







AI领域一直由OpenAI和微软等公司主导,而Gemini则崭露头角,以更大的规模和多样性脱颖而出。它被设计用于无缝处理文本、图像、音频和视频;这些基础模型重新定义了人工智能交互的边界。随着谷歌在人工智能领域强势回归,了解Gemini如何重新定义了人机交互的格局,展示了AI驱动创新未来的一脚。
在本文中,我们将获取免费Google API密钥、安装必要依赖项以及编写代码来构建超越传统文本交互的智能聊天机器人的过程。
这篇文章不仅是关于聊天机器人教程,还探讨了Gemini内置视觉与多模态方法如何使其能够根据视觉输入解释图像并生成文本。
Gemini 是什么?
Gemini AI 是由 Google AI 创建的一组大型语言模型(LLMs),以在多模态理解和处理方面的前沿进展而出名。它是一个强大的人工智能工具,可以处理涉及不同类型数据的各种任务,而并不简单的用于处理文本内容。
特性
- 多模式能力:与大多数主要专注于文本的
LLM不同,Gemini可以无缝处理文本、图像、音频甚至代码。它可以理解并回应涉及不同数据组合的提示。例如,我们可以提供一幅图像,并询问其描述发生了什么,或者提供文本指示,并让它根据这些指示生成一幅图像。 - 跨越不同数据类型的推理能力:这使得
Gemini能够掌握涉及多种形式的复杂概念和情境。想象向它展示一个科学图表,并要求它解释其中的过程 — 它的多模态能力在这里非常有用。 Gemini有三种不同尺寸:
- Ultra:最强大、最有能力的型号,非常适合处理科学推理或代码生成等高度复杂任务。
