







mysql最左匹配原则失效
最左匹配原则
索引的底层是一颗B+树,也就是说在联合索引中,优先走最左边列的索引。对于多个字段的联合索引,也同理。如 index(name,age,address) 联合索引,则相当于创建了 a 单列索引,(name,age)联合索引和(name,age,address)联合索引。在查询时,where 条件中若有 name 字段,则会走这个联合索引。
最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
验证:
# 创建用户表,同时创建name,age,address三个字段的联合索引
CREATE TABLE `user` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) COLLATE utf8mb4_bin DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_user` (`name`,`age`,`address`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
# 插入一条数据
INSERT INTO user(`id`, `name`, `age`, `address`) VALUES (1, 'zs', 12, 'beijing');
我们可以执行下面的几条语句验证一下这个原则。
EXPLAIN SELECT * FROM user WHERE name = 'zs';

EXPLAIN SELECT * FROM user WHERE name = 'zs' and age = 12

EXPLAIN SELECT * FROM user WHERE name = 'zs' and age = 12 and address = 'beijing'

这种方式用到了索引条件顺序调换不影响查询结果,因为Mysql中有查询优化器,会自动优化查询顺序
EXPLAIN SELECT * FROM user WHERE age = 12 and address = 'beijing' and name = 'zs'
EXPLAIN SELECT * FROM user WHERE address = 'beijing' and name = 'zs' and age = 12

失效的情况
根据最左前缀原则,以下 sql ,肯定会使索引失效的。
EXPLAIN select * from user where address='beijing';

这就让我非常疑惑了,难不成最左前缀原则是错的?又或者,是 Mysql 随着版本升级,已经智能到不需要 care 最左前缀原则了吗?
带着这个疑问,我们一探究竟。在这之前需要了解一些前置知识。
聚集索引和非聚集索引
我们知道 Mysql 底层是用 B+ 树来存储索引的,且数据都存在叶子节点。对于 InnoDB 来说,它的主键索引和行记录是存储在一起的,因此叫做聚集索引(clustered index)。
除了聚集索引,其它索引都叫做非聚集索引(secondary index)。包括普通索引,唯一索引等。
另外需要注意,在 InnoDB 中有且只有一个聚集索引。它有三种情况:
- 若表存在主键,则主键索引就是聚集索引。
- 若不存在主键,则会把第一个非空的唯一索引作为聚集索引。
- 否则,就会隐式的定义一个 rowid 作为聚集索引。
为了方便理解,下边以 InnoDB 的主键索引和普通索引为例,看下它们的存储结构。
#创建一张表,结构如下,并添加几条记录(张三,李四,王五,孙七):
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_stu` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
insert into student(id,name,age) values(1,'zs',12);
insert into student(id,name,age) values(5,'ls',14);
insert into student(id,name,age) values(9,'ww',12);
insert into student(id,name,age) values(11,'sq',13);
在 InnoDB 中,主键索引的叶子节点存储的是主键和行记录,而普通索引的叶子节点存储的是索引列和主键(对于 MyISAM来说主键索引的叶子节点存储的是主键和对应行记录的指针,普通索引的叶子节点存储的是当前索引列和对应行记录的指针)。
因此,id 为聚集索引,name 为非聚集索引。它们对应的 B+ 树结构如下图所示,

回表查询
从上边的索引存储结构,我们可以看到,在主键索引树上,通过主键就可以一次性查出来我们所需要的数据,速度非常的快。
因为主键和行记录就存储在一起,定位到了主键,也就定位到了所要找的记录,当前行的所有字段都在这(这也是为什么我们说,在创建表的时候,最好是创建一个主键,查询时也尽量用主键来查询)。
对于普通索引,如例子中的 name,则需要根据 name 的索引树(非聚集索引)找到叶子节点对应的主键,然后再通过主键去主键索引树查询一遍,才可以得到要找的记录。这就叫 回表查询。
以如下 sql 为例。
select * from student where name='zs';
它需要查询两遍索引树。
- 通过非聚集索引定位到主键 id=1。
- 通过聚集索引定位到主键id为1,对应的行记录。
它的查询过程图如下

