




 本文介绍目标检测算法发展历程,包括R-CNN、Fast R-CNN、Faster R-CNN及FPN+Faster R-CNN等Two-Stage算法。涵盖候选区域生成、深度网络特征提取、分类与回归等内容。
本文介绍目标检测算法发展历程,包括R-CNN、Fast R-CNN、Faster R-CNN及FPN+Faster R-CNN等Two-Stage算法。涵盖候选区域生成、深度网络特征提取、分类与回归等内容。
参考来源:太阳花的小绿豆的博客_CSDN博客-深度学习,软件安装,Tensorflow领域博主
【OpenMMLab 公开课】目标检测与 MMDetection 上
目录
1. 目标检测任务简介
目标检测任务主要有两个问题需要解决:识别目标类别(分类),确定目标位置(回归)。分类问题很好理解,就是确定检测到的目标属于哪一类。回归问题是为了确定目标的位置,因为我们需要一个矩形框来框住所检测到的目标,这就需要调整矩形框的中心坐标以及宽和高到最优的位置,坐标点以及宽和高的变化是连续的,因此是回归问题。基于深度学习的目标检测算法主要分为两类Two Stage 和 One Stage。本文主要介绍Two、Stage算法
- Two Stage算法有:R-CNN、Fast R-CNN、Faster R-CNN、SPPNet
- One Stage算法有:YOLO系列、SSD、RetinaNet、SqueezeDet、DetectNet、OverFeat
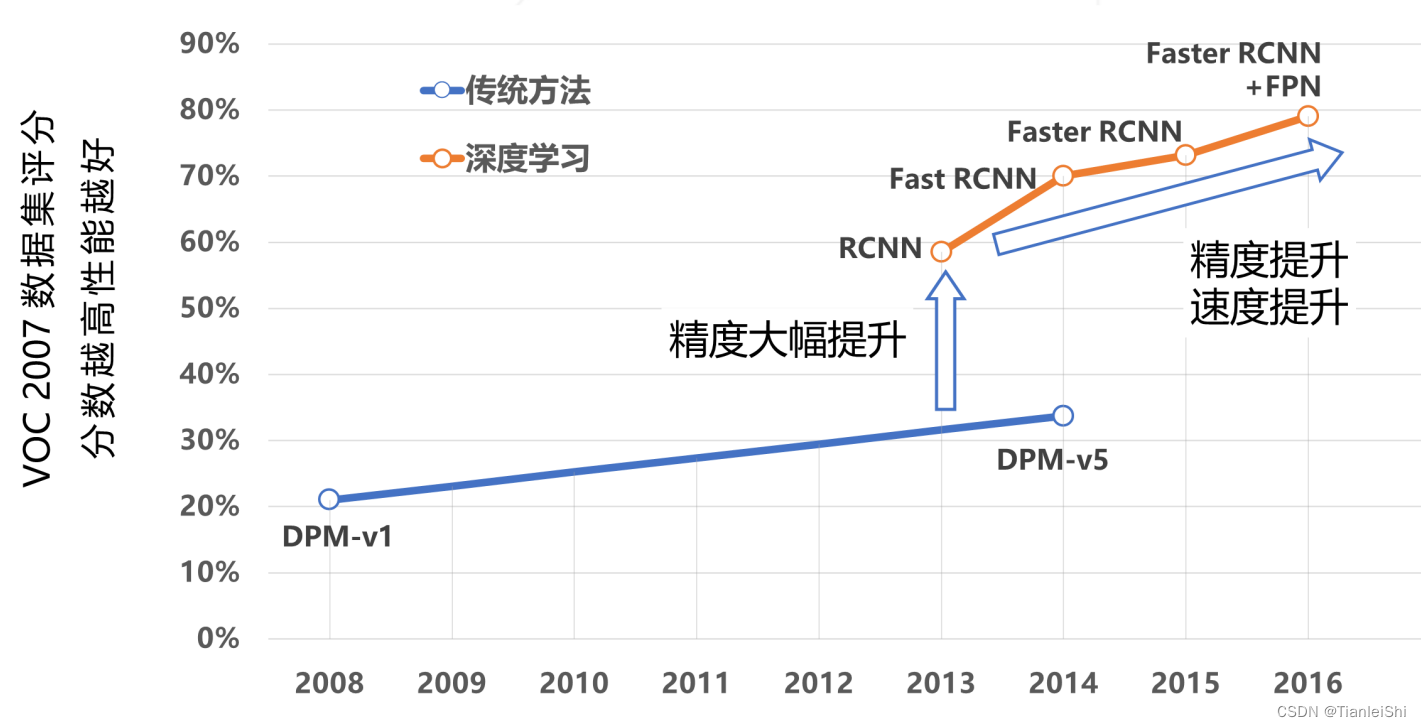
1.1 早期的目标检测思路演化过程
