







 本文围绕Kubernetes多网卡方案之Multus CNI展开。先介绍其出现背景,当单网卡难以满足业务需求时,Multus CNI成为常用方案。接着阐述其为符合CNI规范的开源插件,可与其他插件搭配。还详细说明了部署过程,结合calico和flannel实现多网卡,最后进行了启动pod测试。
本文围绕Kubernetes多网卡方案之Multus CNI展开。先介绍其出现背景,当单网卡难以满足业务需求时,Multus CNI成为常用方案。接着阐述其为符合CNI规范的开源插件,可与其他插件搭配。还详细说明了部署过程,结合calico和flannel实现多网卡,最后进行了启动pod测试。
kubernetes 多网卡方案之 Multus_CNI 部署以及基本使用
一、multus cni 出现的背景
在k8s的环境中启动一个容器,默认情况下只存在两个虚拟网络接口(loopback 和 eth0), loopback 的流量始终都会在本容器内或本机循环,对业务起到支撑作用的是 eth0,能够满足大部分的业务场景。
但是当一个应用或服务既需要对外提供 API 调用服务,也需要满足自身基于分布式特性产生的数据同步(一些业务场景的控制面和数据面的分离场景),那么这时候一张网卡的性能显然很难达到生产级别的要求,网络流量延时、阻塞便成为此应用的一项瓶颈。
为了实现生产环境的实际需求,出现了许多容器多网络方案。根据开源社区活跃度、是否实现 CNI 规范以及稳定性,大部分场景使用 multus-cni 作为在 K8s 环境下的容器多网络方案。
二、multus cni 介绍
Multus CNI 是一种符合CNI规范的开源插件,为实现 K8s环境下容器多网卡而提出的解决方案并与其他 CNI 插件搭配使用。Multus CNI 本身不提供网络配置功能,它是通过用其他满足 CNI 规范的插件进行容器的网络配置。
如下图所示,当集群环境存在 Multus CNI 插件并添加额外配置后,将会发现此容器内不再仅有 eth0 接口
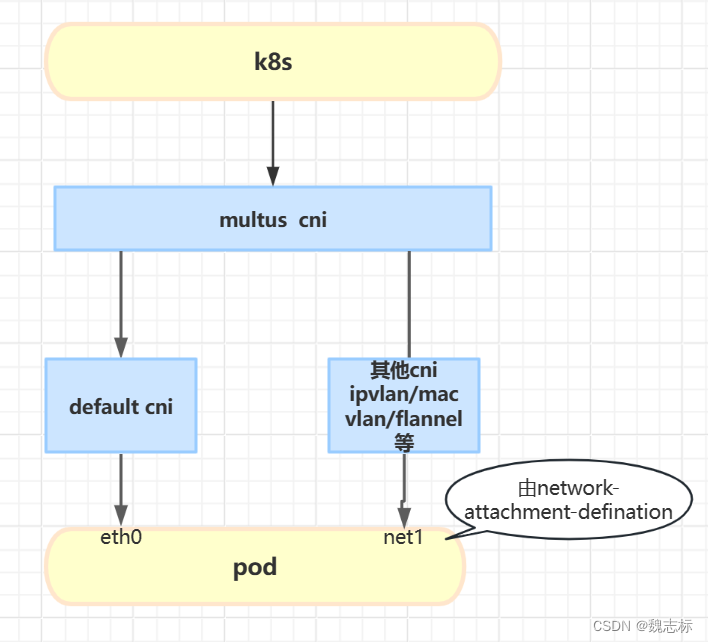
CNI 是一组限于容器网络面的规范,定义了容器网络资源创建、管理的规则。其自身实现并提供了内置且通用的网络插件,同时为第三方实现其规范预留了扩展。
cni类型如下:
| 类型 | 作用 | 插件 |
|---|---|---|
| Main | 负责容器接口(网桥、虚拟网卡)的创建 | bridge、ipvlan、macvlan、ptp等 |
| Ipam | pod Ip地址的分配管理 | host-local、dhcp、calico-ipam、static等 |
| Meta | 用于和第三方插件适配扩展应用或则内核参数调整 | tuning、bandwidth、portmap等 |
以上可以得知,Multus CNI 属于 Meta 类, 它可以与其他第三方插件适配,主插件来作为 Pod 的主网络并且被 K8s所感知,它们可以搭配使用且不冲突。
Main 插件是用于在集群中创建额外的网络:
1:bridge:创建基于网桥的额外网络可让同一主机中的 Pod 相互通信,并与主机通信。
2:host-device:创建 host-device 额外网络可让 Pod 访问主机系统上的物理以太网网络设备。
3:macvlan:创建基于 macvlan 的额外网络可让主机上的 Pod 通过使用物理网络接口与其他主机和那些主机上的 Pod 通信。附加到基于 macvlan 的额外网络的每个 Pod 都会获得一个唯一的 MAC 地址。
4:ipvlan:创建基于 ipvlan 的额外网络可让主机上的 Pod 与其他主机和那些主机上的 Pod 通信,这类似于基于 macvlan 的额外网络。与基于 macvlan 的额外网络不同,每个 Pod 共享与父级物理网络接口相同的 MAC 地址。
5:SR-IOV:创建基于 SR-IOV 的额外网络可让 Pod 附加到主机系统上支持 SR-IOV 的硬件的虚拟功能 (VF) 接口。
###############################################################
Ipam(IP Address Management)插件主要用来负责分配 IP 地址:
1:dhcp插件,节点上需要有 DHCP server;
2:host-local插件 ,是给定子网范围,在单个几点上基于这个子网进行 ip 地址分配;
3:static插件,静态地址管理,直接指定 ip 地址使用的。
4:calico-ipam ,是 clalico cni 自己的 ip 地址分配插件,是一种集中式 ip 分配插件;
5:whereabouts ,也是一个集中式 ip 分配插件,用的比较少,使用了 sriov 设备才用到的,这个是 k8snetworkplumbingwg 社区开源的。
###########################################
Meta 插件:由 CNI 社区维护的内部插件
1:flannel,这就是专门为 Flannel 项目提供的 CNI 插件;
2:tunning,是一个通过 sysctl 调整网络设备参数的二进制文件;
3:portmap ,是一个通过 iptables 配置端口映射的二进制文件;
4:bandwidth ,是一个使用 Token Bucket Filter(TBF)来进行限流的二进制文件;
