






类似Hadoop,Spark也有自己的history server,这里我们就来配置下:
- 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
- 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://KengicCluster/SparkLogDir
注意:需要启动Hadoop集群,并且这个目录要提前存在!!!(hadoop fs -mkdir /SparkLogDir)
- 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://KengicCluster/SparkLogDir -Dspark.history.retainedApplications=30"
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 为了从 Yarn 上关联到 Spark 历史服务器,需要配置关联路径——修改spark-defaults.conf
spark.yarn.historyServer.address=cdh-01:18080
spark.history.ui.port=18080
- 集群每个节点同步配置文件
xsync spark-defaults.conf
xsync spark-env.sh
- 启动history服务
sbin/start-history-server.sh
- 提交一个job,看看效果
./bin/spark-submit --master yarn --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.11-2.4.6.jar 3
登录cdh-01:18080,即使job运行完毕,也可以看到job运行结果和日志:
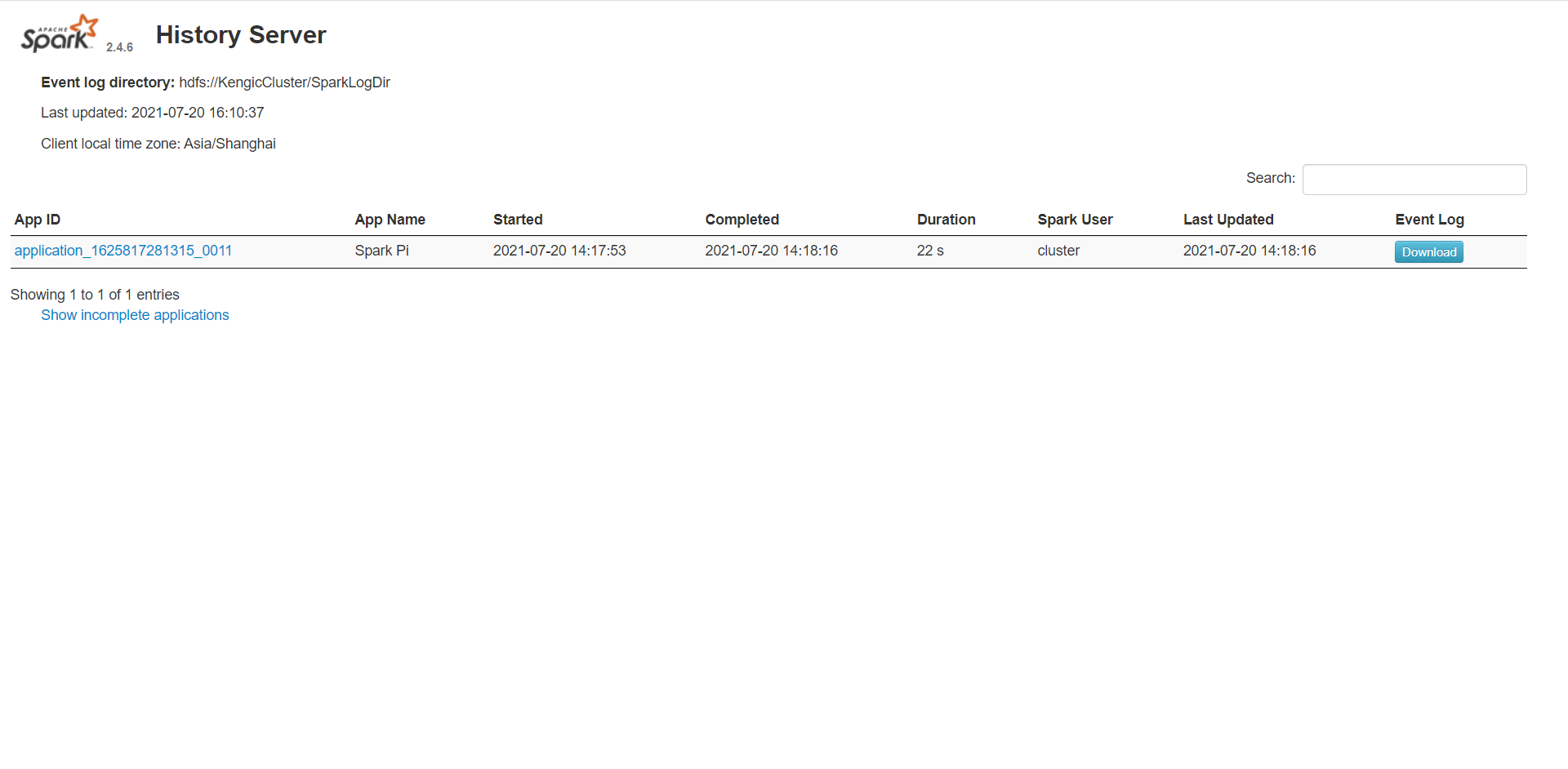
登录cdh-01:8080,也可以从Yarn上面进入job:
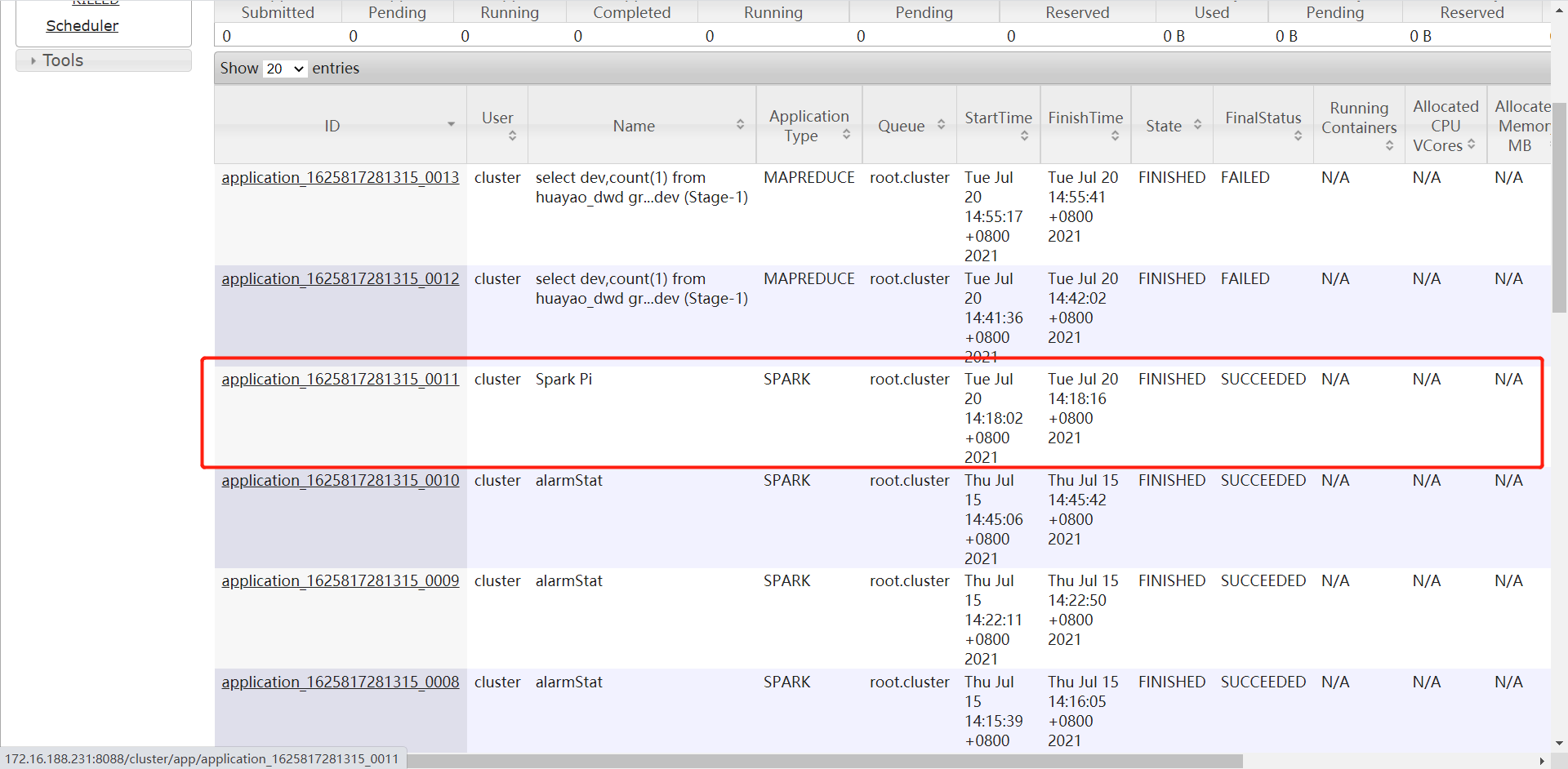
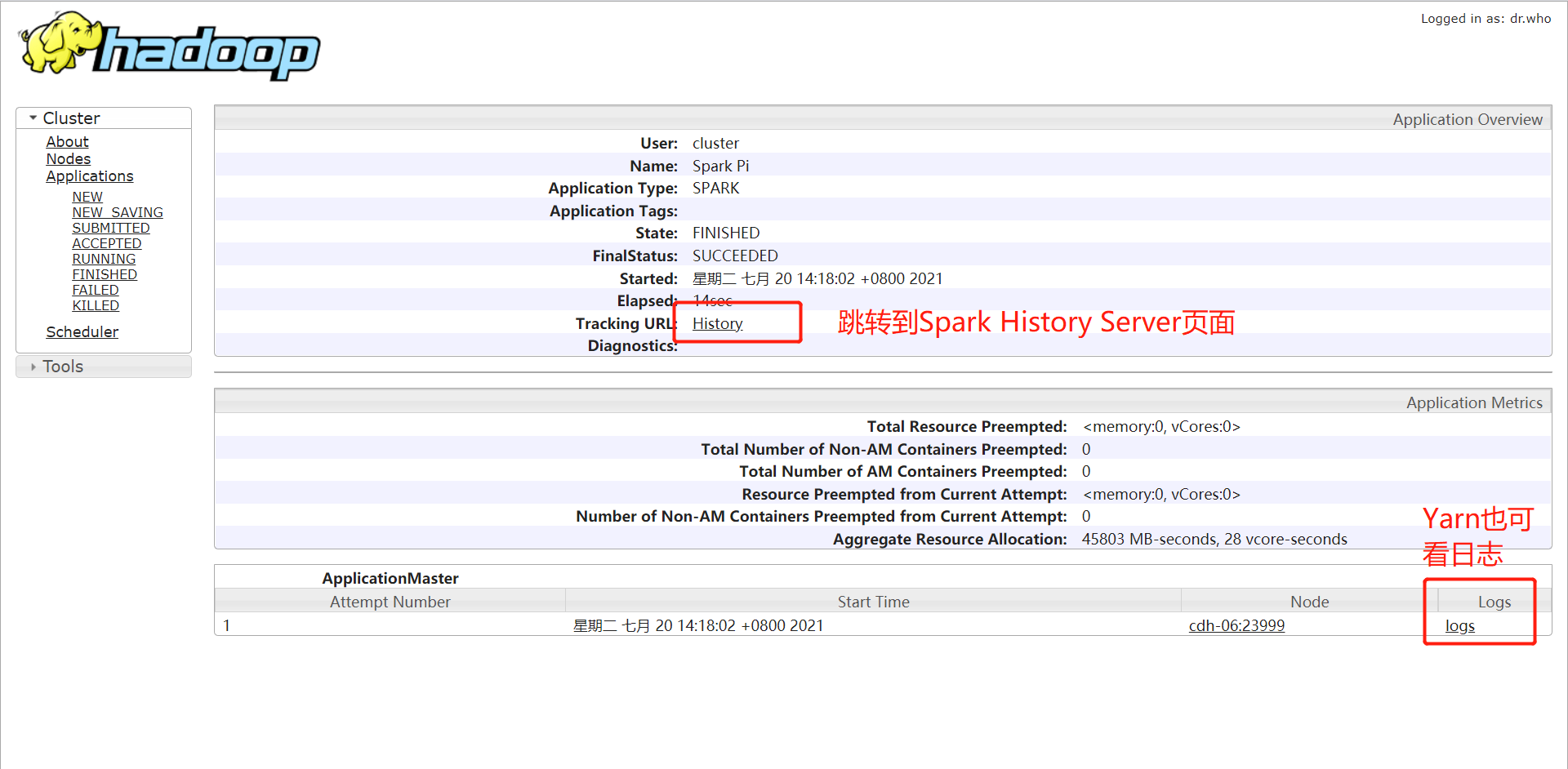
进入application具体页面后:














 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