- 最早基于分类任务,人们想到可以对图像进行窗口切分,分别对每一个小窗口分类,然后检测结果 = (分类结果,图像窗的位置),但是该方法过于粗糙,无法检测分块边界上的物体
- 后来就想到基于滑窗(sliding windows)进行检测,也就是使用重叠的窗口,可以覆盖更多可能出现物体的位置,但是会发现滑窗边界与物体精确边界仍有很大误差
- 这就引入了边界框回归(多任务学习的概念,同时进行分类和回归任务)
- 但是又出现了多尺度问题,也就是说在同一幅图片里面物体有大有小,长宽比不同
- 有人提出使用大小、长宽比不同的滑窗
- 另外的思路可以改变图像的大小(将图像缩放到不同大小,构建图像金字塔)
1.2 密集预测的效率问题
- 滑窗其实相当于是在空间是做密集的预测(检测一张图像,要进行数万次分类预测),难以满足实时检测需求,为此提出了Region Rroposal(区域提议)策略
- 大量窗口都落在不包含物体的边界区域。
- 可以先通过简单快速的方法找出可能包含物体的区域
- SS算法:使用贪心算法,将空间相邻且特征相似的图像块逐步合并到一起,形成可能包含物体的区域,称为提议区域或提议框
2. R-CNN网络(2014年)
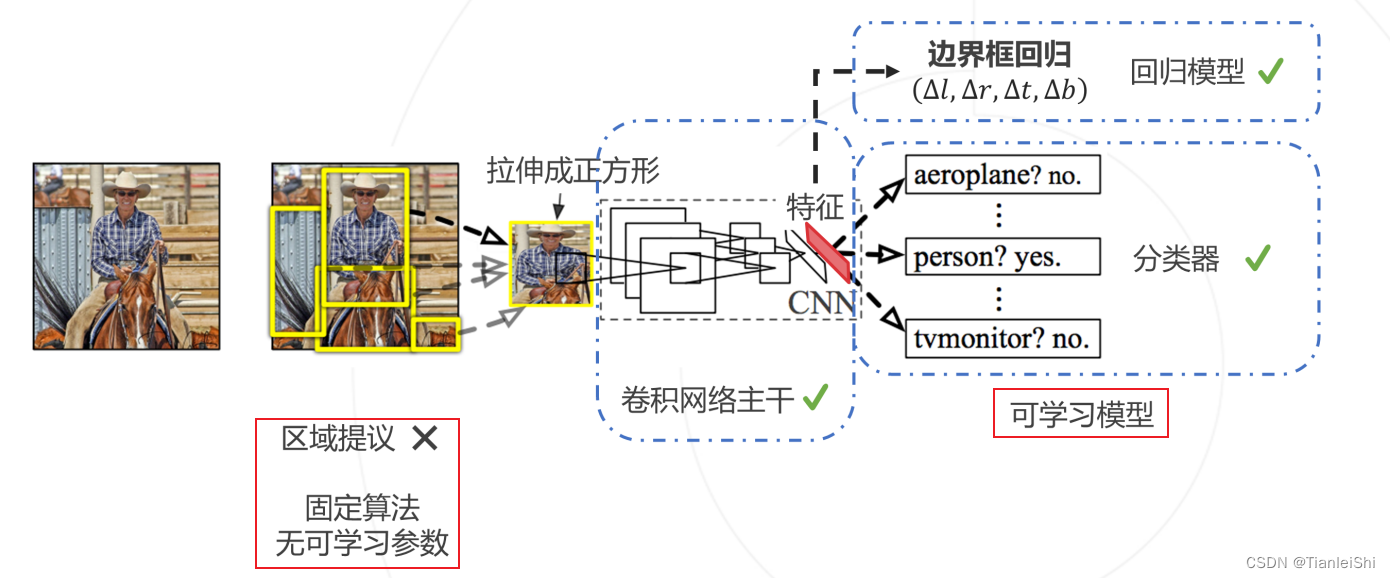
2.1 算法流程及存在问题
- 算法流程
- 使用SS算法,将一张图像生成1k到2k个候选区域(proposal)
- 对每个候选区域,使用深度网络(Backnone:AlexNet)提取特征
- 将特征送入每一类的SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
- 存在问题:
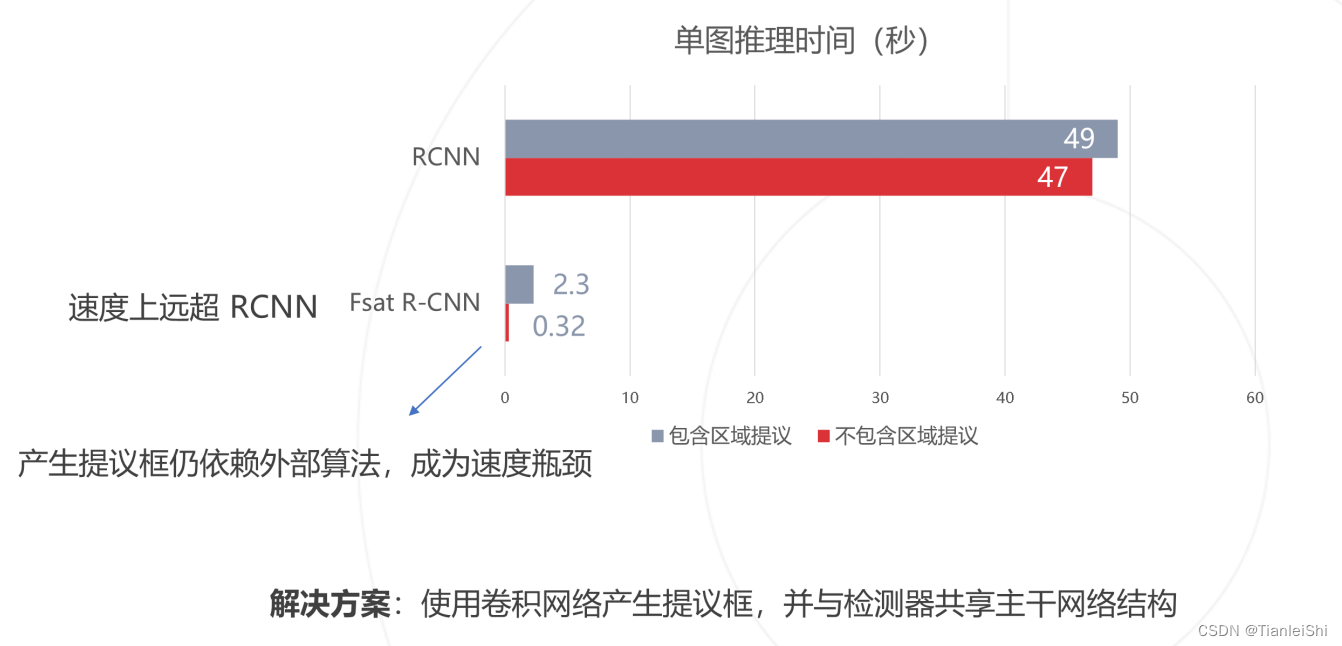