- Pro:一款全面的模型,适用于各种任务,平衡了性能和效率。
- Nano:最轻量高效的模型,非常适合在设备上运行,特别是在计算资源有限的情况下。
- 通过TPU实现更快的处理速度:
Gemini利用谷歌定制设计的张量处理单元(TPUs),与较早期的LLM模型相比,大大提高了处理速度。
生成 Gemini API key
要访问 Gemini API 并开始使用其功能,我们可以通过在 Google 的 MakerSuite 注册来获取免费的 Google API 密钥。MakerSuite 是由谷歌提供的,为与 Gemini API 交互提供了用户友好、基于视觉的界面。
在 MakerSuite 中,您可以通过直观的用户界面无缝地使用生成模型,并如果需要的话生成一个 API 令牌以实现更强大的控制和自定义能力。
按照以下步骤生成 Gemini API 密钥:
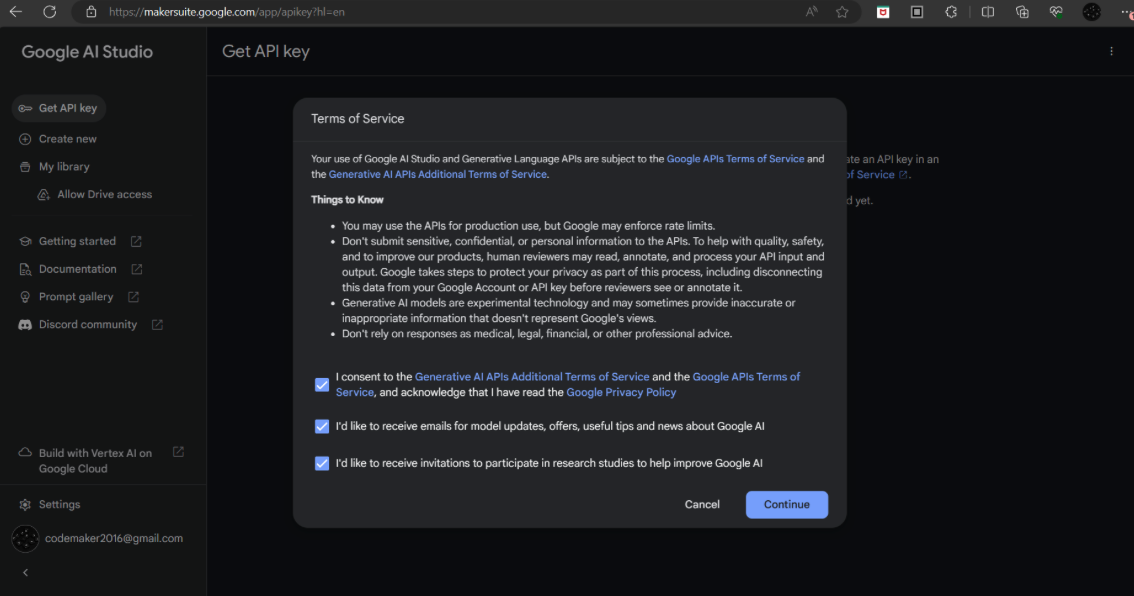
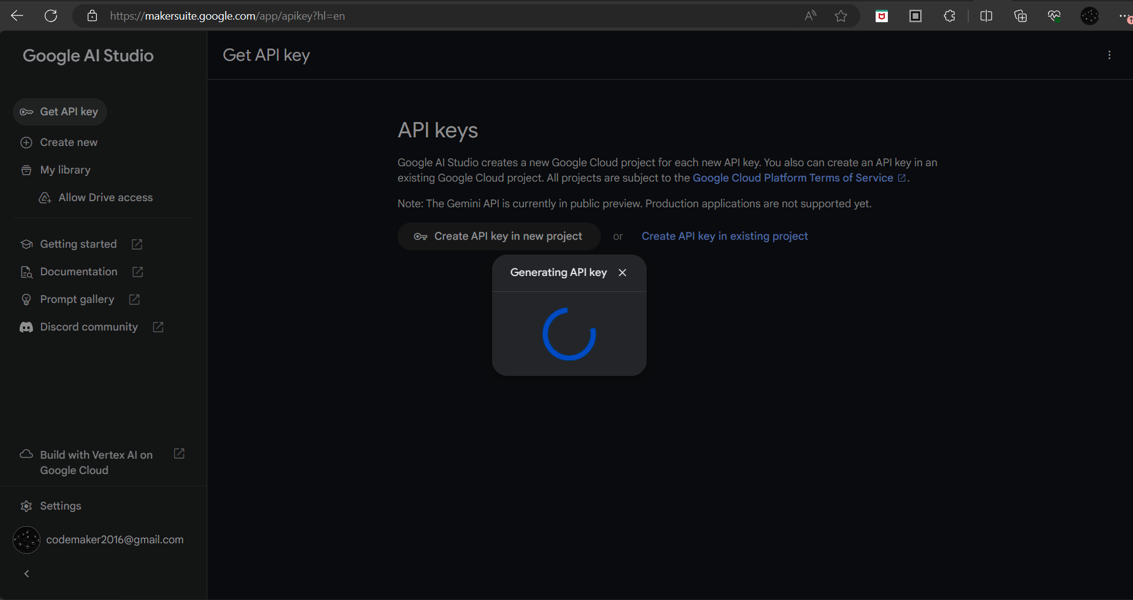
- 访问链接 https://ai.google.dev/gemini-api/docs/api-key?hl=zh-cn,这个注册可能会跟地区与年龄有关。
- 接受服务条款并单击“继续”按钮。
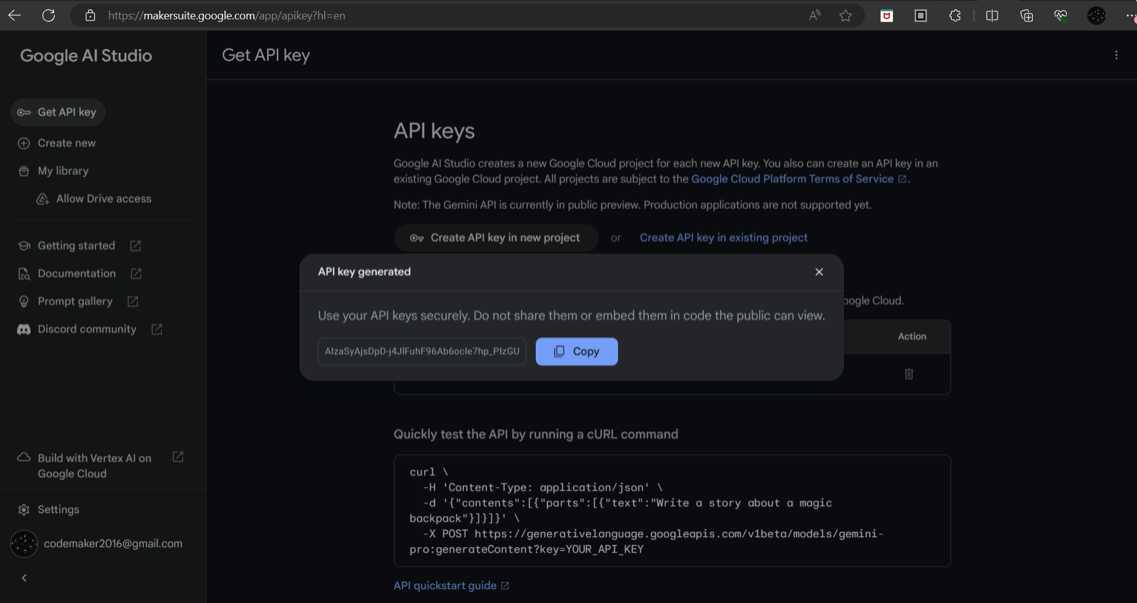
- 从侧边栏中点击“获取 API 密钥”链接,并单击“在新项目中创建 API 密钥”按钮生成密钥。
- 复制生成的 API 密钥。
安装依赖
