







导入第三方库和模型
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
2、创建画图函数
def draw_result(train_x, labels, cents, title):
n_clusters = np.unique(labels).shape[0]#获取类别个数
color = ["red", "orange", "yellow"]
plt.figure()#创建一个新的图形窗口并开始绘图
plt.title(title)
for i in range(n_clusters):#range(3)=range(0,3):0,1,2
current_data = train_x[labels == i]#把标签一致得所有样本点全拿出来
plt.scatter(current_data[:, 0], current_data[:,1], c=color[i])#只显示鸢尾花第一个指标和第二个指标的值
plt.scatter(cents[i, 0], cents[i, 1], c="blue", marker="*", s=100)#显示中心的的样本
return plt
""" 画出聚类后的图像
labels: 聚类后的label, 从0开始的数字
cents: 质心坐标
n_cluster: 聚类后簇的数量
color: 每一簇的颜色
"""
3、主函数调用kmeans
if __name__ == '__main__':
iris = datasets.load_iris()#加载鸢尾花数据集
iris_x = iris.data#数据部分,不带标签
clf = KMeans(n_clusters=3, max_iter=10,n_init=10, init="k-means++",
algorithm="full", tol=1e-4,n_jobs= -1,random_state=1)#创建聚类模型
clf.fit(iris_x)#把样本150数据全部应用于聚类函数
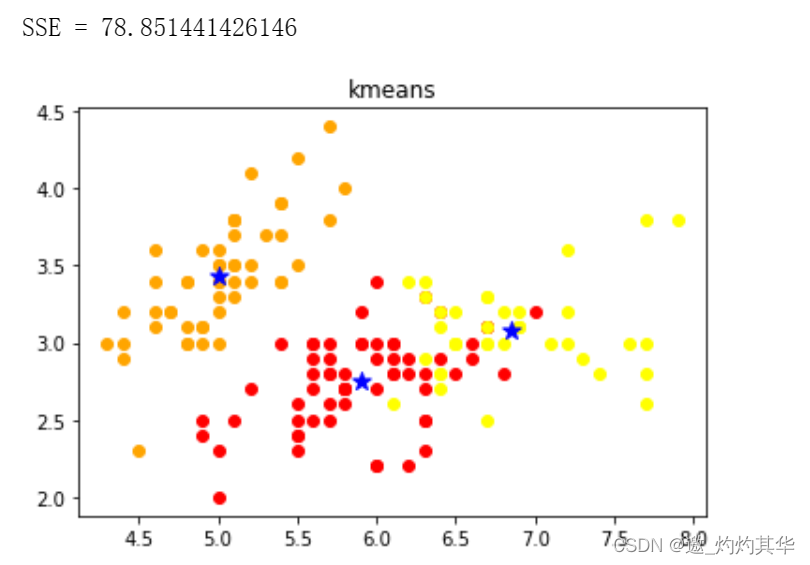
print("SSE = {0}".format(clf.inertia_))
#inertia_ 属性表示聚类效果的评估指标,也称为簇内离差平方和(within-cluster sum of squares, WCSS)。它表示每个样本点到其所属簇的质心的距离的总和,该值越小表示样本点越接近于自己的簇中心,聚类效果越好。
draw_result(iris_x, clf.labels_, clf.cluster_centers_, "kmeans").show()#plt.show() 显示图形
'''
iris_x:样本数据
clf.labels_聚类聚出来的标签
clf.cluster_centers_聚类出来的中心点
"kmeans" 画图的标题
'''
4、算法优缺点
优点
简洁明了,计算复杂度低。 K-means 的原理非常容易理解,整个计算过程与数学推理也不是很困 难。
收敛速度较快。通常经过几个轮次的迭代之后就可以获得还不错的效果。
缺点
结果不稳定。 由于初始值随机设定,以及数据的分布情况,每次学习的结果往往会有一些差异。 无法解决样本不均衡的问题。
对于类别数据量差距较大的情况无法进行判断。 容易收敛到局部最优解。 在局部最优解的时候,迭代无法引起中心点的变化,迭代将结束。
受噪声影响较大。 如果存在一些噪声数据,会影响均值的计算,进而引起聚类的效果偏差。















 7119
7119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









