







解决的问题
HDFS如何实现有状态的高可用架构
HDFS如何从架构上解决单机内存受限问题
HDFS能支撑亿级流量的核心源码设计
HDFS书籍推荐:深度剖析Hadoop HDFS/Hadoop 2.X HDFS源码剖析
hadoop 3代版本 HDFS如何实高可用架构
第一代hadoop解决海量数据如何存储和海量数据如何计算问题,核心设计为HDFS和Mapreduce
第一代主从式架构,唯一主节点NameNode,多个从节点DataNode
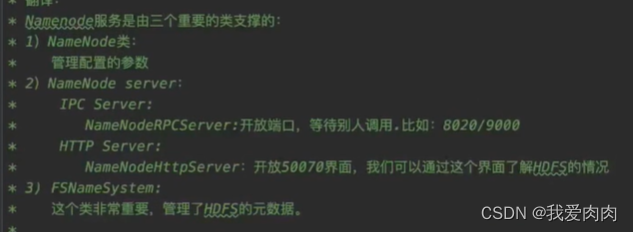
NameNode:
管理元数据:文件和block块,block块和DataNode主机关系
NameNode为了快速响应用户操作请求,元数据都加载到了内存中
DataNode:
上传数据划分为固定大小块(hadoop1默认64mb)
每个文件块默认3个副本,保证数据安全
缺点:
单点故障,NameNode内存受限
第二代
单点故障如何解决?
多台NameNode分Active状态和StandBy状态。Active对外提供读写功能。注:第二代只支持一台Active和一台StandBy的两台NameNode
增加JournalNode角色(大于3台)负责同步NN editlog(最终一致)
增加Zookeeper负责NN主从选举和切换,DN同时向NN们回报block清单
NameNode内存受限如何解决?
可以一个集群采用联邦模式配置多个Active/StandBy NameNode组,一个联邦对应两个NameNode(一主一从)
HDFS元数据信息
1 目录结构树 2 文件和数据块之间映射关系 3 数据块和多个副本所在主机之间的映射关系
三者内存中都存储,但磁盘不存第三个信息
HDFS如何管理元数据/NameNode如何支撑亿级流量/NameNode如何高效写磁盘