- CPU上测试一张图片大约53s。用SS算法提取候选框需要2s,一张图像内候选框之间存在大量重叠,提取特征操作冗余
- 过程比较繁琐,并且需要分别训练特征提取网络、SVM分类模型、回归模型
- 训练所需空间大:对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07训练集上的5k图像上提取的而调整需要数百GB的存储空间
2.2 候选区生成(SS算法)
SS算法:首先使用图像分割策略分割出可能的前景(目标)区域,即原始区域,这里同一个目标会有很多冗余的框,采用合并策略剔除冗余的原始区域,得到层次化的区域结构,即候选区域
- 一张图像使用SS算法大约可以得到2k张候选区域
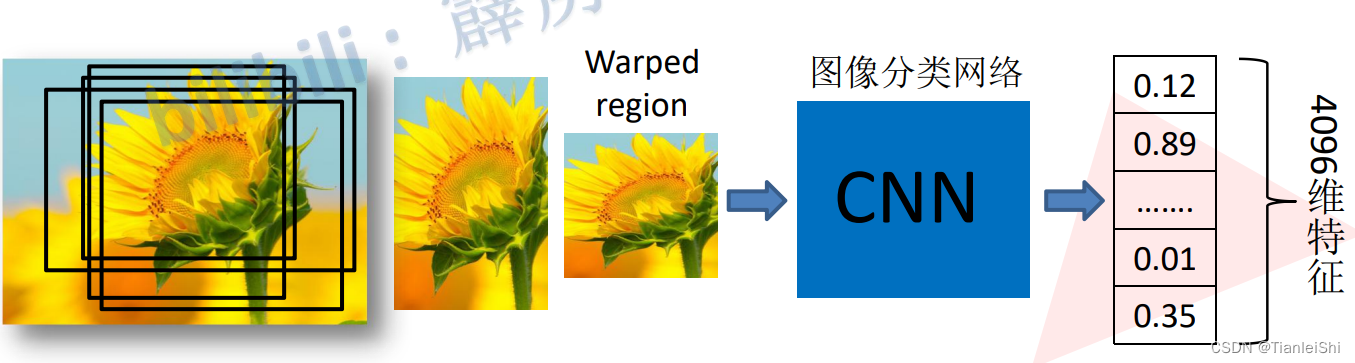
2.3 深度网络提取特征
- Warped Region,将候选区域缩放到227*227pixel
- 接着输入分类网络AlexNet(事先训练好),获得4096维的特征,特征矩阵:2k*4096
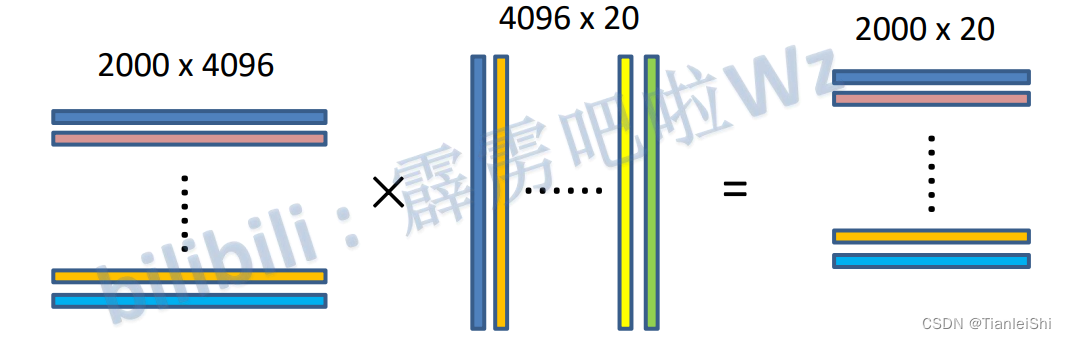
2.4 SVM分类器
- 将2000×4096维特征与20个SVM组成的权值矩阵4096×20(事先训练好)相乘, 获得2000×20维概率矩阵,每一行代表一个建议框归于每个目标的概率。
- 分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框
非极大值抑制剔除重叠建议框 (NMS):IoU(Intersection over Union)表示两个区域的交并比,越大说明重合度越高,通过计算IoU,若大于给定阈值,则说明为同一物体,剔除该框