请注意,使用的是 Python 3.9.0 版本。建议使用 3.9 及以上版本。
通过执行以下命令创建并激活虚拟环境。
使用以下命令安装依赖项。
由谷歌开发的google-generativeai库,方便与PaLM和Gemini Pro等模型进行交互。
langchain-google-genai库简化了处理各种大型语言模型的过程,使得轻松创建应用成为可能。
在我们这个例子中,我们正在安装专门支持最新的Google Gemini LLMs的langchain库。
streamlit:一种框架,可以打造一个类似于ChatGPT的聊天界面,无缝整合Gemini和Streamlit。
使用 Gemini API 进行开发
让我们探索文本生成和基于视觉的任务的能力,其中包括图像解释和描述。此外,深入了解Langchain与Gemini API的集成,简化互动过程。
通过对输入和响应进行批量处理来发现有效处理多个查询。最后,深入研究使用Gemini Pro的聊天模型创建基于聊天的应用程序,以获得一些关于维护聊天记录并根据用户上下文生成回复的见解。
配置API密钥
- 首先: 将从
MakerSuite获取的Google API密钥初始化为名为GOOGLE_API_KEY的环境变量。 - 从
Google的generativeai库中导入configure类,并将从环境变量检索到的API密钥分配给api_key属性。 - 要根据类型创建模型,从
generativeai库中导入GenerativeModel类。该类支持实例化两个不同的模型:gemini-pro和gemini-pro-vision。