5:calico,是专门为 Calico 项目提供的 CNI 插件。
三、multus cni 部署
本次测试环境中使用的主cni为calico,网络模式是ipip模式,如下:
[root@node1 ~]# kubectl get po -A | grep calico
kube-system calico-kube-controllers-75c594996d-x49mw 1/1 Running 5 (13d ago) 206d
kube-system calico-node-htq5b 1/1 Running 1 (13d ago) 206d
kube-system calico-node-x6xwl 1/1 Running 1 (13d ago) 206d
kube-system calico-node-xdx46 1/1 Running 1 (13d ago) 206d
#######查看IPIPMODE为Always
[root@node1 ~]# calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED DISABLEBGPEXPORT SELECTOR
default-ipv4-ippool 10.233.64.0/18 true Always Never false false all()
下载multus cni文件部署multus 服务
1: 克隆文件
git clone https://github.com/k8snetworkplumbingwg/multus-cni.git && cd multus-cni/deployments
##################################
2:部署服务
[root@node1 deployments]# kubectl apply -f multus-daemonset-thick.yml
customresourcedefinition.apiextensions.k8s.io/network-attachment-definitions.k8s.cni.cncf.io changed
clusterrole.rbac.authorization.k8s.io/multus changed
clusterrolebinding.rbac.authorization.k8s.io/multus changed
serviceaccount/multus changed
configmap/multus-daemon-config changed
daemonset.apps/kube-multus-ds created
[root@node1 deployments]#
#################################
3:查看multus服务是否正常
[root@node1 ~]# kubectl get ds -n kube-system | grep multus
kube-multus-ds 3 3 3 3 3 <none> 44s
[root@node1 ~]#
[root@node1 ~]# kubectl get po -o wide -n kube-system | grep multus
kube-multus-ds-fqdxg 1/1 Running 0 53s 192.168.5.126 node2 <none> <none>
kube-multus-ds-gx2c7 1/1 Running 0 53s 192.168.5.27 node3 <none> <none>
kube-multus-ds-z2j4n 1/1 Running 0 53s 192.168.5.79 node1 <none> <none>
[root@node1 ~]#
multus cni作为ds 进程,会在每个节点做已下操作
1:在每个节点运行multus-daemon进程
[root@node1 net.d]# ps -ef | grep multus
root 25811 25696 0 18:33 ? 00:00:00 /usr/src/multus-cni/bin/multus-daemon
root 31445 14072 0 18:43 pts/0 00:00:00 grep --color=auto multus
[root@node1 net.d]#
#################################
2:在每个节点的/opt/cni/bin/上生成一个 Multus 二进制可执行文件。可执行文件的作用是配置 Pod 的网络栈,DaemonSet 的作用是实现网络互通。
[root@node1 net.d]# ll /opt/cni/bin/ | grep multus
-rwxr-xr-x 1 root root 45946850 Nov 1 18:33 multus-shim
[root@node1 net.d]#
注意:一个 Network Namespace 的网络栈包括:网卡(Network interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。
##########################
3:在每个节点的/etc/cni/net.d目录下生成00-multus.conf,如下:
[root@node1 net.d]# cat 00-multus.conf | jq .