2.5 回归器修正候选框位置
-
对NMS处理后剩余的建议框进一步筛选。接着分别用20个回归器(事先训练好)对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的 bounding box

2.6 R-CNN以后两阶段方法的改进思路
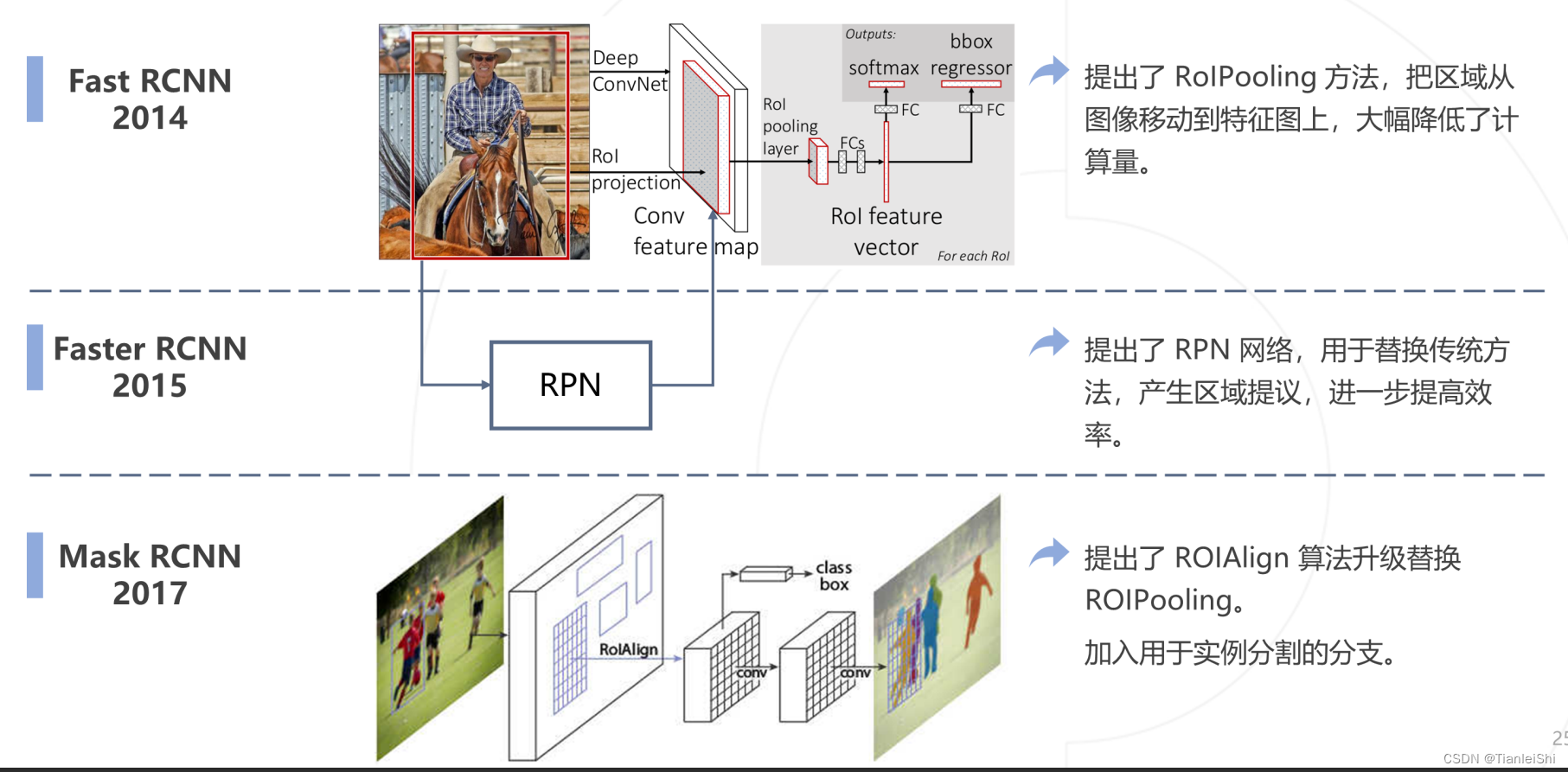
3. Fast R-CNN网络(2015年)
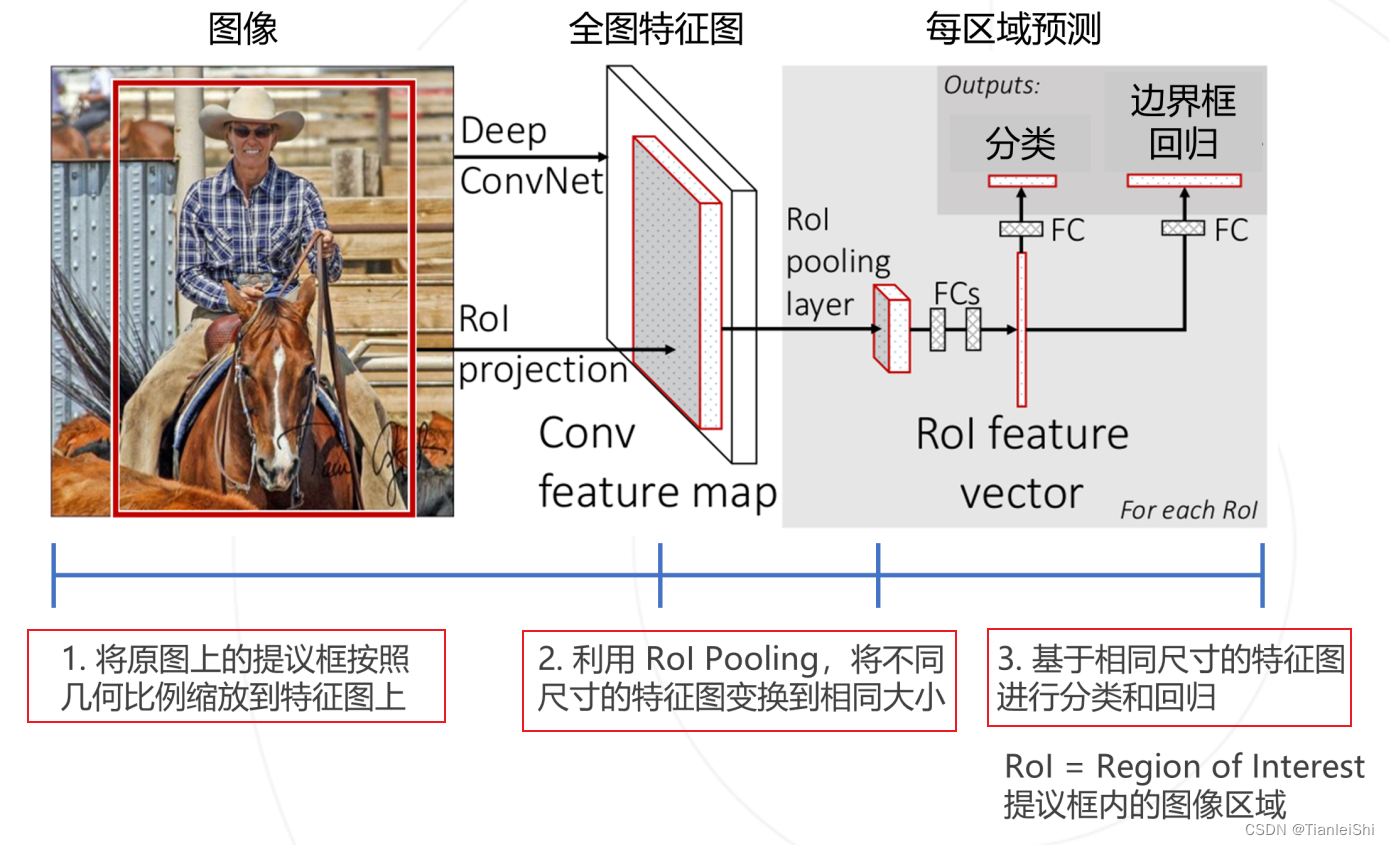
3.1 算法流程及存在问题
- 可以对比R-CNN算法流程
- 同R-CNN:使用SS算法,将一张图像生成1k到2k个候选区域(proposal)
对每个候选区域,使用深度网络(Backnone:AlexNet)提取特征。将图像输入网络得到特征图,将SS算法生成的候选区域投影到特征图上获得相应的特征矩阵(降低计算量)- 将特征矩阵
送入SVM分类器,判别是否属于该类。缩放到7*7大小,接着展平送入全连接层得到预测结果 使用回归器精细修正候选框位置。并联两个全连接层,其中一个进行边界框回归
- 改进之处:将R-CNN中的SVM分类以及bbox回归模型去除,使用一个完整的网络(并联两个全连接层)端到端实现建议框的预测和回归
- 存在问题:SS算法非常耗时,并且需要分步执行
3.2 网络训练数据集设置
- SS算法生成的候选框并不全用于网络训练,只需采样其中一小部分
- 另外要对采样的数据划分为正负样本(保证样本的均衡)
- 正样本:存在检测目标(IoU>0.5)
- 负样本:背景
3.3 ROI Pooling层
- 无论特征矩阵是什么样的大小,全都缩放到7*7size(这样不限制输入图像尺寸)