配置第一次启动前的格式化就是为了NameNode磁盘fsimage存储元数据,此时内存中fsimage = 磁盘中fsimage
当上传文件时,往NameNode内存中fsimage写入一条元信息,同时也写入磁盘editlog日志(预防内存fsimage丢失),
此时内存fsimage = 磁盘fsimage + editlog (如果节点故障重启后,内存会合并磁盘fsimage+多个editlog成新的feimage放入内存)
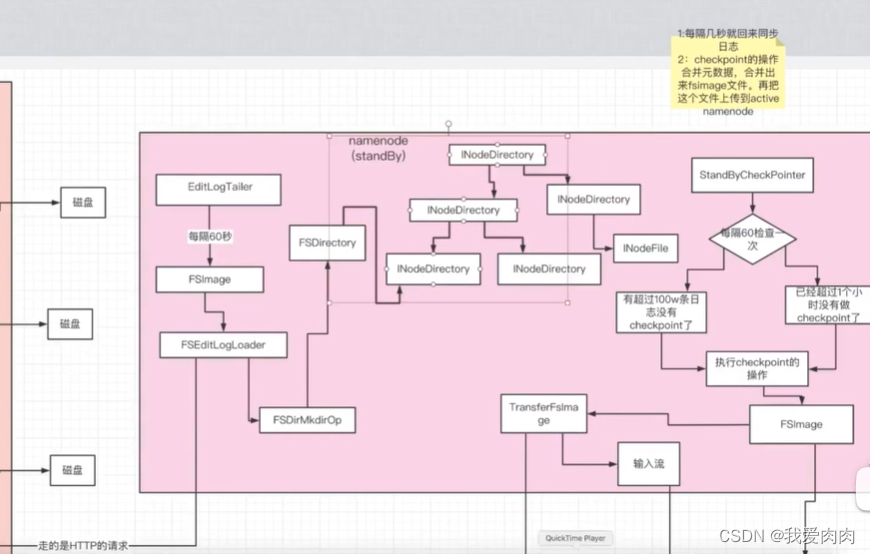
SecondaryNameNode/StandBy节点会定时合并NameNode内editlog文件到内存中,然后写入磁盘fsimage。
定时的将磁盘fsimage替换NameNode的fsimage
SecondaryNameNode作用:一是镜像备份,二是日志与镜像的定期合并(为了减少下次重启启动时间)两个过程同时进行,称为checkpoint
分段加锁和双缓冲方案,高效写磁盘
原理版本 Hadoop 2.3.0
NameNode(Hadoop RPC服务端)启动流程
NameNode源码注解
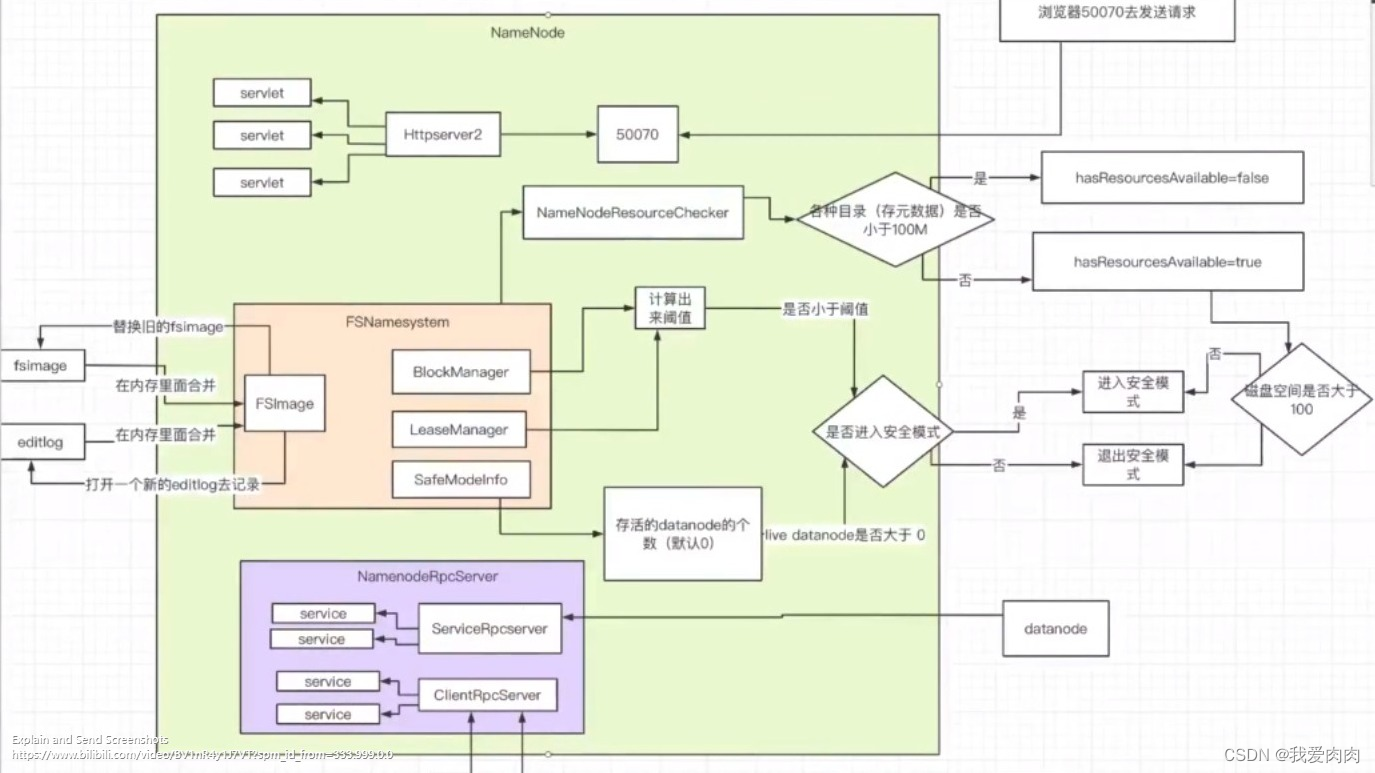
全局图
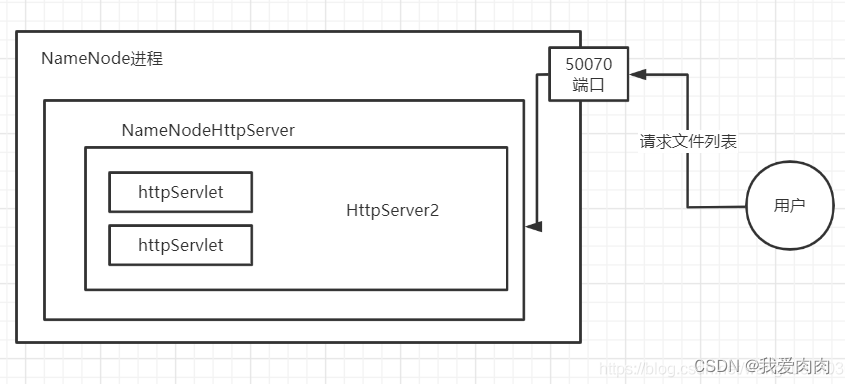
启动第一步NameNode自定义实现HttpServer2
1.main方法调用createNameNode 尝试构建NameNode
2.args 参数转为内部能识别的option选项 真正的构建NameNode
3.NameNode 内部构建的时候 调用initialize(conf); 进行核心初始化
4.构建NameNodeHttpServer,获取对外端口地址 默认50070
