










引言
接着上一篇所介绍的自然语言处理中的几种处理算法,以及模型的评价标准,在这一篇里就着重讲数据的读取。众所周知,在自然语言处理就是要预先读取数据,并分析里数据想表达的意思,所以数据的读取就尤为重要了,特别是在数据分析、挖掘那一块。
使用不了jupyter botebook的读取
不知道什么原因,无法使用jupyter notebook,所以只能在.py文件处理数据了。这里载入的数据集是文新闻文本类数据,分为两列,一列label,一列text,里面不同的中文字符映射为不同的数字。
载入数据集
import pandas as pd
dictKey = {'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13}
train_df = pd.read_csv('train_set.csv', sep='\t', nrows=100)
print(train_df.head())
这里因为数据太大了,有将近20w条,一次性载入内存打印出来的话压力还不小,所以这里这输出100条,需要输出全部的话只需把 nrows=100去掉就可以了。
另外可以通过train_df.head()来查看前五行,函数里的行数默认为5,当然你可以在函数里设置打印的行数。

使用describe分析
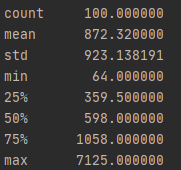
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())
你可以通过train_df[‘text_len’]=…来为df表格赋予新的一列。
pandas中可以很方便地查看数据的最大值、最小值、均值等等这些指标,只需要调用describe这个函数就可以了。但是在这里,因为原先的数据只有label和text,不好查看前面我们所说的那些均值、最大值指标,所以我们需要先要新定义一列,这一列就为text文本的长度吧。
比较高级的describe()
describe()函数只能够查看这些中规中矩的指标,我们也可以自己编写函数,来获取数据集的峰值,中位数,四分位距,变异系数等等。不过这里df的列好像也没几个适合获取中位数、变异系数这些。所以,你可以在另外的数据集中使用。
def get_con(df):
subsets = ['text_len']
data={}
for i in subsets:
data.setdefault(i, [])
data[i].append(df[i].skew())
data[i].append(df[i].kurt())
data[i].append(df[i].mean())
data[i].append(df[i].std())
data[i].append(df[i].std()/df[i].mean())
data[i].append(df[i].max()-df[i].min())
data[i].append(df[i].quantile(0.75)-df[i].quantile(0.25)) #分位数
data[i].append(df[i].median())
data_df = pd.DataFrame(data, index=['偏度', '峰度', '均值', '标准差', '变异系数', '极差', '四分位距', '中位数'], columns=subsets)
return data_df.T
# 保存为csv文件
df2=get_con(train_df)
df2.to_csv('eval.csv')
df中的统计数数功能
counts = train_df['label'].value_counts().tolist() #100条
print(counts )
比方说,我们想记录一下这一百条里,娱乐类新闻有多少,社会类新闻有多少,就可以使用上面的语句了。结果输出为:

我们也可以查看在这么多文章中,是哪几个字符比较多,哪几个字符比较少。
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse=True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse=True)
print(word_count[0])
print(word_count[1])
print(word_count[2])
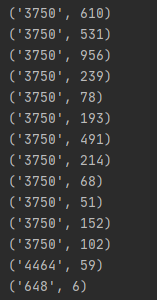
经过上面的程序,我们发现‘3750’字符出现的次数最多,有3702次,而最少的字符只有一次,叫‘5034’。
以及通过打印word_count[0],word_count[1],word_count[2],也可以分别看出出现最多的前三字符是哪几个。
数据处理分析的神器,画图
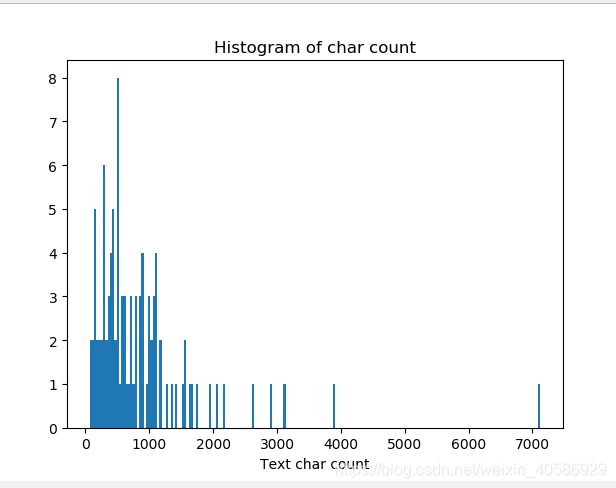
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count")
plt.show()
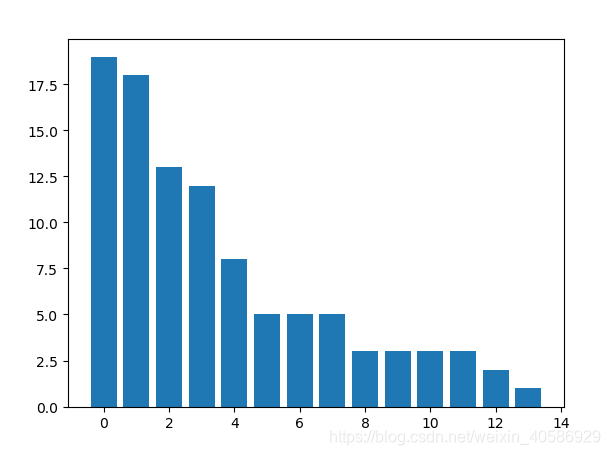
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")
plt.show()
'''
或者这样
plt.bar([i for i in range(len(counts ))], counts)
plt.show()
'''
如果我们只是单单看数字,这样就很枯燥并且不易理解,那么将数据可视化的应用就应运而生了,python中自带一个库matplotlib就是专门为数据可视化而来。它和numpy,pandas称为三剑客。
在这里,我们使用这个库来可视化不同新闻类别的个数统计以及一篇文章中字符总数的统计。
其他操作
我们发现,‘3750’,‘900’,‘648’这几个字符出现频率较高,所以初步推断出它们可能是标点符号。那么我就在想,那么我们可以通过这几个标点符号,来断句。
那么,一篇文章大概是由多少个句子组成的呢?下面我们来揭晓!
sentenceCount = 0
for i in range(len(train_df)):
split1 = train_df['text'][i].split('3750')
for j in range(len(split1)):
split2 = split1[j].split(' 900 ')
for k in range(len(split2)):
split3 = split2[k].split(' 648 ')
sentenceCount += 1
print("average sentences in each news are : ", sentenceCount / 100)
注意我们这里考虑到可能出现3900,3646,2648,1900这种字符,所以在900,648前后加了空格来加以区分,避免错误处理了其他字符。但是感觉这是个骚操作,不知道大家还有什么其他更好的方法呢?

另外,如果我们想统计每一类新闻中,出现次数最多的字符,那么又应该怎么做呢?
groupInfo = train_df[['label', 'text']].groupby('label').count() #首先先进行分组
# print(groupInfo)
for i in range(len(groupInfo)):
classes = train_df[train_df['label'] == i]
# print("classes['text']")
# print(classes['text'])
allText = ''.join(list(classes['text']))
word_count = Counter(allText.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse=True)
print(word_count[0]) #你也可以打印word_count全部信息或者出现第二多,出现最少的字符
结果发现好像还是‘3750’,‘648’这些字符居多

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