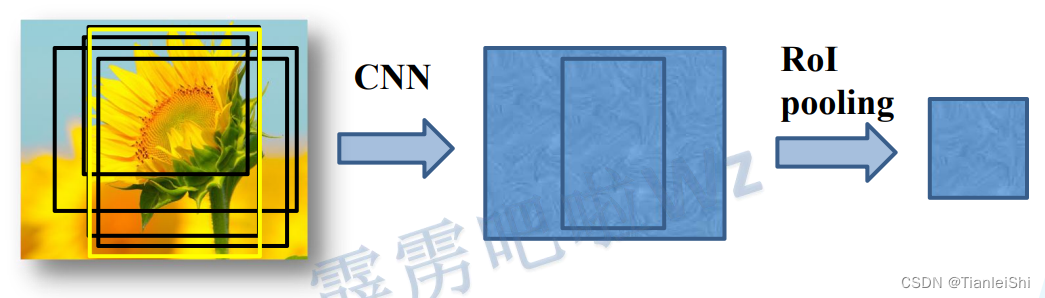
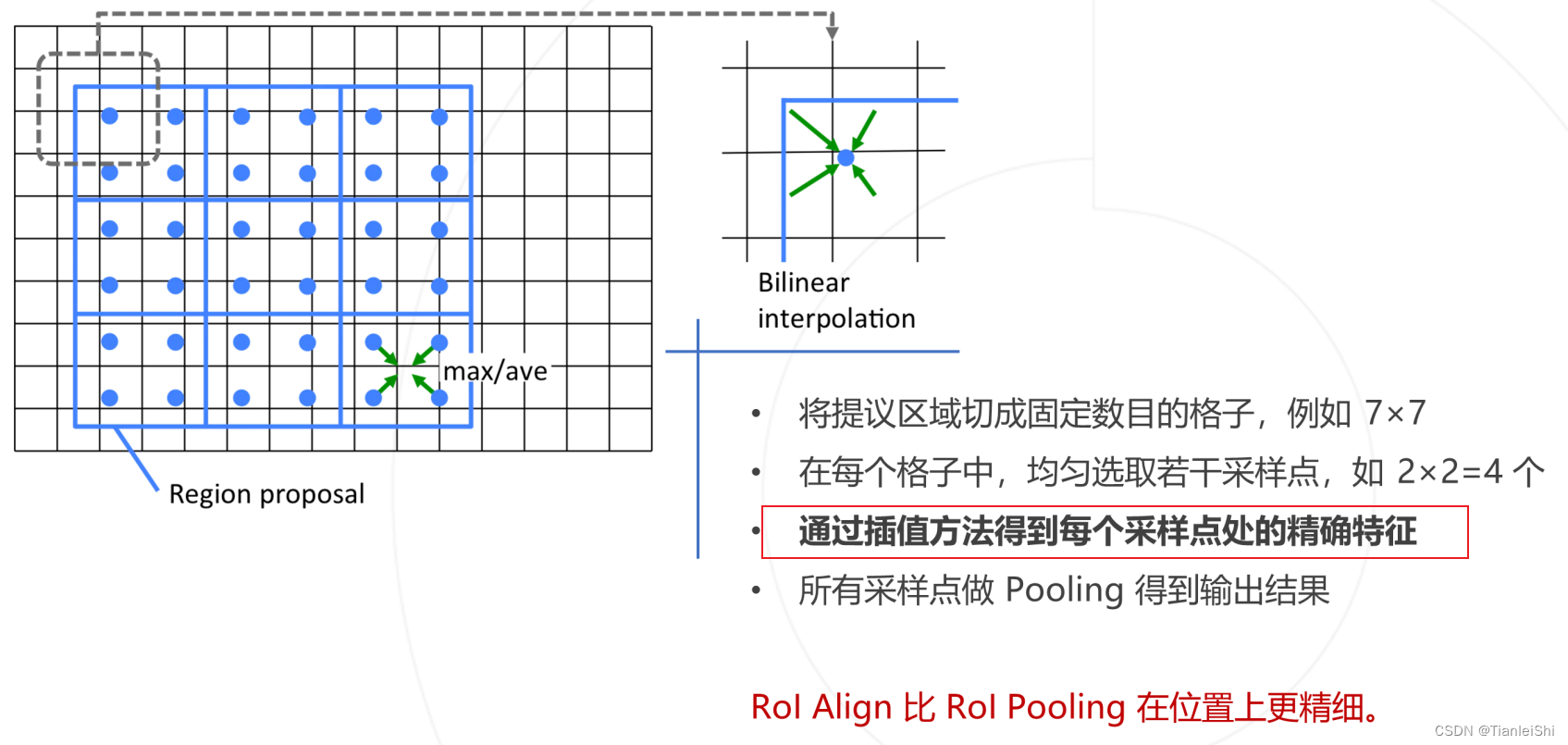
- 做法:将提议区域切分成固定数目的格子(常用7*7),对于每个格子:
- 如果格子边界不在证书坐标,则膨胀至整数坐标
- 通过Max Pooling得到格子的输出特征
- 作用:将任意尺寸的提议区域映射至固定尺寸的特征图,同时保留图像特征
3.4 ROI Align层
- Rol Pooling的位置偏差 → 引入了ROI Align层(2017,是在mask R-CNN中提出的)

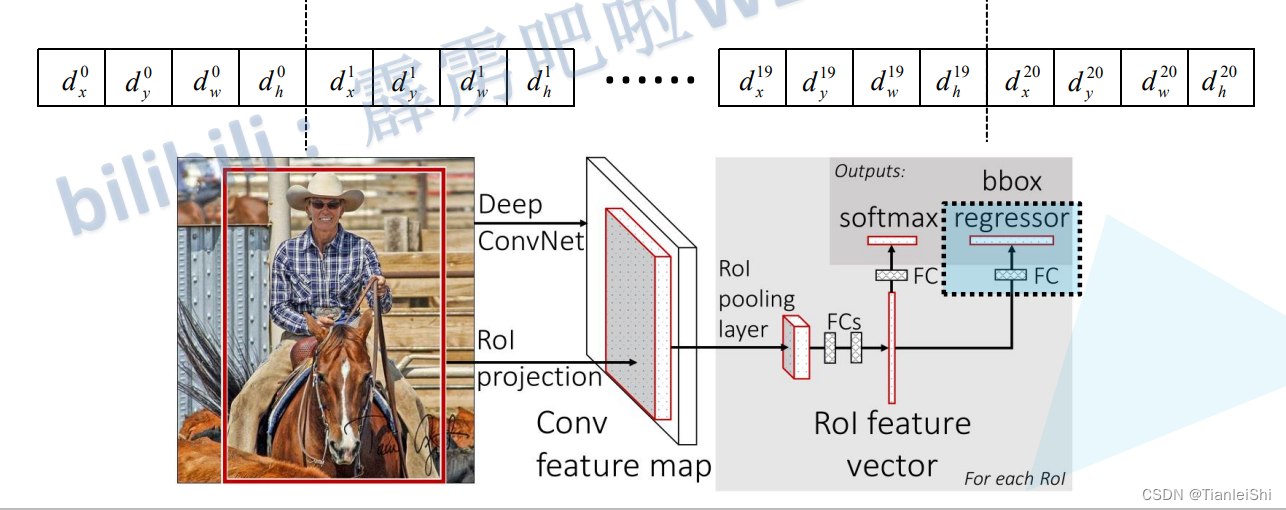
3.5 分类器以及边界框回归器
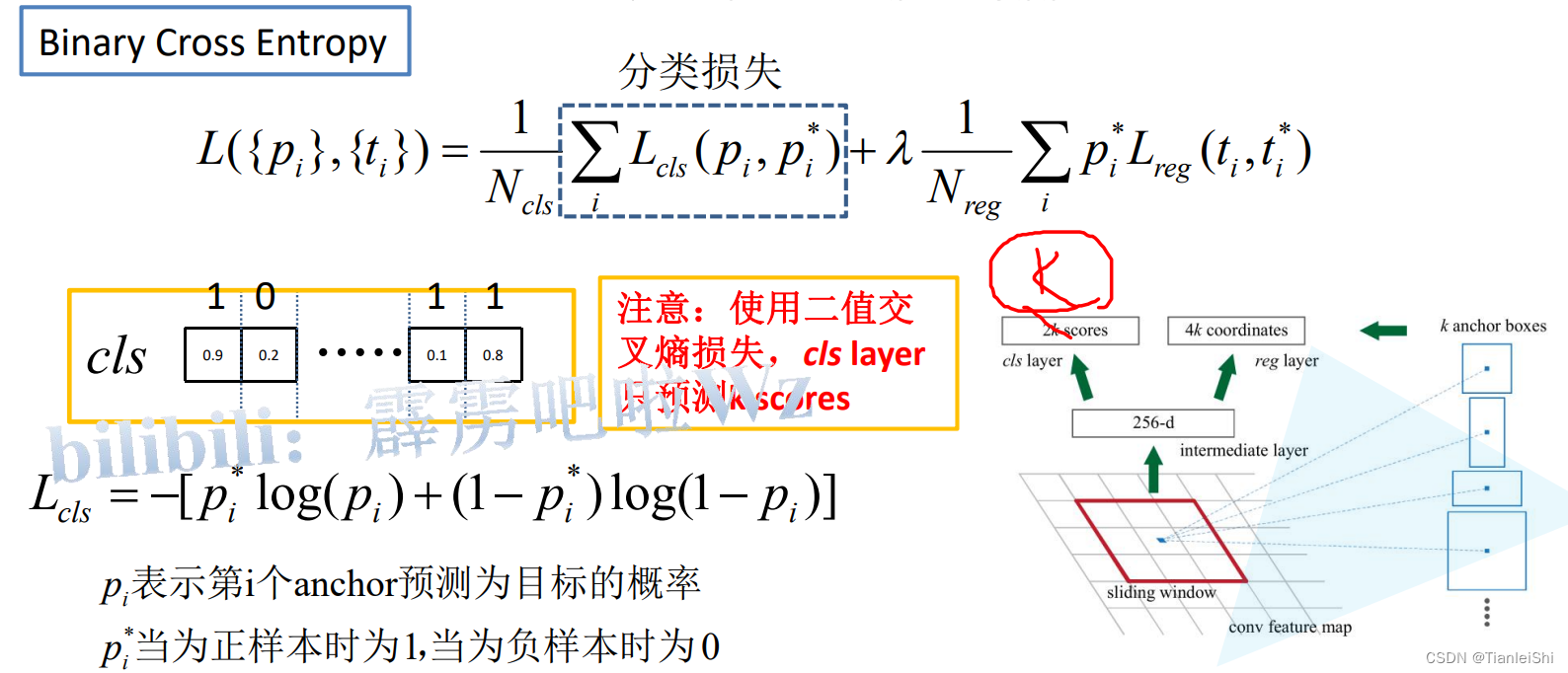
- 分类器输出N+1个类别的概率(N为检测目标的种类, 1为背景)共N+1个节点
- 边界框回归器输出对应N+1个类别的候选边界框回归参数(dx , dy , dw, dh ),共(N+1)x4个节点
3.6 多任务损失
- 分类损失:交叉熵损失,softmax输出
- 边界框回归损失:smooth损失


4. Faster R-CNN网络(2016年)
4.1 算法流程及改进之处
- 可以对比Fast R-CNN算法流程
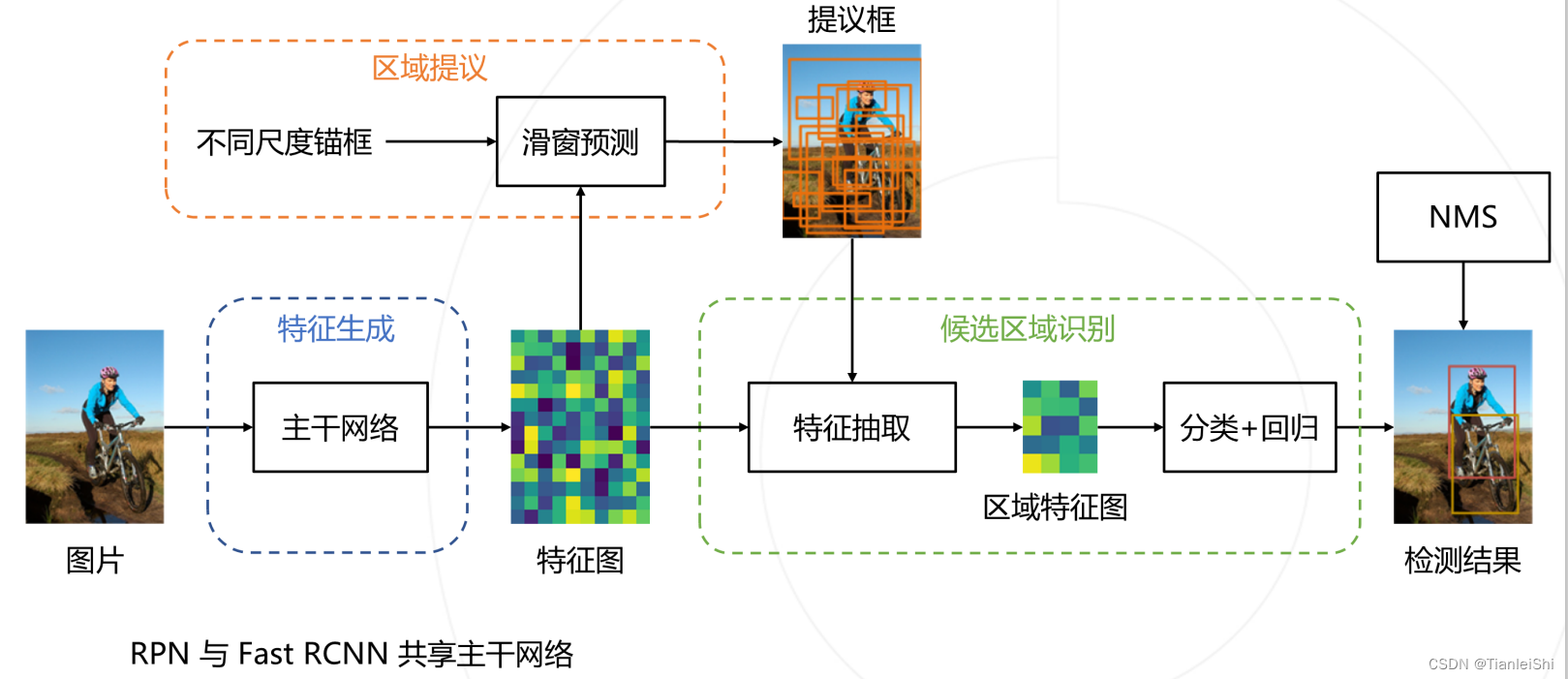
- 首先:将图像输入网络得到相应的特征图
使用SS算法,使用RPN网络生成候选框,将一张图像生成1k到2k个候选区域(proposal)将图像输入网络得到特征图,将SS算法RPN网络生成的候选区域投影到特征图上获得相应特征矩阵- 将特征矩阵缩放到7*7大小,接着展平送入全连接层得到预测结果
