







1.Hadoop集群搭建
1.1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
那mapreduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
1.2集群部署方式
Hadoop部署方式分三种:
1.2.1standalone mode(独立模式)
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
1.2.2Pseudo-Distributed mode(伪分布式模式)
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
1.2.3Cluster mode(群集模式)
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
1.2.4Hadoop集群架构模型
第一种:NameNode与ResourceManager单节点架构模型
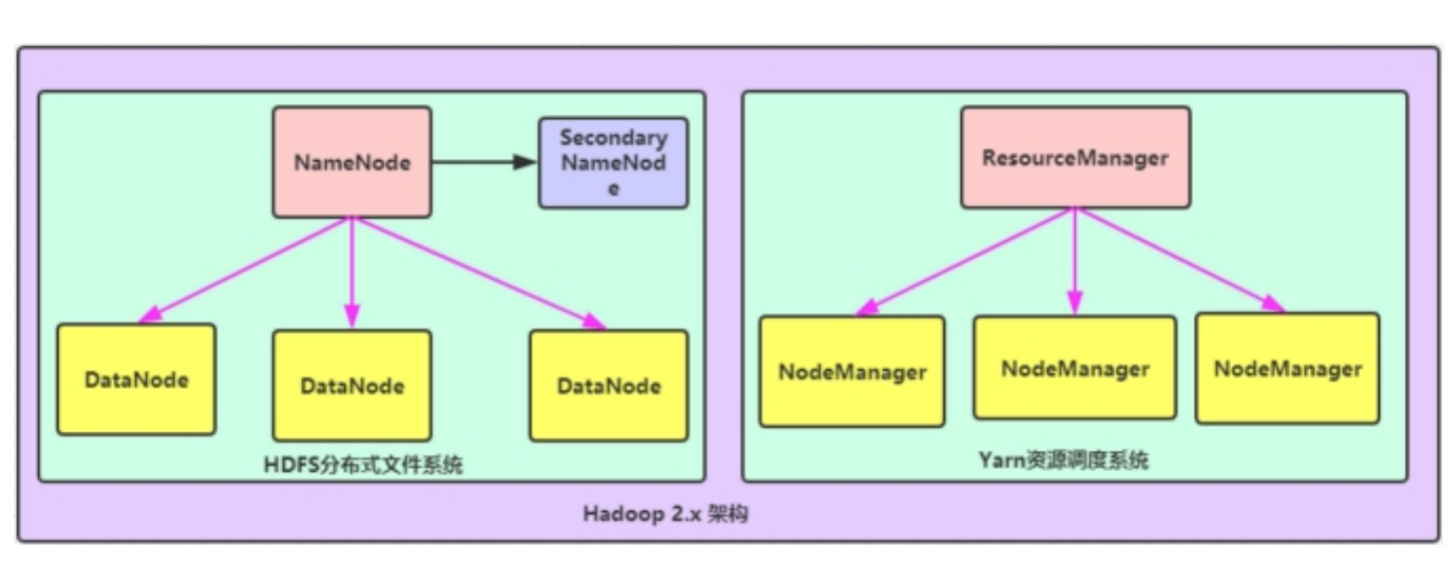
