据集上的FID得分小于2.0,体现了其高效性和高质量。
与领先模型相较毫不逊色
不同模型规模下,经过800个周期的训练,此方案展示了良好的扩展性。与当前的领先模型相比,此方法也毫不逊色。在不使用CFG的情况下,MAR模型的FID为2.35,显著优于其他基于标记的方法。最佳条目的FID为1.55,与领先模型相比具有竞争力。
总结
何恺明团队在图像生成领域的强有力结果表明,自回归模型或其拓展版本不仅仅是语言建模的有力工具,它们在其他领域也有很大的潜力。这些模型不必受限于向量量化表示,这意味着它们可以更有效地处理连续值表示的数据。
-------
whaosoft aiot http://143ai.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