- 并联两个全连接层,其中一个进行边界框回归
- 改进之处:将Fast R-CNN中的SS算法替换为RPN网络(区域提议网络)
4.2 RPN网络
- 先是在特征图上使用3*3的滑动窗口的中心点计算出对应原始图像的中心点,以此计算出k个anchor boxes
- RPN网络的目的在于让这K个anchor含有前景物体的概率最高
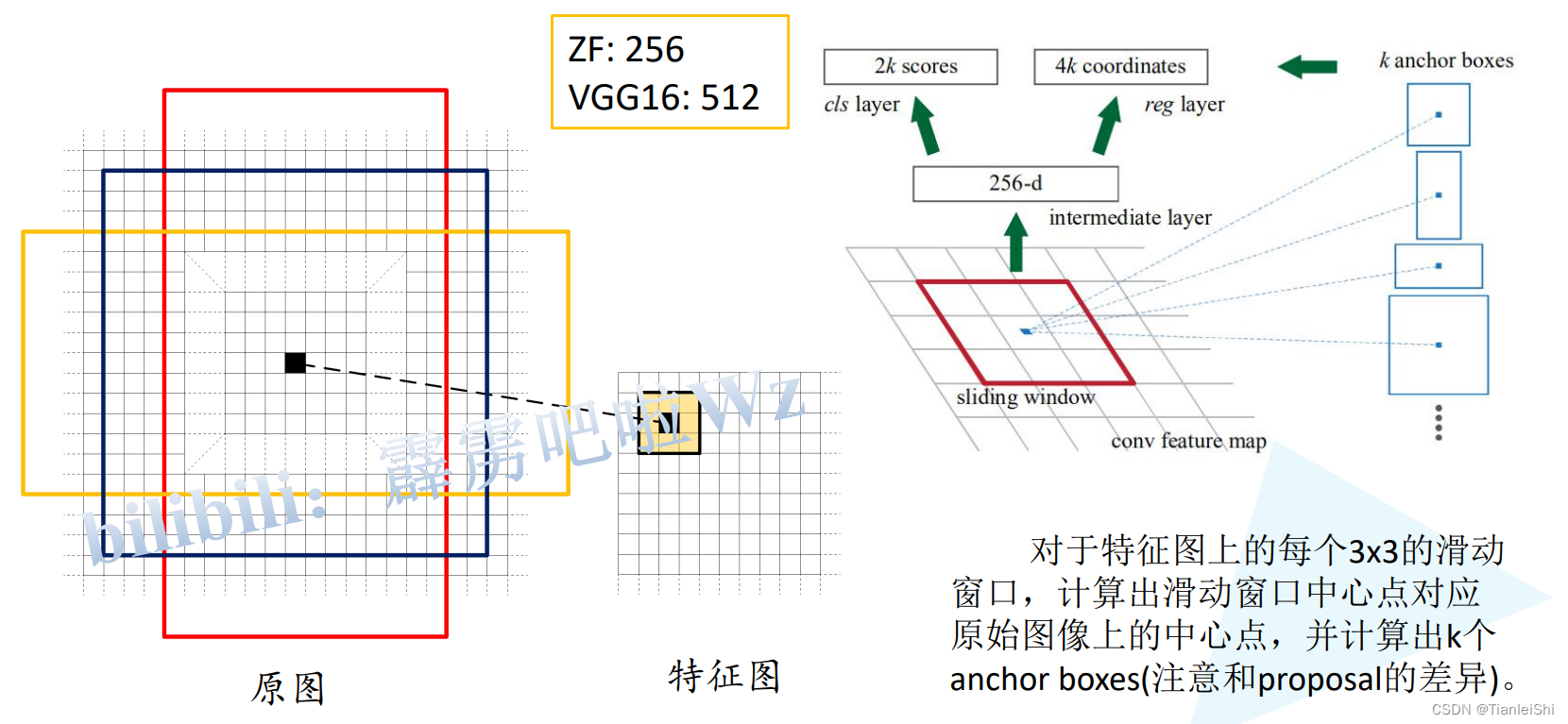
- RPN网络的训练样本:一张图像对其生成的anchor随机采样256个anchor(正负样本1:1)
- 如何定义正负样本
- anchor与GT-box的IoU>0.7(正样本)
- anchor与GT-box拥有最大的IoU(正样本)
- anchor与所有GT-box的IoU<0.3(负样本)
- 如何定义正负样本
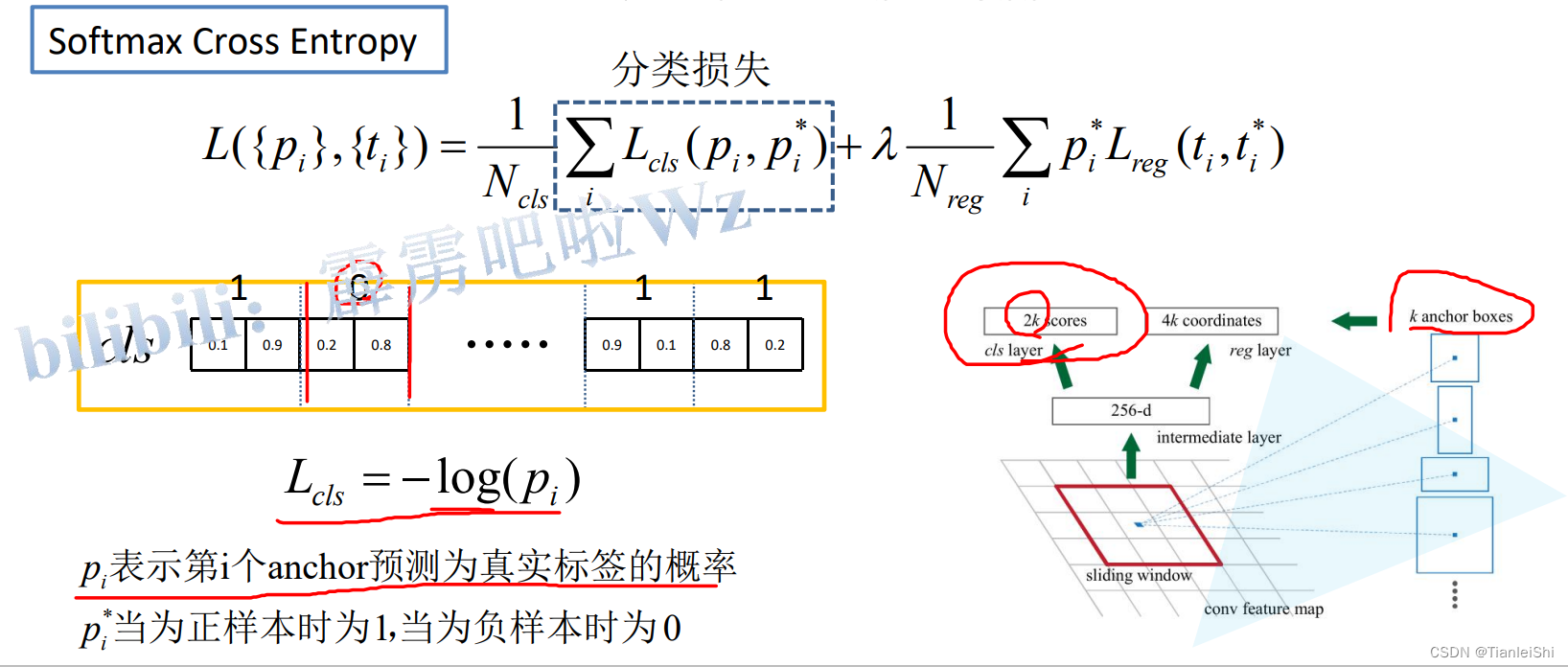
- RPN网络的损失:也是多任务损失(分类和边界框回归),这里的分类是前景和背景分类
- 注意这里的分类损失若使用多分类softmax,则输出为2k,若二分类sigmoid,则输出为k
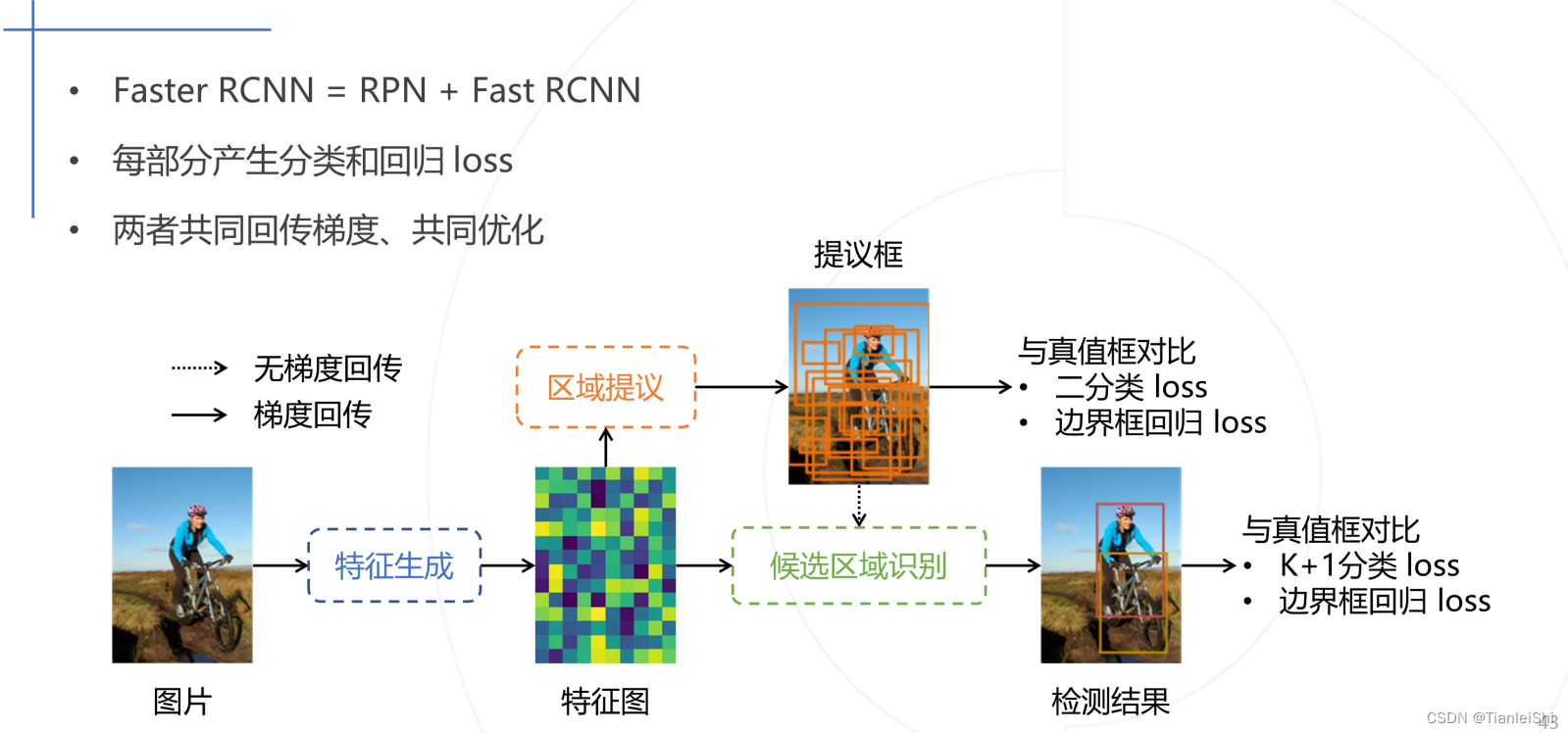
4.3 Faster R-CNN训练过程
-
原论文中采用分别训练RPN以及Fast R-CNN的方法
-
利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN参数
-