5.NameNodeHttpServer.start()内部 再次构建hadoop自己实现的一套HttpServer2 服务机制
6.将处理url请求的servlet 与 httpServer 绑定
(url 映射 servlet ,比如 http://XXXX:50070/listPath/ 交给哪个servlet处理)
启动第二步FsNameSystem
FSDirectory 是一个直接在内存内的数据结构,也就是内存目录树
FsNameSystem作用是把元数据记录持久化到磁盘上
1 资源存储检查(core-site.xml/hdfs-site.xml配置fsimage和editlog存储目录,默认一致)
检查存储目录磁盘够不够(fsimage/editlog两者各默认100mb,各小于100mb判定不够)
如不够,变量hasResourseAvailable = false
2 启动时内存fsimage合并磁盘fsimage + 磁盘editlog,替换内存fsimage,并打开新的editlog去记录
3 HDFS是否进入安全模式 ( 代码setBlockTotal()只读模式)
HDFS block分两种类型
complete类型:正常可用block
underconstruction:正在构件中block
安全模式启动条件
1 dataNode汇报的可用block < blockTotal * threshold 则为安全模式,阈值默认0.999
2 dataNode异常节点达到指定数量则为安全模式(默认改参数为0,不生效,需要主动配置)
3 磁盘资源不够,通过前面第一步资源存储检查已经获得的变量hasResourseAvailable来直接判定
启动第三步NameNodeRpcServer