{
"capabilities": {
"bandwidth": true,
"portMappings": true
},
"cniVersion": "0.3.1",
"logLevel": "verbose",
"logToStderr": true,
"name": "multus-cni-network",
"clusterNetwork": "/host/etc/cni/net.d/10-calico.conflist", ##从此文件读取集群calico网络配置(版本不一样,文件内容可能会有差异,以自己环境为准)
"type": "multus-shim"
}
至此multus cni的部署已经完成,接下来需要测试使用,网上的一些教程使用的大部分是macvlan的形式,比较简单。本次我们打算使用calico和flannel两种cni相结合的方式来实现pod 的多网卡方案。
四、环境信息
已有环境的信息如下:
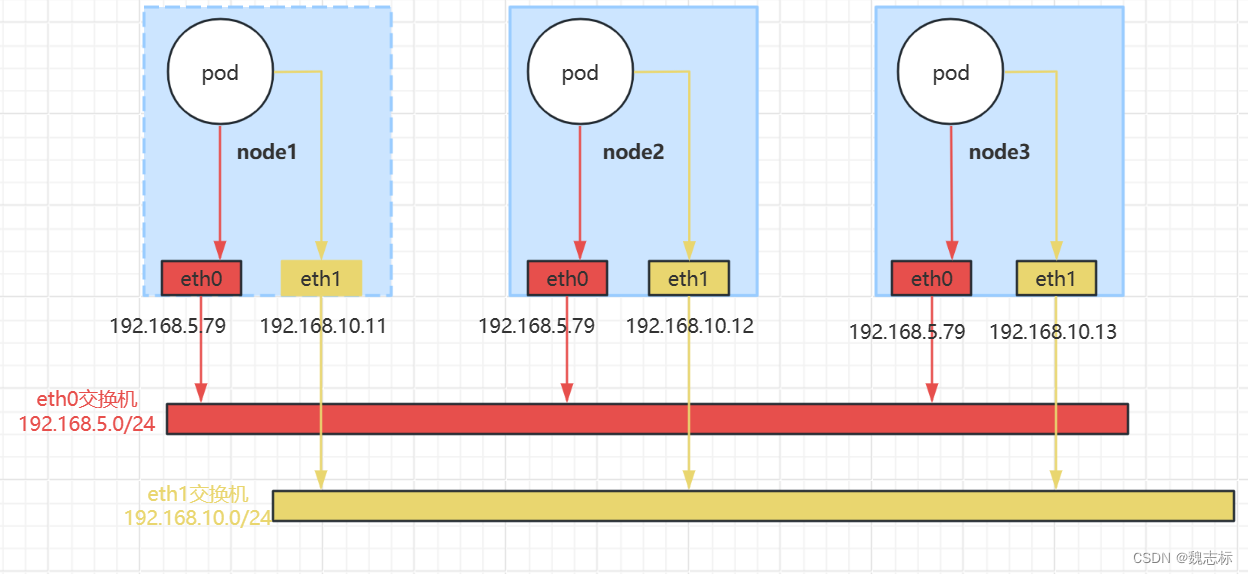
calico网络作为master plugin,走eth0网卡;flannel网络作为attachment网络,走eth1网卡
| 主机 | eth0 | eth1 |
|---|---|---|
| node1 | 192.168.5.79 | 192.168.10.11 |
| node2 | 192.168.5.126 | 192.168.10.12 |
| node3 | 192.168.5.27 | 192.168.10.13 |
每个节点使用eth0作为默认路由
[root@node1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.5.1 0.0.0.0 UG 0 0 0 eth0
10.233.90.0 0.0.0.0 255.255.255.0 U 0 0 0 *
10.233.90.1 0.0.0.0 255.255.255.255 UH 0 0 0 cali41f400bfcca
10.233.92.0 192.168.5.27 255.255.255.0 UG 0 0 0 tunl0
10.233.96.0 192.168.5.126 255.255.255.0 UG 0 0 0 tunl0
169.254.169.254 192.168.10.2 255.255.255.255 UGH 0 0 0 eth1
192.168.5.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.10.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
主机网络拓扑如下:
五、flannel部署
- 下载yaml文件
在主机运行wget下载flannel的yaml 文件
[root@node1 ~]# wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
- 修改启动参数
1:此次是calico和flannel网络分离使用不同的网卡,所以要修改flannel网络使用的网卡为eth1
编辑flannel.yaml文件,添加如下内容
containers:
- name: kube-flannel
image: docker.io/flannel/flannel:v0.22.3
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=eth1 ####设置使用网卡为eth1
#######################################3
2:修改网络,避免和现有的calico以及物理网络冲突
net-conf.json: |
{
"Network": "10.233.0.0/16",
"Backend": {
"Type": "vxlan" ###网络模式为vxlan
}
}
- 部署flannel
1:部署flannel
[root@node1 ~]# kubectl apply -f flannel.yaml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
[root@node1 ~]#
#################################
2:查看pod启动状态
[root@node1 ~]# kubectl get po -A -o wide | grep flannel
kube-flannel kube-flannel-ds-6tkzg 1/1 Running 0 3m39s 192.168.5.126 node2 <none> <none>
kube-flannel kube-flannel-ds-72ccp 1/1 Running 0 5m20s 192.168.5.79 node1 <none> <none>
kube-flannel kube-flannel-ds-gvhlc 1/1 Running 0 3m47s 192.168.5.27 node3 <none> <none>
[root@node1 ~]#
###########################
3:查看flannel的启动日志
[root@node1 ~]# kubectl logs kube-flannel-ds-6tkzg -n kube-flannel
