






1、背景
由于业务系统使用的是传统关系型数据库sqlserver、mysql,数据随着时间的日积月累,导致数据量不断增大,最后导致系统的查询性能比较低下,用户体检非常不友好。
在传统关系型数据库上,适合使用solr作为优化方式的几种情况:
1)、基于字段的模糊查询
2)、单表数据量过大,创建索引之后查询依旧比较慢
下面简单介绍一下基于solr来优化查询效率的一种实现方式。
2、solr安装:以windows为例
Solr是一个高性能,采用Java开发。Solr基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的搜索引擎。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr 的特征:
高级全文搜索能力:由Lucene ™提供支持,Solr可实现强大的匹配功能,包括短语,通配符,联接,分组以及任何数据类型
针对大容量流量进行了优化:
拥有基于标准的开放式接口- XML、JSON 和 HTTP
综合的管理界面
实现轻松监控
高度的可扩展性和容错性
灵活的适应性,易于配置
能够实时索引
可扩展的插件架构
solr链接
Solr 各版本下载地址:Index of /dist/lucene/solr
本手册翻译自 Solr 官方网站:Resources - Apache Solr
详细的solr中文手册链接:
Solr官方文档_w3cschool
Solr采用Java5开发,是建立在Apache Lucene上的流行的、快速的开源企业搜索平台。Solr具有高度可靠、可伸缩和容错能力,提供分布式索引、复制和负载平衡查询、自动故障转移和恢复、集中配置等功能。_来自Solr官方文档,w3cschool编程狮。
https://www.w3cschool.cn/solr_doc/
solr安装
在安装solr之前,首先保证已经正确安装了Java。
solr从6.0之后需要Java1.8,所以如果使用Solr6.0及其以上版本,请确保Java版本在1.8之上
将Solr下载之后解压在电脑的某个目录,我解压到了C盘目录下.
1)、下载解压之后,solr的结构说明:如下图
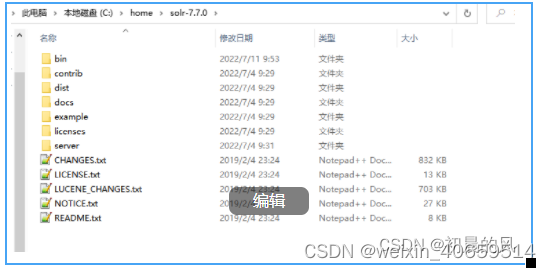
2)、安装
将solr-7.7.0.zip文件拷贝到C盘;(或者其他盘都可以,只要目录中不要出现中文就行。)
解压solr-7.7.0.zip文件,得到solr-4.10.2目录。
进入solr的bin目录中,运行cmd 执行命 solr.cmd start 如下图所示:
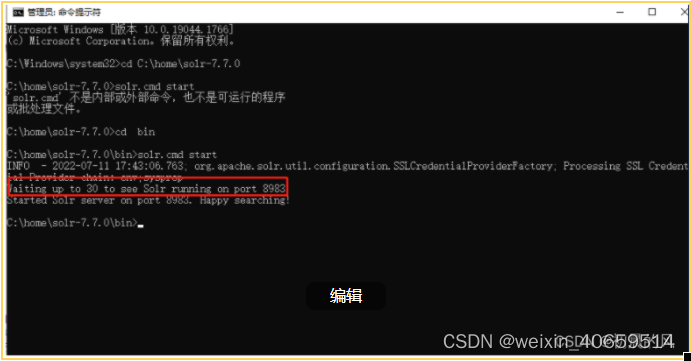
3)、启动:浏览器中输入:http://localhost:8983/solr/