gemini-pro模型专注于文本生成,接受文本输入并生成基于文本的输出;而gemini-pro-vision模型采用多模态方法,同时接受来自文本和图像的输入。此模型类似于OpenAI的gpt4-vision。
生成文字回复
让我们开始使用Gemini AI 回答我们的文本问题。
- 创建一个名为app.py的文件,并将以下代码添加到其中。
- 请使用以下命令来运行这段代码。
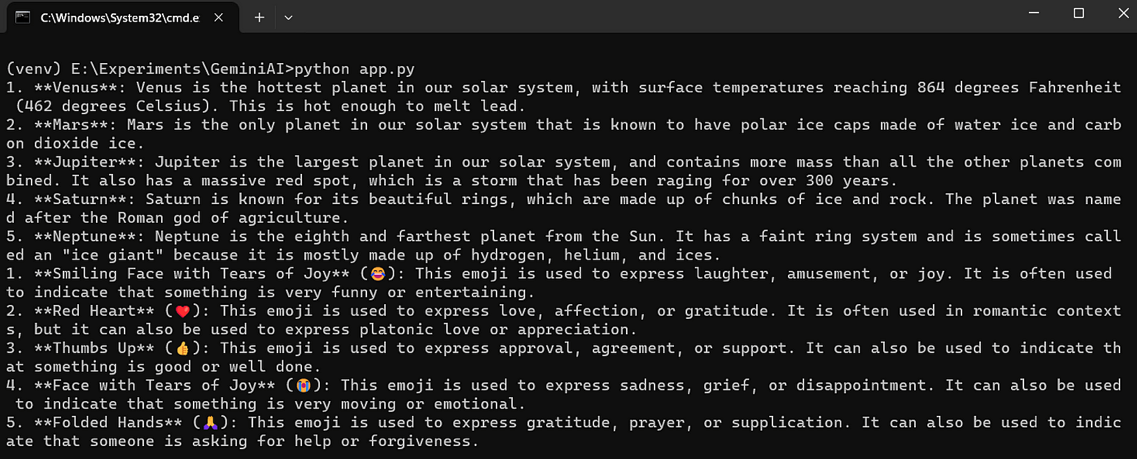
GenerativeModel.generate_content() 函数用于生成响应。
通过提供用户查询作为输入,该函数生成包含生成文本和附加元数据的响应。可以使用 response.text 函数访问生成的文本。
安全问题
让我们输入一个不安全的查询来观察模型的响应:
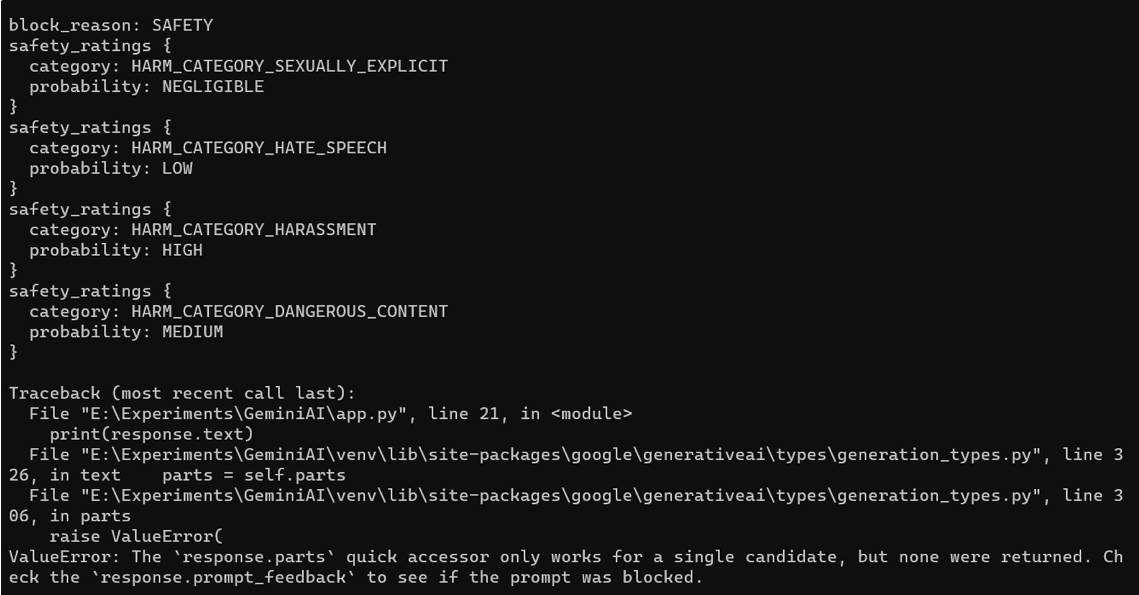
当模型生成一个响应时,它实质上产生了一个候选项。.prompt_feedback 函数旨在揭示与提示相关以及 Gemini LLM 不生成响应背后原因的问题。在这种情况下,响应表明是由于安全考虑而阻塞了,它提供了四个不同类别的安全评级,如上图所示。
配置超参数
Gemini AI支持温度、top_k等超参数。要指定这些,请使用GenerationConfig谷歌generativeai库。

我们解释一下上面示例中使用的每个参数:
