






本文提出了一个逻辑一致的预测损失,LCPLoss,以帮助学习跨属性的逻辑一致性,以及标签补偿训练策略,以消除跨一组相关属性的无正预测的问题。
Logical Consistency and Greater Descriptive Power for Facial Hair Attribute Learning
此项工作来自于 University of Notre Dame, Computer Vision Research Lab (CVRL)
论文链接: https://arxiv.org/pdf/2302.11102.pdf
代码: https://github.com/HaiyuWu/LogicalConsistency
人脸属性在人脸匹配/识别 (face matching/recognition),人脸图像检索(face retrieval),重新识别(re-identification),用于面部属性编辑(face editing),以及其他领域中得到了广泛的应用。然而脸部毛发作为面部的一个重要属性,目前为止并未引起足够的关注。其中一个原因是,目前存在的数据集,如 CelebA, LFWA, PubFig, CelebV-HQ, MAAD-Face等都只有简单的二元分类(有或者没有)。这种单一的标签无法支持更深入的面部属性研究。
其次,基于我们之前对于CelebA数据集的研究(论文链接:https://arxiv.org/pdf/2210.07356.pdf),我们发现无论是标签的精度还是数据标注的一致性,此数据集都有较大问题。最重要的是,此数据集的标签存在一定的逻辑错误。比如,一张图片拥有女性(Male=False)和有胡须(No_Beard=False)或者有刘海(Bangs=True)和发际线后移(Receding Hairline=True)等。
基于上述两点,本文旨在解决:1)脸部毛发属性标签细粒度不足的问题,2)探究在多标签分类上模型的预测结果的逻辑一致性。
FH37K数据集
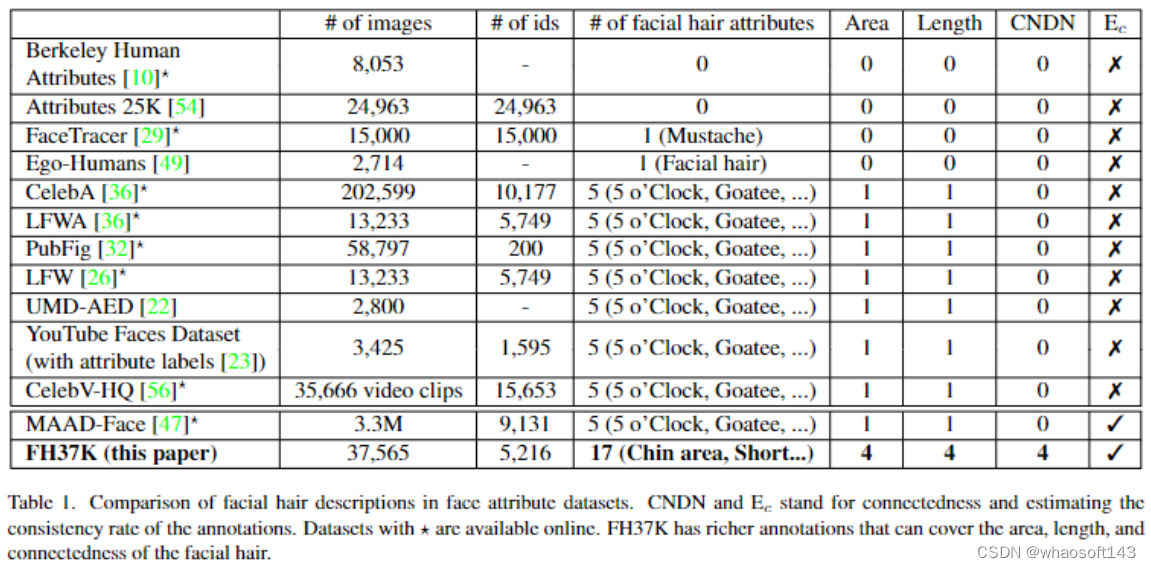
现存的人脸属性数据集对于脸部毛发的描述仅有 5 o'clock shadow , Goatee, Mustache, No Beard, Sideburns。为了能够描述更加丰富的脸部毛发类型,我们从长度,区域和连接性出发设计了17个跟脸部毛发相关的属性。其中4个关于长度(5 o'clock shadow, short, medium, long),4个关于区域(clean shaven, chin area, side to side, information not visible), 4个关于属性之间的连接性(mustache-connected to beard, sideburns-connected to beard, mustache-isolated, sideburns present)。为了能够描述更复杂的“野外”(in-the-wild)的场景,我们引入了信息不可见(information not visible)属性,并且用任意区域属性加信息不可见属性来描述下图所示的场景。