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集ZQ据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点APPmaster分配的任务
第二种:NameNode高可用与ResourceManager单节点架构模型
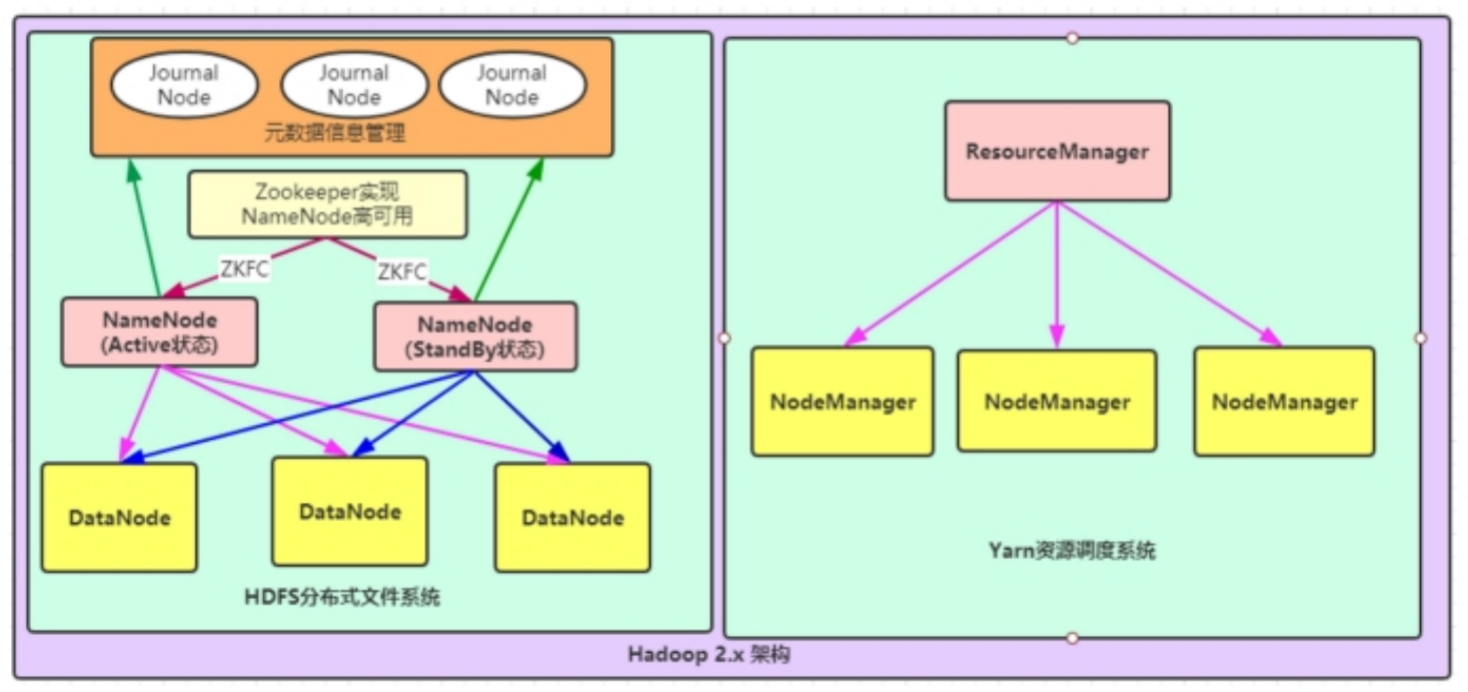
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,其中NameNode可以有两个,形成高可用状态
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
JournalNode:文件系统元数据信息管理
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分
NodeManager:负责执行主节点ResourceManager分配的任务
第三种:NameNode单节点与ResourceManager高可用架构模型
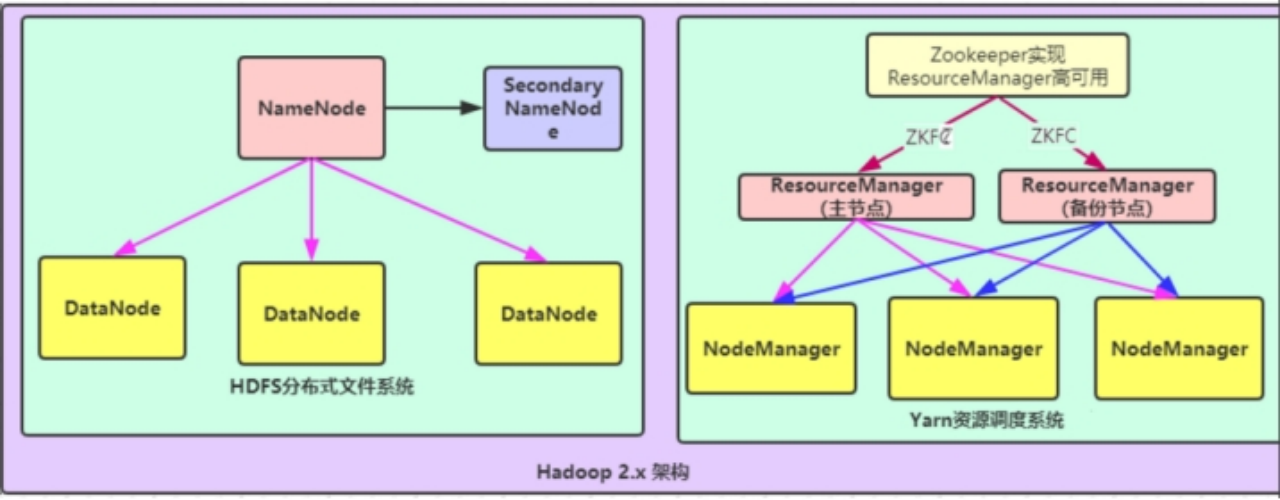
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分,通过zookeeper实现ResourceManager的高可用