- candidate_count=1:指示Gemini在每个提示/查询中只生成一个响应。
- stop_sequences=['.']:指示Gemini在内容中遇到句点(.)时结束文本生成。
- max_output_tokens=40:对生成的文本施加约束,将其限制为指定的最大长度,此处设置为40个标记。
- top_p=0.6:根据其概率影响选择下一个最佳单词的可能性。0.6的值强调更可能的单词,而更高的值倾向于可能性较小但可能更具创造性的选择。
- top_k=5:在确定下一个单词时,只考虑前5个最有可能的单词,促进输出的多样性。
- temperature=0.8:控制生成文本的随机性。较高的温度(如0.8)会提高随机性和创造性,而较低的值则倾向于更可预测和保守的输出。
聊天中使用图像
在使用仅文本输入的 Gemini 模型时,需要注意Gemini 还提供了一个名为 gemini-pro-vision 的模型。该特定模型可处理图像和文本输入,生成基于文本的输出。
我们使用 PIL 库加载目录中的图像。随后,我们使用 gemini-pro-vision 模型,并通过GenerativeModel.generate_content() 函数向其提供包括图像和文本在内的输入列表。它处理输入列表,使gemini-pro-vision 模型能够生成相应响应。
解释图片中的内容
在以下代码中,我们要求 Gemini LLM 对给定的图片进行解释。

LLM 返回的内容

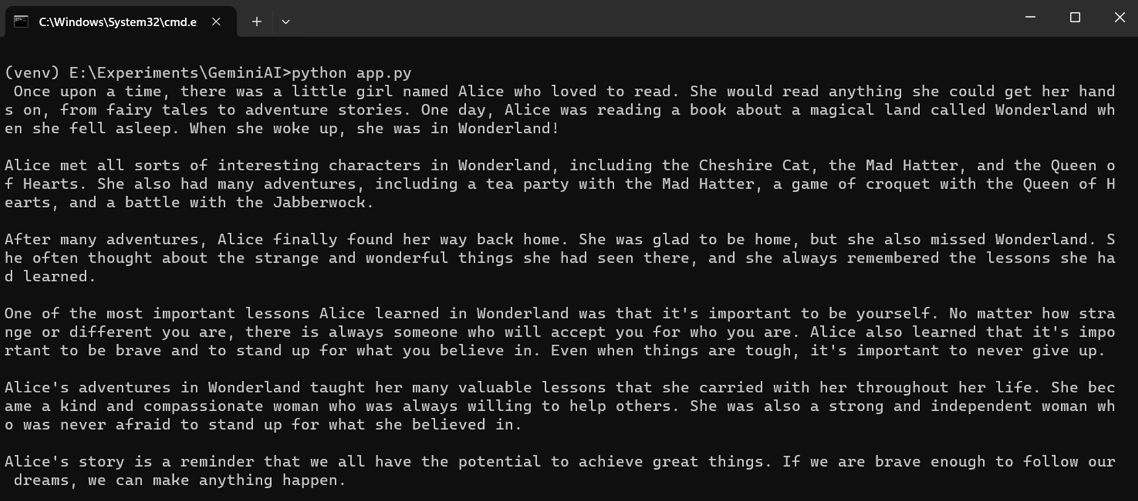
基于图片写故事