Defaulted container "kube-flannel" out of: kube-flannel, install-cni-plugin (init), install-cni (init)
I1102 03:07:31.013498 1 main.go:212] CLI flags config: {etcdEndpoints:http://127.0.0.1:4001,http://127.0.0.1:2379 etcdPrefix:/coreos.com/network etcdKeyfile: etcdCertfile: etcdCAFile: etcdUsername: etcdPassword: version:false kubeSubnetMgr:true kubeApiUrl: kubeAnnotationPrefix:flannel.alpha.coreos.com kubeConfigFile: iface:[eth1] ifaceRegex:[] ipMasq:true ifaceCanReach: subnetFile:/run/flannel/subnet.env publicIP: publicIPv6: subnetLeaseRenewMargin:60 healthzIP:0.0.0.0 healthzPort:0 iptablesResyncSeconds:5 iptablesForwardRules:true netConfPath:/etc/kube-flannel/net-conf.json setNodeNetworkUnavailable:true useMultiClusterCidr:false}
W1102 03:07:31.013748 1 client_config.go:617] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I1102 03:07:31.133998 1 kube.go:145] Waiting 10m0s for node controller to sync
I1102 03:07:31.134230 1 kube.go:490] Starting kube subnet manager
I1102 03:07:31.145860 1 kube.go:511] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.233.64.0/24]
I1102 03:07:31.146023 1 kube.go:511] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.233.66.0/24]
I1102 03:07:32.134217 1 kube.go:152] Node controller sync successful
I1102 03:07:32.134272 1 main.go:232] Created subnet manager: Kubernetes Subnet Manager - node2
I1102 03:07:32.134290 1 main.go:235] Installing signal handlers
I1102 03:07:32.134579 1 main.go:543] Found network config - Backend type: vxlan
I1102 03:07:32.135308 1 match.go:259] Using interface with name eth1 and address 192.168.10.12
I1102 03:07:32.135345 1 match.go:281] Defaulting external address to interface address (192.168.10.12)
I1102 03:07:32.135446 1 vxlan.go:141] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
W1102 03:07:32.178714 1 main.go:596] no subnet found for key: FLANNEL_SUBNET in file: /run/flannel/subnet.env
I1102 03:07:32.178731 1 main.go:482] Current network or subnet (10.233.0.0/16, 10.233.65.0/24) is not equal to previous one (0.0.0.0/0, 0.0.0.0/0), trying to recycle old iptables rules
I1102 03:07:32.181267 1 kube.go:511] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.233.65.0/24]
I1102 03:07:32.229373 1 main.go:357] Setting up masking rules
I1102 03:07:32.232287 1 main.go:408] Changing default FORWARD chain policy to ACCEPT