我们还提供了更丰富的秃发描述(bald-false, bald-top only, bald-sides only, bald-top and sides, bald-information not visible)。关于属性的详细定义,可以阅读原文和阅读Github链接里提供的文档。为了确保标签的可靠性,我们为一个未参与标注过程但是仔细阅读过我们属性定义的文档的人标注随机选择的1000张图片,最终他标注的结果与我们的ground truth label有94.05%是一致的。
属性之间的逻辑关系
现存的人脸属性数据集如CelebA,LFWA,PubFig等已经得到了广泛的研究,然而属性之间的逻辑关系,如互不共存(No Beard=True, Goatee=True)和依赖(Wavy hair=True, Bald=False)却从未得到过关注。当模型在一个拥有逻辑矛盾的数据集上训练后,它所预测的结果是不可靠的。因此,我们罗列出了FH37K数据集面部毛发属性的所有逻辑关系,如下图所示:

除了互不共存(mutually exclusive)和依赖(Dependency)之外,因为我们的属性可以涵盖它所描述的维度的一切可能性,比如胡子区域必定是(clean shaven, chin area, side to side, information not visible)其中的一种或者是其中一种与 information not visible 的组合,我们每一组属性之间还具有一种新的逻辑关系:穷尽(必定存在一个正标签(组合)可以描述当前图片)。基于上述逻辑关系我们对标签进行了进一步的优化,以提高基于此数据集训练出的分类器的可靠性,也为我们之后的预测结果分析提供了条件基础。
预测结果的逻辑一致性
我们使用ResNet50和三种常用的多标签分类损失函数基于我们的数据集进行了训练,
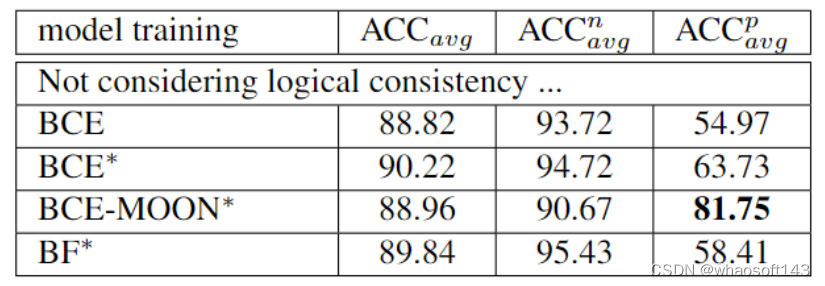
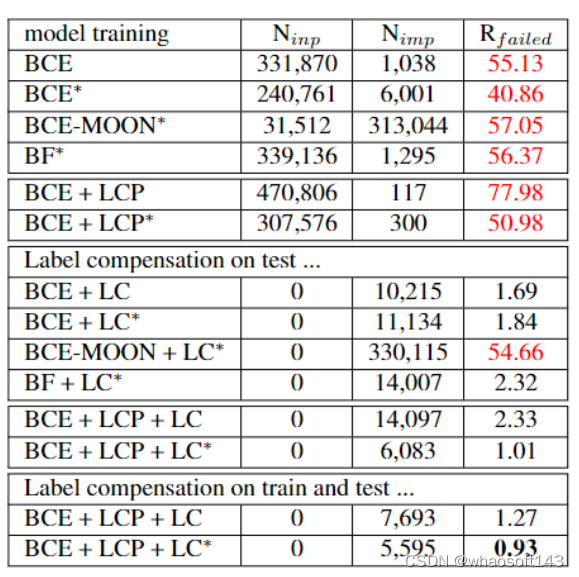
其中BCE指的是Binary Cross Entropy Loss,BCE-MOON指的是基于MOON loss对于BCE loss进行改进的方法(MOON loss是用于解决正负标签不平衡问题提出的损失函数),BF指的是Binary Focal loss,*代表的是使用迁移学习方法。从结果上可以看出,在不考虑逻辑一致性的前提下,所有损失函数都能达到~90%的精确度,而BCE-MOON更是在正样本上达到了81.75%的精确度。然而,当我们使用之前的逻辑条件来重新衡量预测精度时,即不符合逻辑的预测都为失败,我们可以看到近乎一半的“正确”预测都不符合逻辑。
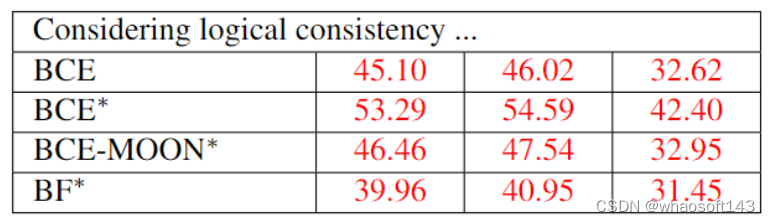
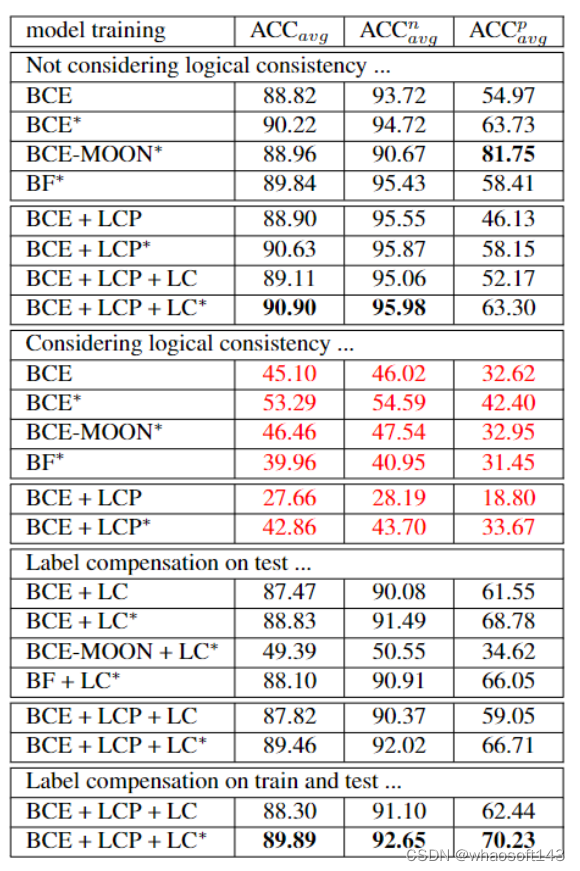
于是为了让分类器预测正确并且符合逻辑的标签,我们提出了 logical consistency prediction loss (LCPloss)和 label compensation strategy。其中LCPloss是用于限制模型预测出不可能出现的(impossible)标签组合,公式如下:

如上图所示,当预测中有一个维度的没有正标签的时候(也就是置信度都低于阈值的时候),我们选择将这组属性里置信度最高的属性改为正标签。这一方法完美解决了 incomplete 的情况。
实验结果
实验证明我们的方法可以在考虑逻辑关系的前提下达到最好的精度。并且当我们将label compensation strategy应用到其他方法上时,除了BCE-MOON,其他方法的精度都有了大幅提升。这表明,基于拥有正确逻辑关系的训练集训练出的模型可以学习到标签之间的逻辑模式。
为了验证我们的方法在现实场景下的预测逻辑结果,我们选取了WebFace260M的前30000个人,共60万张图片,进行面部毛发属性预测。结果显示我们的方法拥有最低的失败率。并且,值得注意的是,BCE-MOON作为一个用于解决正负标签不平衡/长尾问题(long-tail problem)的方法,从结果上看,只是迫使模型预测出更多的正标签以提高整体在正标签上的精度。
应用
我们使用此分类研究了胡须区域对于人脸识别精度的影响,结果表明,当两个人拥有相同的胡须区域属性的时候,相似度会上升,而拥有不同胡须区域属性的时候相似度会下降。有趣的是,对于不同人种,每个胡须区域属性的影响是不同的。详情请阅读原文。
研究方向
此工作揭示了属性间逻辑关系的重要性,以下仅是部分可能的未来研究方向,希望我们的工作可以启发更多的相关后续工作:
- 在保持预测结果逻辑性的前提下,进一步提升各个属性的正样本精度。
- 因为我们的方法需要手动去设定逻辑关系从而对模型训练加以限制,所以如何能够自动检测属性之间的逻辑关系在训练中并加以限制也是一个非常重要的方向。
- 对于面部毛发在人脸验证(face verification),人脸识别(face identification),等方向中的影响也十分的重要。
- 对于长尾问题(long-tail problem),在提高在稀有属性的正样本预测精确度的前提下还需要考虑逻辑一致性。这也是一个可研究的方向。
- 对于任何多标签分类的数据集和模型,它的ground truth label和预测结果都必须要符合逻辑。所以,在别的数据集上探究逻辑一致性的问题是一个可研究的放向。















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