固定RPN网络,再利用 ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框去训练Fast RCNN网络参数
-
固定利用Fast RCNN训练好的前置卷积网络层参数,微调RPN 网络
-
同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络
-
-
也可直接采用RPN Loss+ Fast R-CNN Loss的联合训练方法
5. FPN+Faster R-CNN网络(2016年)
- 到此为止,模型基于单级特征图进行预测,通常是主干网络组后一层或者倒数第二层
- 存在问题:高层次特征空间降采样率较大,小物体信息丢失
- 解决思路:
- 基于底层特征图预测 → 底层特征语义信息薄弱
- 图像金字塔 → 低效率
- 因此:融合高低层次的特征 → 特征金字塔网络FPN
5.1 FPN结构亮点
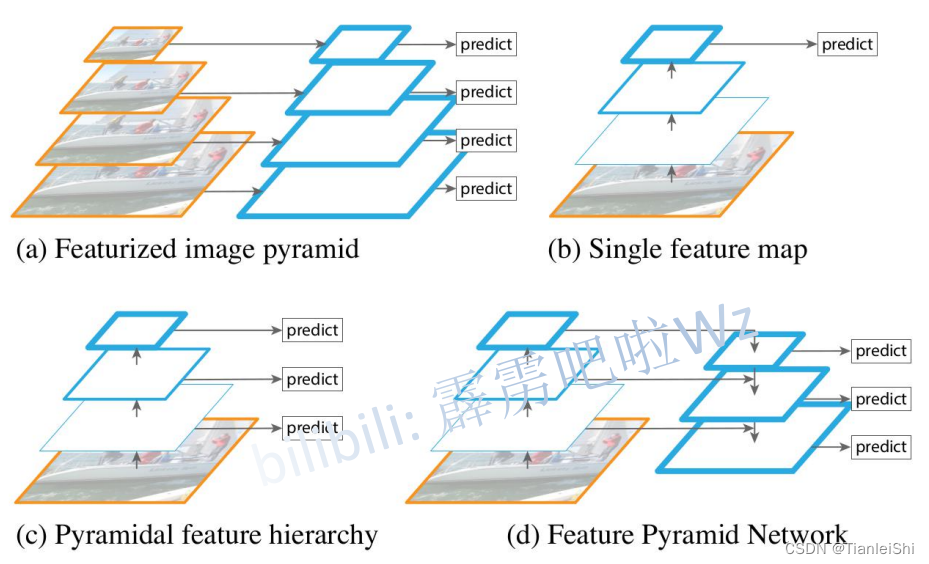
- 可以对比
- a. 图像金字塔结构,对图像进行不同尺度的缩放,这样导致预测效率低
- b. single feature map,像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征,针对小目标预测效果不好
- c. pryamidal feature hierarchy,像SSD采用这种多尺度特征融合的方式,没有上采样过程即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的
- 本文作者是采用d.这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的,确实有助于提升网络检测效果。针对目标检测任务:coco AP提升2.3个点;pascal AP提升3.8个点