I1102 03:07:32.234353 1 iptables.go:290] generated 7 rules
I1102 03:07:32.236378 1 main.go:436] Wrote subnet file to /run/flannel/subnet.env
I1102 03:07:32.236397 1 main.go:440] Running backend.
I1102 03:07:32.236791 1 iptables.go:290] generated 3 rules
I1102 03:07:32.236913 1 vxlan_network.go:65] watching for new subnet leases
###########################
4:确认各个节点flannel插件以及网络正常
[root@node1 ~]# ll /opt/cni/bin/ | grep flannel
-rwxr-xr-x 1 root root 2414517 Nov 2 11:03 flannel ###会在每个节点生成flannel的二进制文件
[root@node1 ~]# cat /var/run/flannel/subnet.env ###每个节点可用网络的CIDR
FLANNEL_NETWORK=10.233.0.0/16
FLANNEL_SUBNET=10.233.64.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
[root@node1 ~]#
[root@node1 ~]# ip a ###在每个节点多了一个flannel.1的网桥
49: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether d2:7e:4a:31:fe:e9 brd ff:ff:ff:ff:ff:ff
inet 10.233.64.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::d07e:4aff:fe31:fee9/64 scope link
valid_lft forever preferred_lft forever
#############################################
5:创建NetworkAttachmentDefinition
编辑yaml文件内容如下:
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: flannel
spec:
config: '{
"cniVersion": "0.3.0",
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": false #这里要设为false,否则flannel会在容器里面添加默认路由,走flannel生成的net1网卡;因为calico使用了默认网卡eth0,所以容器里面的默认路由也要走calico生成的容器网卡
}
}'
[root@node1 ~]# kubectl apply -f flannel-nad.yaml
networkattachmentdefinition.k8s.cni.cncf.io/flannel created
[root@node1 ~]#
[root@node1 ~]# kubectl get Network-Attachment-Definition -A
NAMESPACE NAME AGE
default flannel 27s
六、修改calico网络使用网卡
因为环境在最初之前已经部署了calico,是按照calico网络默认方式选择的可用的ip地址,因为这次要测试流量分离所以最好要修改下。
calico选择ip的方式有两种
1:first-found:第一个接口的第一个有效IP地址,会排除docker网络,localhost。我们环境中有两个网卡,所以要选择一个有效的的网卡
2:can-reach=DESTINATION:可以理解为calico会从部署节点路由中获取到达目的ip或者域名的源ip地址
我们检查下目前calico使用的是哪种模式如下:
[root@node1 ~]# kubectl get ds -n kube-system | grep calico
calico-node 3 3 3 3 3 kubernetes.io/os=linux 207d
[root@node1 ~]#
###查看calico daemonset中IP_AUTODETECTION_METHOD 配置
[root@node1 ~]# kubectl get ds/calico-node -n kube-system -o yaml
- name: IP_AUTODETECTION_METHOD
value: can-reach=$(NODEIP) ###可以看到使用是can-reach方式,将本机eth0的ip作为流量网卡使用
####进入pod查看环境变量,如下:
[root@node1 ~]# kubectl exec -it calico-node-htq5b -nkube-system bash
[root@node1 /]# env | grep IP_AUTODETECTION_METHOD