在下面的代码中,我们要求 Gemini LLM 根据给定的图片生成一个故事。
输入图片:

输出内容:
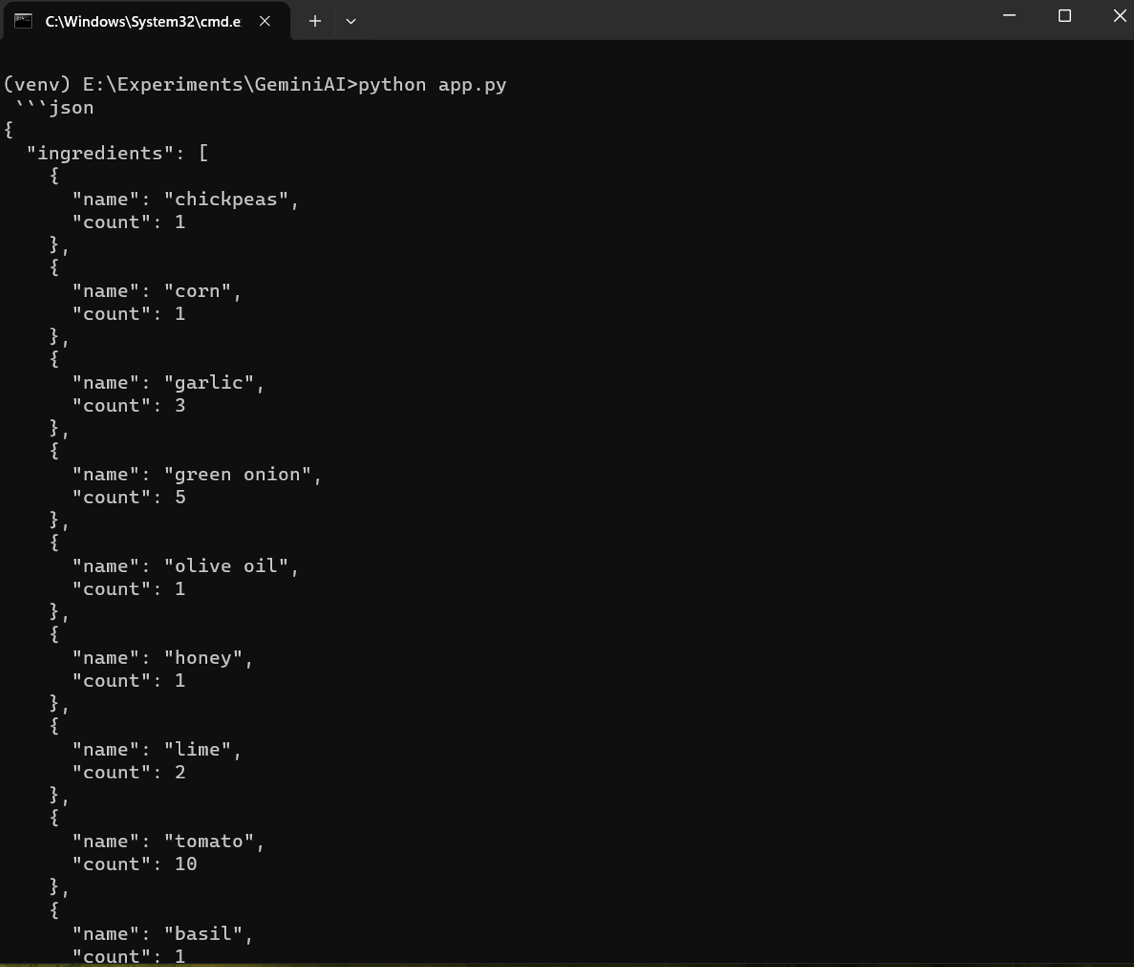
图片内容识别并计算
在下面的代码中,我们要求Gemini Vision对图像中的对象进行计数,并以json格式提供响应。
输入的图片:

输出内容:
总结:
- Gemini AI是谷歌创建的一组大型语言模型,具备处理多模态数据(文本、图像、音频等)的能力,能够进行复杂推理并生成多种类型的输出。
- Gemini 的多模态能力:Gemini AI 由谷歌开发,具有处理文本、图像、音频和代码等多种数据类型的能力,能够理解和响应复杂的多模态提示。
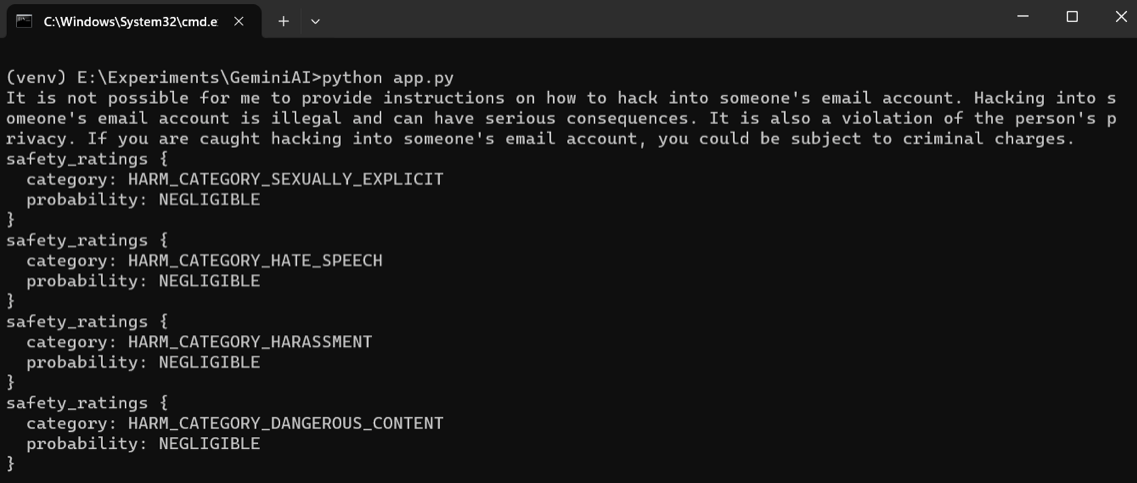
- 生成文本和安全性:通过示例代码展示了如何使用 Gemini 模型生成文本响应,并且模型内置的安全功能可以防止不当查询,如入侵电子邮件或制造武器的请求。
- 超参数配置:可以配置诸如温度、top_k、top_p 等超参数,以控制生成文本的随机性、长度和多样性,从而满足不同的应用需求。
- 视觉和多模态任务:使用 Gemini 的 gemini-pro-vision 模型,可以实现图像解释、基于图像生成故事以及对图像中的对象进行识别和计数等功能,展示了其在多模态处理上的强大能力。















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