索引覆盖
对于上边的回表查询来说,无疑会降低查询效率。那么,有的童鞋就会问了,有没有什么办法,让它不回表呢?
答案当然是有了,就是索引覆盖。
何为索引覆盖,就是在用这个索引查询时,使它的索引树,查询到的叶子节点上的数据可以覆盖到你查询的所有字段,这样就可以避免回表。
还是以上边的表为例,现在 zs 对应的索引树上边,只有它本身和主键的数据,并不能覆盖到 age 字段。那么,我们就可以创建联合索引,如 KEY(name,age)。并且,查询的时候,显式的写出联合索引对应的字段(name和age)。
创建联合索引如下,
KEY `idx_stu` (`name`,`age`);
查询语句修改如下,
– 覆盖联合索引中的字段
select id,name,age from student where name='zs' and age=12;
这样,当查询索引树的时候,就不用回表,可以一次性查出所有的字段。对应的索引树结构如下:
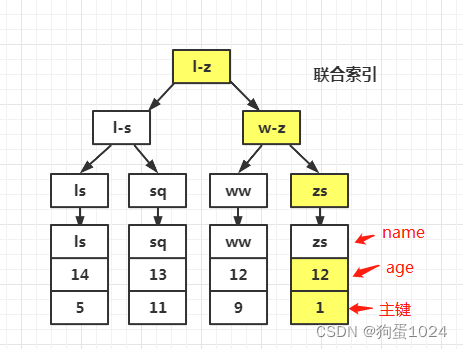
图中,联合索引中的字段(name,age)都应该出现在索引树上的,这里为了画图方便,且因数据量太小,没有画出来。只表现出了:叶子节点存储了所有的联合索引字段。
索引失效
为了验证最左前缀原则,我们需要对原来的表结构进行改造。再添加两个字段(address,sex),然后创建三列的联合索引(name,age,address)。
drop table student;
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_stu` (`name`,`age`,`address`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
insert into student(id,name,age,address,sex) values(1,'zs',12,'beijing',1);
insert into student(id,name,age,address,sex) values(5,'ls',14,'tianjin',0);
insert into student(id,name,age,address,sex) values(9,'ww',12,'shanghai',1);
insert into student(id,name,age,address,sex) values(11,'sq',13,'hebei',1);
分别用三种方式,使之符合最左前缀原则。然后查看它们的执行计划如下,可以看到,最终都走了索引。
explain select * from student where name='zs';
explain select * from student where name='zs' and age=12;
explain select * from student where name='zs' and age=12 and address='beijing';
修改 sql 如下,如何?执行计划如下
explain select * from student where address='beijing';

如我们所料,这不符合最左前缀原则,因此索引失效,走了全表扫描。
问题解惑
到现在为止,我们发现最左前缀原则一切正常。然后回到最开始抛出的问题,为什么这个原则就不生效了呢?(创建的联合索引,还有 sql 语句都是一样的啊!)
别着急,还记得前面我们说的索引覆盖吗? 这次,我们利用索引覆盖原理,只查询特定的字段(只有主键和联合索引字段)。
explain select id,name,age,address from student where address='beijing';
再查看执行计划,