NodeManager:负责执行主节点ResourceManager分配的任务
第四种:NameNode与ResourceManager高可用架构模型
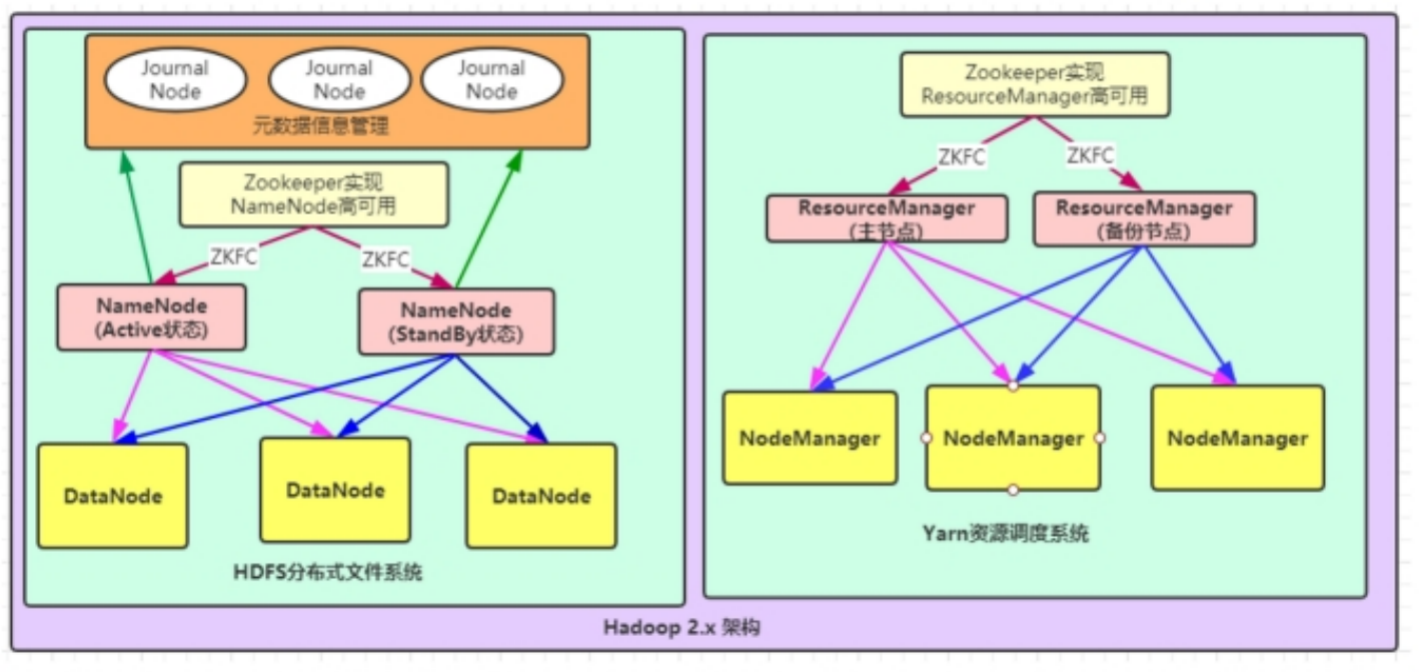
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
JournalNode:元数据信息管理进程,一般都是奇数个
DataNode:从节点,用于数据的存储
数据计算核心模块:
ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用
NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
1.2.5集群规划
以三台主机为例,以下是集群规划:Hadoopn集群安装
集群模式主要用于生产环境部署,需要多台主机,并且这些主机之间可以相互访问,我们在之前搭建好基础环境的三台虚拟机上进行Hadoop的搭建。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3593
3593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