启动重要服务,对外提供服务端接口服务
启动等待复制的线程
启动管理datanode服务,激活datanode管理心跳等
DataNode (依然RPC服务端)启动流程

介绍
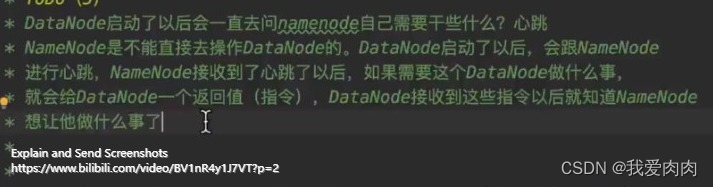
NameNode不会直接操作DataNode,主要通过DataNode主动通过周期性发送心跳给NameNode,然后NameNode返回响应指令给DataNode。
某个client或dataNode想访问某个dataNode,都需要先和NameNode通信获取主机名端口号。DataNode启动后开放一个(RPC)socket服务,
等待别人调用
启动第一步初始化
初始化RPC服务
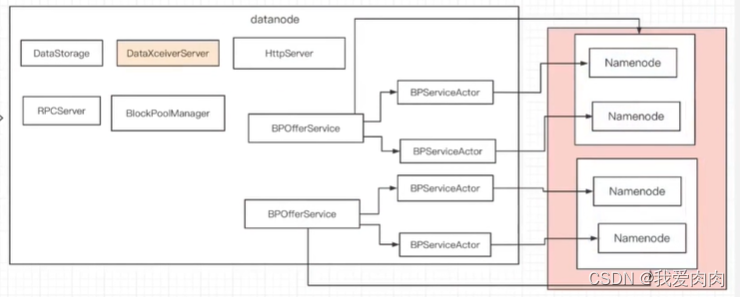
创建BlockPoolManager(一个集群对应一个BlockPool,联邦机制对应多个NameNode,多BlockPool)
一个主从NameNode对应一个BPOfferService,一个NameNode对应一个BPServiceActor,
如果联邦模式则对应多个BPOfferService,如上图
启动第二步向NameNode进行注册和心跳
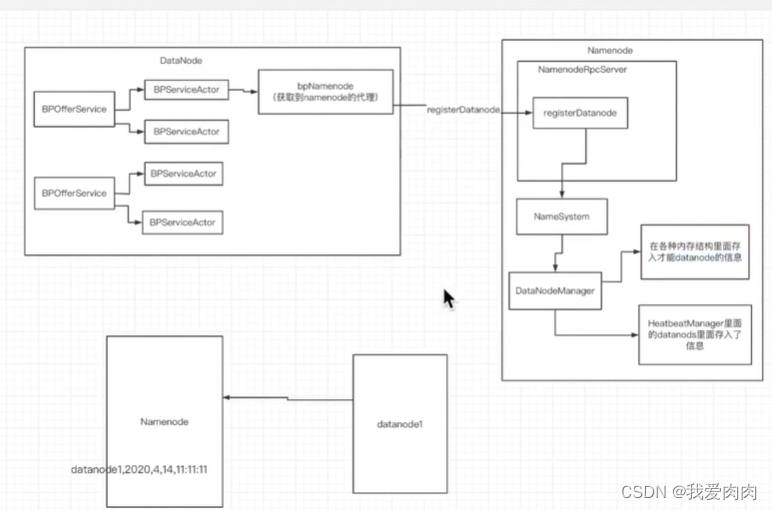
启动BPServiceActor的线程run方法
向NameNode注册
封装创建存储信息,代理远程调用NameNode注册方法(存入NameNode各种内存结构和HeartbeatManager)
向NameNode周期性3秒发送心跳
更新存储信息
修改上一次心跳时间:
有线程遍历所有节点心跳时间,当前时间-上次心跳时间>阈值10min30s 来判断dataNode是否挂了
如果超时则删除所有相关注册信息