IP_AUTODETECTION_METHOD=can-reach=192.168.5.79 ###可以看到是本机eth0的ip
[root@node1 /]#
修改calico使用指定网卡eth0
有以下两种方式
1:命令行执行替换变量
[root@node1 ~]# kubectl set env daemonset/calico-node -n kube-system IP_AUTODETECTION_METHOD=interface=eth0
daemonset.apps/calico-node env updated
####修改完之后,pod自动重启如下:
[root@node1 ~]# kubectl get pod -n kube-system | grep calico
calico-kube-controllers-75c594996d-x49mw 1/1 Running 5 (13d ago) 207d
calico-node-749ll 1/1 Running 0 12s
calico-node-hbz99 1/1 Running 0 33s
calico-node-lgpcj 1/1 Running 0 43s
##############################################
2:编辑daemonset ,如下:
[root@node1 ~]# kubectl edit daemonset/calico-node -n kube-system
- name: IP_AUTODETECTION_METHOD
value: interface=eth0 ###修改为eth0 ,效果和上面一样,pod会自动重启
###############################################
3:进入pod,查看是否生效
[root@node1 ~]# kubectl exec -it calico-node-749ll -nkube-system bash
[root@node3 /]# env | grep IP_AUTODETECTION_METHOD
IP_AUTODETECTION_METHOD=interface=eth0 ###变量已经生效
[root@node3 /]#
[root@node3 /]#
七、启动pod测试
1:编辑pod yaml,如下:
---
apiVersion: v1
kind: Pod
metadata:
name: nginx
annotations:
k8s.v1.cni.cncf.io/networks: flannel
spec:
containers:
- name: nginx
image: docker.io/library/nginx:latest
imagePullPolicy: IfNotPresent
######################################################
2:启动pod,查看状态
[root@node1 ~]# kubectl apply -f pod.yaml
pod/nginx created
[root@node1 ~]# kubectl get po -o wide ###默认显示的还是calico的网络
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 8s 172.16.28.2 node3 <none> <none>
######################################################
3:此pod位于node3节点,ssh到node3,进入pod命名空间查看ip以及路由问题
[root@node3 ~]# crictl ps | grep nginx
fcfbae2ace1b9 12766a6745eea 4 minutes ago Running nginx 0 0365e4a0f167f nginx
[root@node3 ~]# crictl inspect fcfbae2ace1b9 | grep -i pid
"pid": 23237,
"pid": 1
"type": "pid"
[root@node3 ~]# nsenter -t 23237 -n bash
[root@node3 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if79: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether ea:25:5b:31:e1:69 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.28.2/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::e825:5bff:fe31:e169/64 scope link
valid_lft forever preferred_lft forever
6: net1@if81: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether ea:86:51:86:34:69 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.233.66.2/24 brd 10.233.66.255 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::e886:51ff:fe86:3469/64 scope link