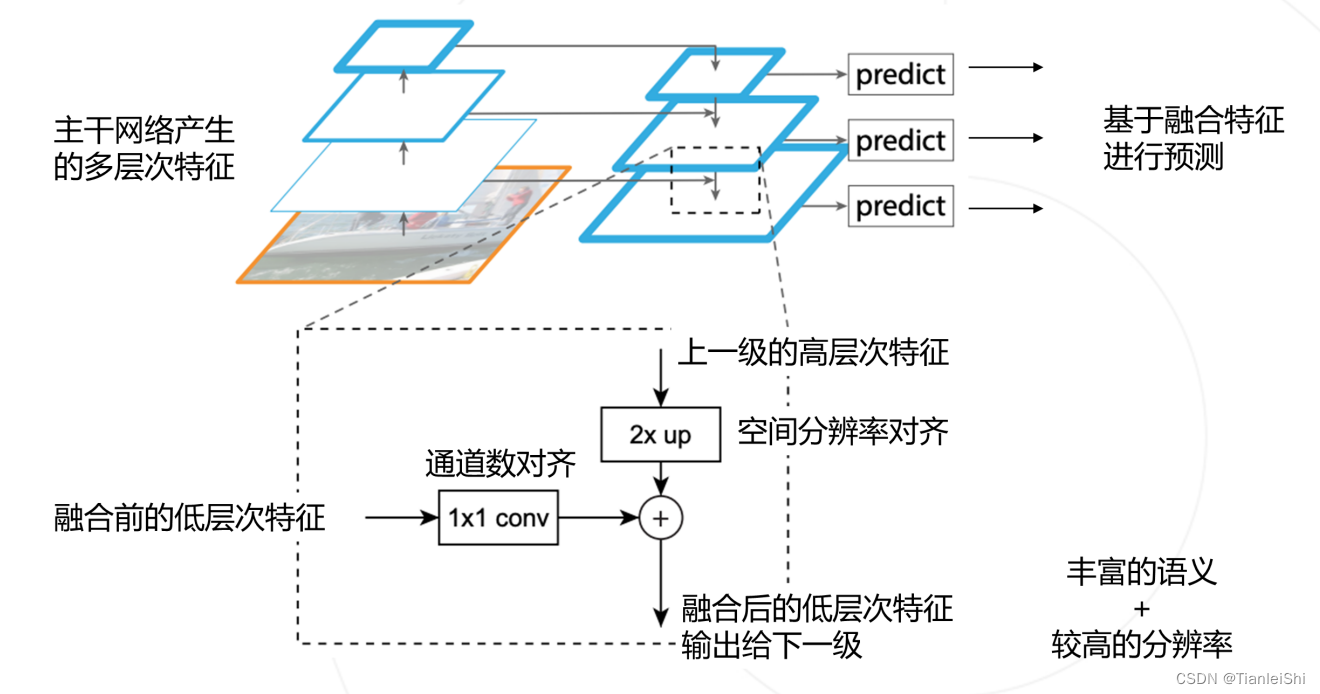
在分类网络中,Backbone每次缩放feature map的时候都是以2的整数倍进行缩放的。
5.2 FPN网络结构
不同特征层采用1*1卷积调整channel数量,采用上采样(插值方式)调整特征图尺寸,最终融合C2-C5特征层,并分别通过3*3卷积得到P2-P5融合后的特征层,比如说P2层相对较底层的预测特征层会保留更多的细节信息,更适合预测小型目标
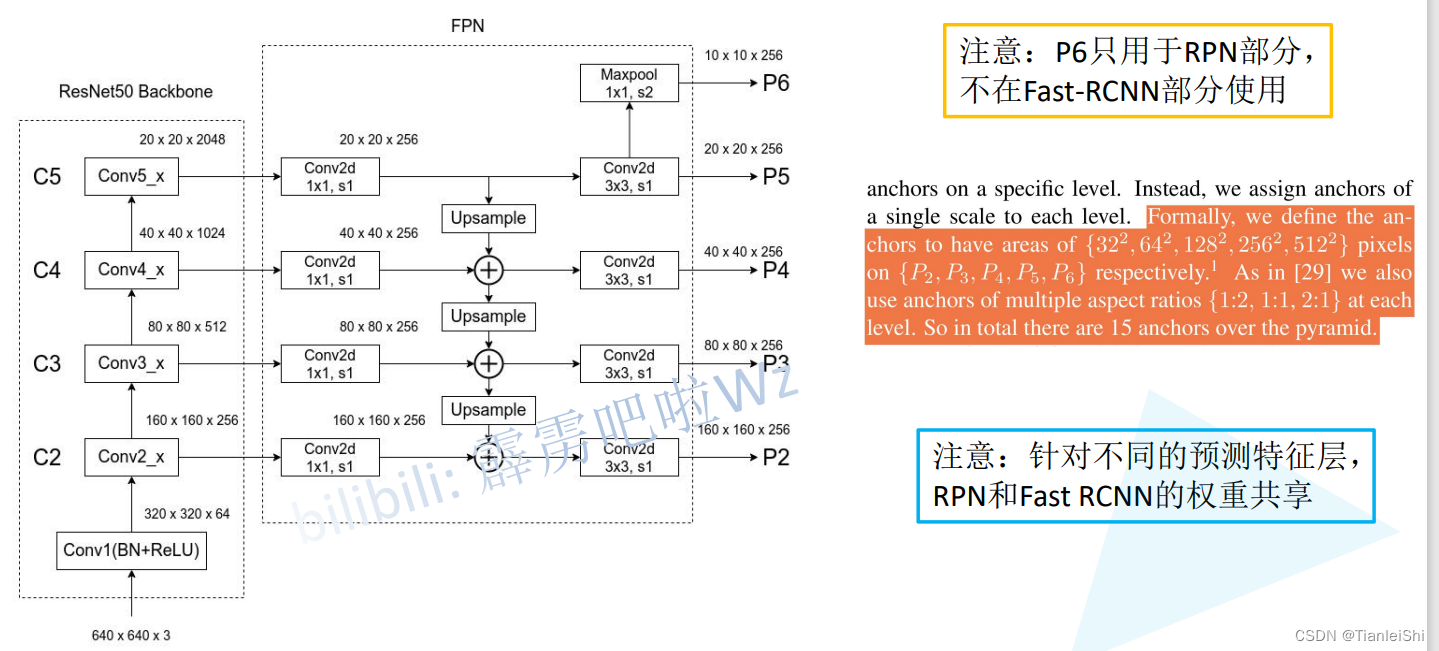
5.3 FPN+Faster R-CNN的预测过程
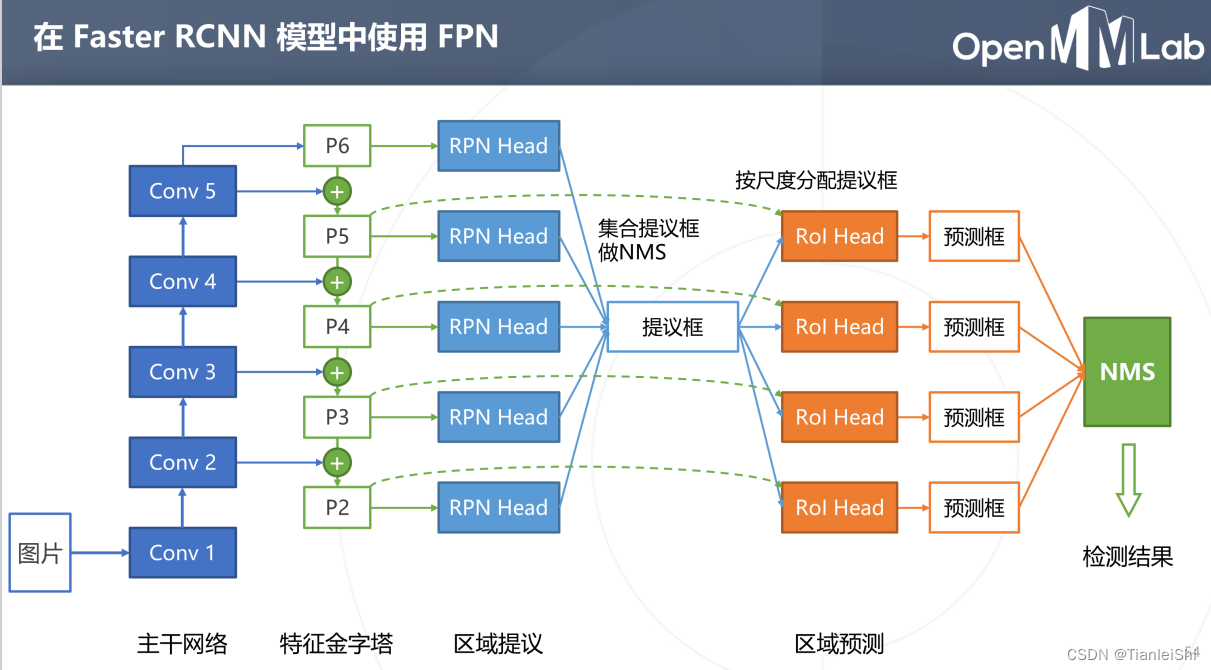
- 由于在RPN网络中使用了FPN结构,原本在一层特征层上生成很多候选框的情况,现在变成了在P2-P6五层特征层上生成候选框(这里每一层针对不同面积大小的anchor对于生成,也就是说P2到P6分别对应生成面积为32,64,128,256,512的anchor)
- 另外,前置卷积层也是用FPN结构后,回程从P2-P5四层特征图
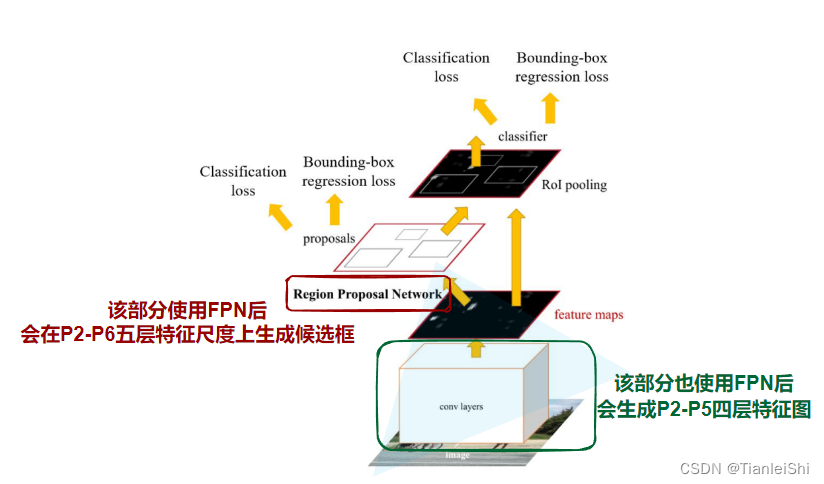
- 预测的时候由RPN生成的P2-P6的候选框,首先要映射到P2-P5层级,然后经过Faster R-CNN网络进行预测和回归
- 这里映射的时候文献中给了相应的计算公式



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