HDFS如何管理元数据/NameNode如何支撑亿级流量/NameNode如何高效写磁盘
分段加锁和双缓冲方案
双缓冲:
磁盘写优化为内存写,通过两块内存CurrentBuffer和SyncBuffer
client数据直接写入CurrentBuffer,当CurrentBuffer写满后交换内存到SyncBuffer
通过SyncBuffer写入磁盘,CurrentBuffer可以继续写入数据不影响写入性能
分段加锁:
写内存,内存转换分段加锁,写磁盘不加锁
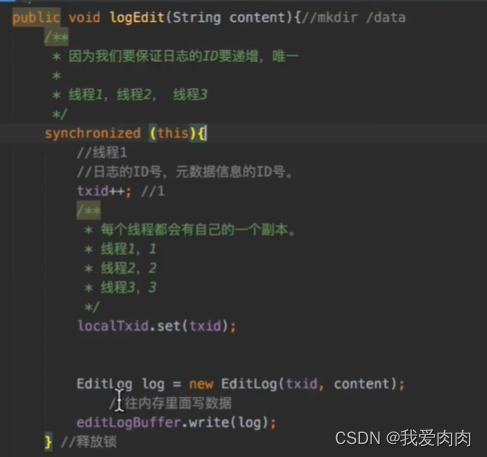
第一步写CurrentBuffer内存实现思路
(事务id)txid是threadlocal的,每个线程独立记录。下图每个操作都不费时,能够支持每秒几千的并发写入
第二步双缓冲转换实现思路
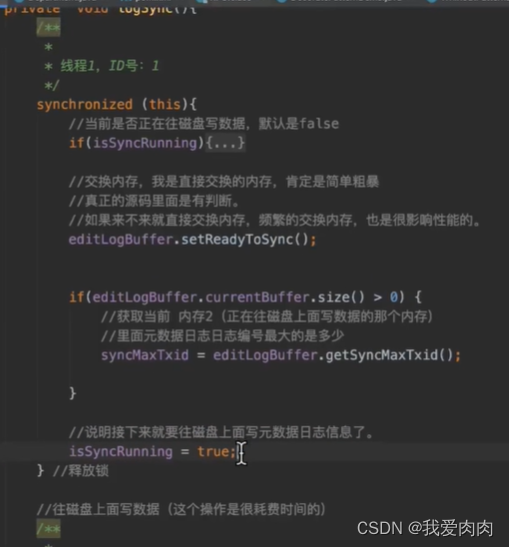
如下图:
如果isSyncRunning为true也就是正在执行写磁盘操作时,会判断当前txid是否<=最大threadlocal txid,
如果小于等于最大txid则直接return,因为正在执行写磁盘的操作已经包含了该数据。(批处理)
如果大于最大txid,则boolean isWaitSync查看是否为第一个超过最大id数据,如果不是第一个直接return,
如果是第一个,则线程wait等待2秒或者前面磁盘写完后notify唤醒,isWaitSync改为true让后面大id直接return,
因为下一次线程唤醒写磁盘可以直接包含这次后面所有大id的数据
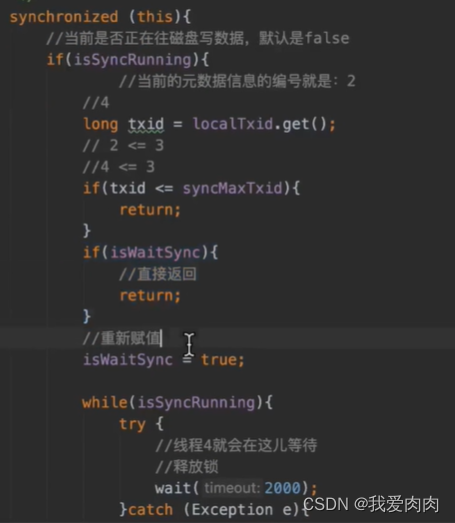
第三步写磁盘实现思路
flush 最耗费时间的写磁盘操作没有加锁,分段加锁相互不影响

测试运行结果