问题来了,此时违反了最左前缀原则,但是符合覆盖索引,为什么就走索引了呢?
我们对比一下,若用最左列,和不用最左列,它们的执行计划有何不同。
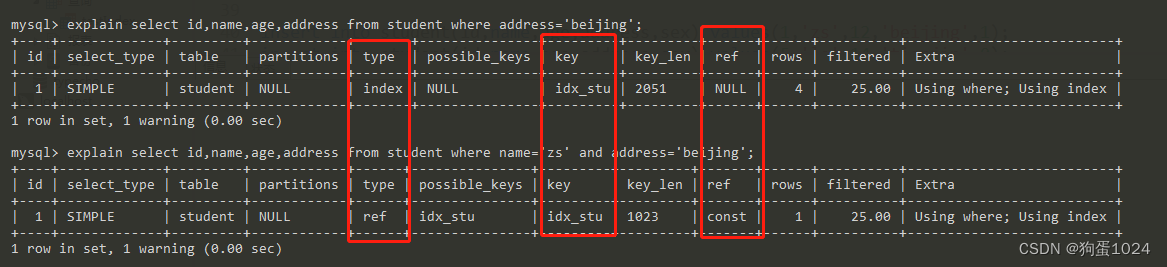
会发现,若不符合最左前缀原则,则 type为 index,若符合最左前缀原则,则 type 为 ref。
index 代表的是会对整个索引树进行扫描,如例子中的,最右列 address,就会导致扫描整个索引树。
ref 代表 mysql 会根据特定的算法查找索引,这样的效率比 index 全扫描要高一些。但是,它对索引结构有一定的要求,索引字段必须是有序的。而联合索引就符合这样的要求!
联合索引内部就是有序的,我们可以把它理解为类似于 order by name,age,address 这样的排序规则。会先根据 name 排序,若name 相同,再根据 age 排序,依次类推。
所以,这也解释了,为什么我们要遵守最左前缀原则。当最左列有序时,才可以保证右边的索引列有序。
退而求其次,若不符合最左前缀原则,但是符合覆盖索引,就可以扫描整个索引树,从而找到覆盖索引对应的列(避免了回表)。
若不符合最左前缀原则,且也不符合覆盖索引(形同 select *),则需要扫描整个索引树。完成之后,还需要再回表,查询对应的行记录。
此时,查询优化器,就会认为,这样的两次查询索引树,还不如全表扫描来的快(因为联合索引此时不符合最左前缀原则,要比普通单列索引查询慢的多)。因此,此时就会走全表扫描。
有童鞋就要问了,你在这废话了一大堆,还是没有解答最初的疑惑啊 !!!
不然,其实上边的分析就已经解答了。我们仔细观察最开始的 user 表,和此时的 student 表有什么不同。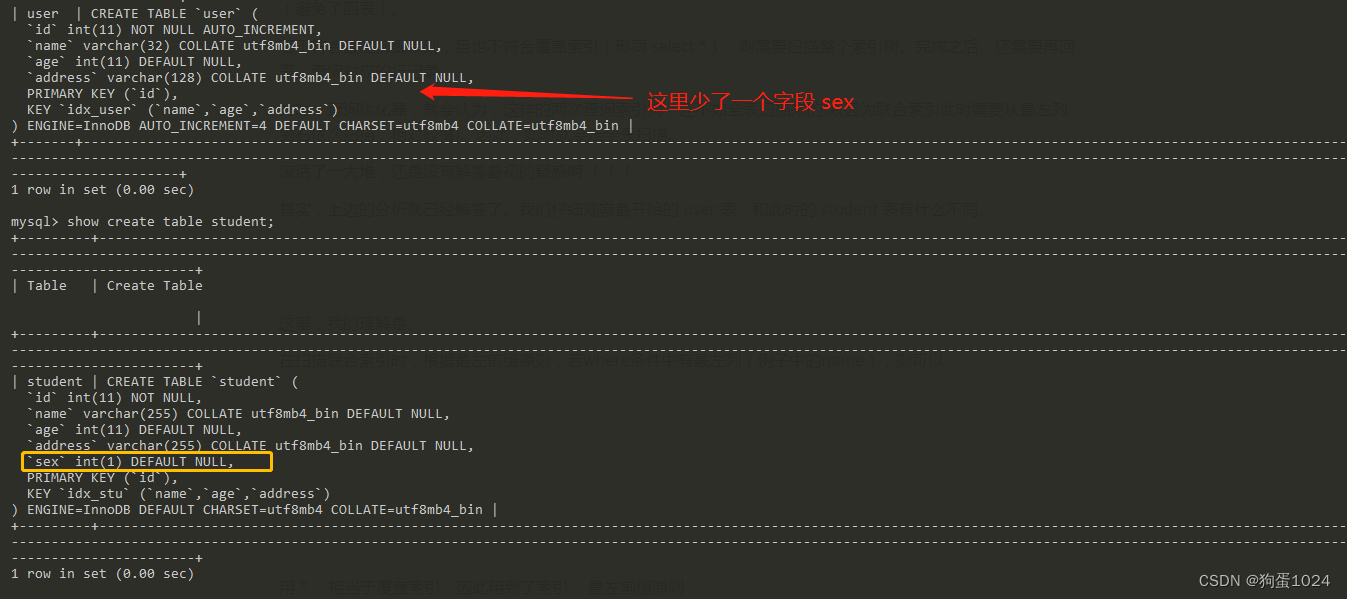
user 表中,和 student 表相比,少了 sex 字段。但是,它们所建立的联合索引却是一样的 KEY(name,age,address)。
所以,在 user 中,我们最初的 sql 语句就等同于 ,
– 最初的sql
EXPLAIN select * from user where address='beijing';
– 等同于
EXPLAIN select id,name,age,address from user where address='beijing';
这个结构就是我们上边讨论的情况:不符合最左前缀原则,但是符合索引覆盖。这种情况,是会走索引的。
结论
那么,结论也就出来了。并不是最左前缀原则失效了,也不是 Mysql 变的更智能了,而是此时创建的表结构,以及查询的 sql 语句恰好符合了索引覆盖而已。真的是虚惊一场!!!















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