valid_lft forever preferred_lft forever
net1就是使用flannel网络获取到的ip地址
################################################################
4:查看容器中的路由
[root@node3 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
10.233.0.0 10.233.66.1 255.255.0.0 UG 0 0 0 net1
10.233.66.0 0.0.0.0 255.255.255.0 U 0 0 0 net1
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
[root@node3 ~]#
以上可以看到默认路由是容器内部的eth0 ,走的物理机网卡的eth0
测试网络是否可通,在容器的宿主机node3上测试两个ip地址都可以通
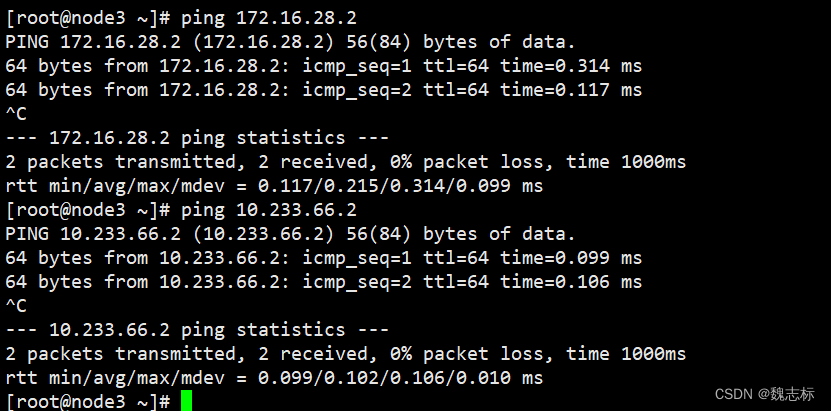
从其他物理节点测试,calico网络172段的可通,flannel的不可达,因为pod默认路由走的eth0.
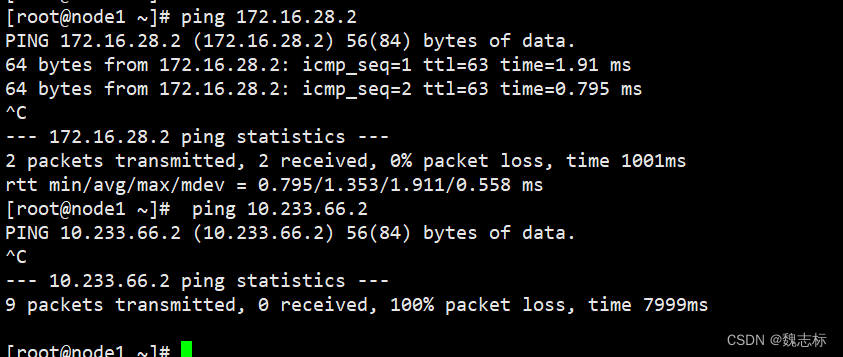
在创建一个pod,测试不同主机之间的pod能否互通
[root@node1 ~]# kubectl get po -o wide ###新建nginx2,位于node2节点
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 32m 172.16.28.2 node3 <none> <none>
nginx2 1/1 Running 0 3m45s 172.16.44.1 node2 <none> <none>
进入nginx2容器,ping nginx容器ip,如下:
[root@node2 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if85: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether 56:9b:fe:a4:da:5a brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.44.1/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::549b:feff:fea4:da5a/64 scope link
valid_lft forever preferred_lft forever
6: net1@if87: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether a6:41:e5:f8:b1:25 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.233.65.2/24 brd 10.233.65.255 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::a441:e5ff:fef8:b125/64 scope link
valid_lft forever preferred_lft forever
[root@node2 ~]# ping 10.233.65.2 ##测试容器本身ip
PING 10.233.65.2 (10.233.65.2) 56(84) bytes of data.
64 bytes from 10.233.65.2: icmp_seq=1 ttl=64 time=0.141 ms
^C
--- 10.233.65.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.141/0.141/0.141/0.000 ms
[root@node2 ~]# ping 10.233.66.2 ###测试node3节点ip,可通
PING 10.233.66.2 (10.233.66.2) 56(84) bytes of data.
64 bytes from 10.233.66.2: icmp_seq=1 ttl=62 time=4.77 ms
64 bytes from 10.233.66.2: icmp_seq=2 ttl=62 time=1.00 ms
^C
--- 10.233.66.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 1.001/2.889/4.777/1.888 ms
注意:在该环境中,如果使用networkpolicy,是能对容器的eth0显示,并不能显示net1网卡的流量策略,因为flannel本身不支持networkpolicy功能。

















 1946
1946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