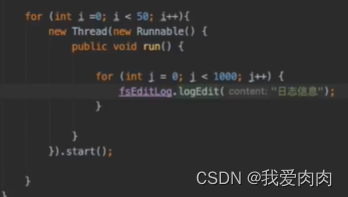
50个线程,每个线程1000个请求。测试结果很快
写元数据备注:
1 实际源码中内存写磁盘的同时也要写入jouralnode内存中做SNN同步数据
2 无论内存写磁盘还是写jouralnode都使用双缓存方案
2 两块内存CurrentBuffer和SyncBuffer默认512mb
可看如下图NameNode元数据更新流程
NameNode元数据更新流程
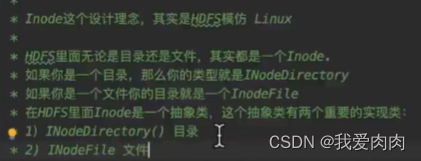
HDFS文件目录设计
文件目录创建方式:调用NameNodeRpcServer接口的相关目录方法,父目录下.addChild(node,low)的目录树形式
FSDirectory 是一个直接在内存内的数据结构,也就是内存目录树
FsNameSystem作用是把元数据记录持久化到磁盘上

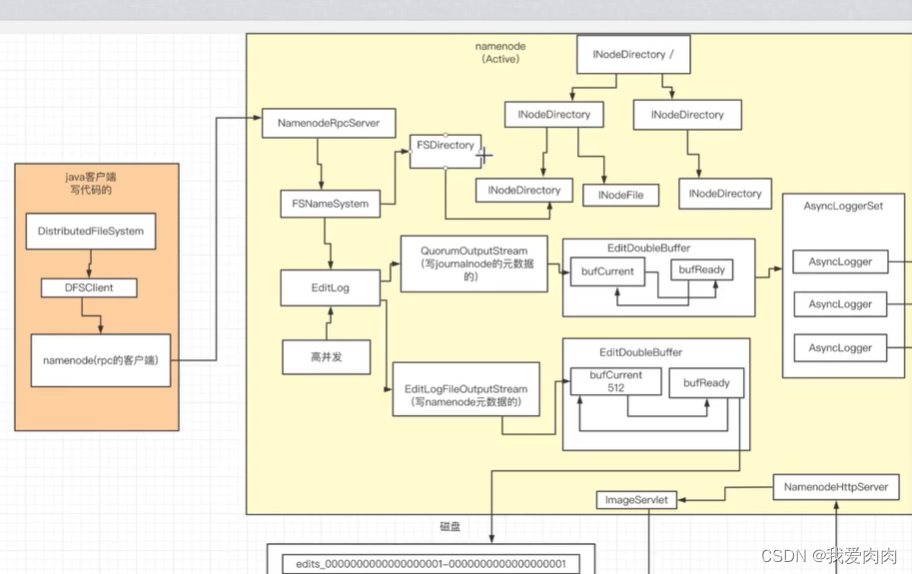
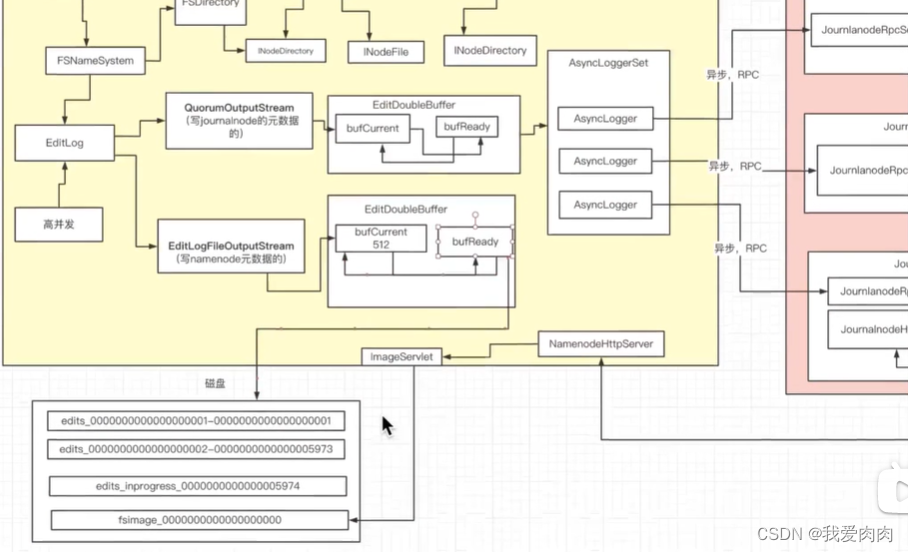
NameNode active 通过journalnode 同步 NameNode standby
1 standby namenode通过发送http请求,jounrnalnode servlet doGet实现流对烤形式传输磁盘日志
2 条件判断checkpoint合并文件,如下图
3 异步线程fsimage替换namenode active fsimage,通过http请求做数据流对烤
如果大量的数据请求通过http方式,如果简单的方法调用通过hadoop RPC方式
















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