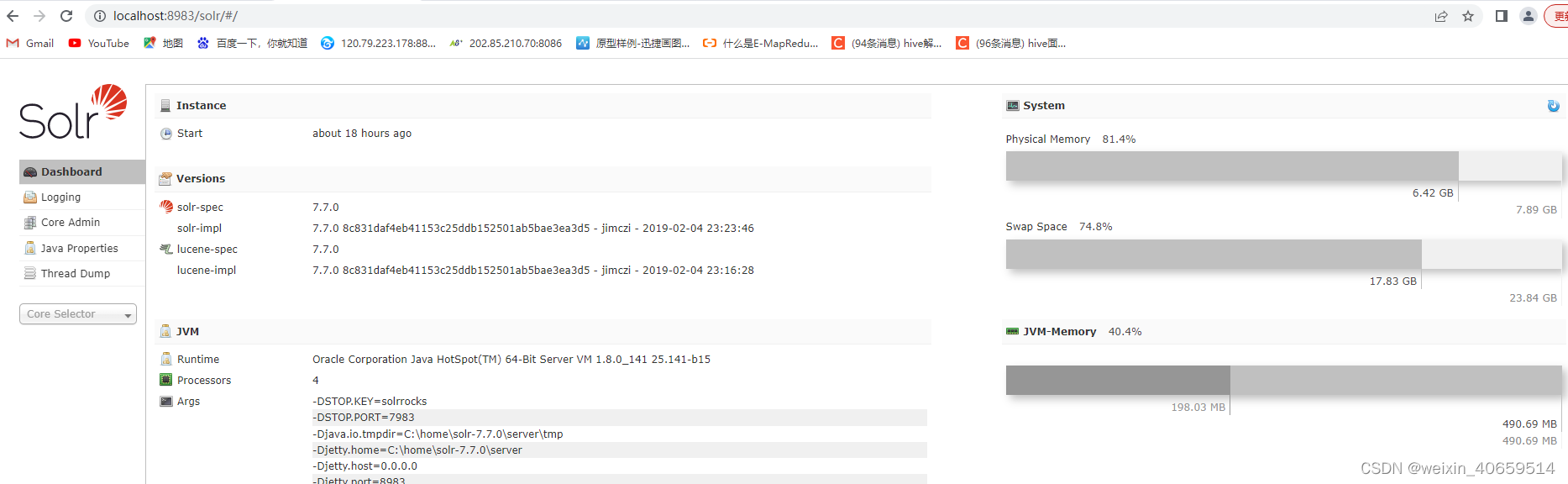
到此,solr就安装成功了
solr创建Core
创建core有两种方式:通过界面操作创建;通过命令创建
通过界面操作创建:
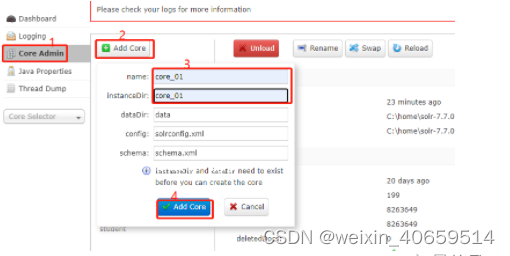
1)、在C:\home\solr-7.7.0\server\solr内创建一个core_01文件夹:
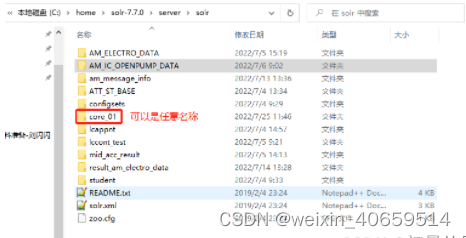
2)、将C:\home\solr-7.7.0\server\solr\configsets\sample_techproducts_configs\conf文件夹复制到core_01内
3)、修改core_demo/conf/solrconfig.xml文件,一般不需要修改
4)、在http://localhost:8983/solr内添加core_01实例,实例名称一定要与您第一步创建的文件夹名称相同
通过命令创建:
进入solr安装bin,执行一下命令:
solr.cmd create -c core_01
设置中文分词器
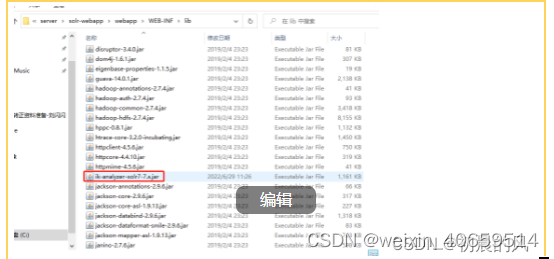
将中文分词器的jar放到C:\home\solr-7.7.0\server\solr-webapp\webapp\WEB-INF\lib
找到要配置分词器的core下面的managed-schema文件,添加一下内容:

3、solr和spring boot项目整合
整合依赖
spring.data.solr.host=http://localhost:8983/solr
简单写一下模糊查询接口api
@Override
public List<result_am_electro_data> searchByName(String keywords) throws Exception {
//创建查询
SolrQuery query = new SolrQuery();
System.out.println(“输出参数:”+keywords);
//精准查询,查询关键词用英文双引号
query.setQuery(“st_name:”“+keywords+”“”);
//模糊查询,关键词不需要双引号
//query.setQuery(“st_name:”+keywords);
QueryResponse res = solrClient.query(“result_am_electro_data”, query);
//获取结果集
SolrDocumentList results = res.getResults();
System.out.println(“输出结果:”+results.getNumFound());
List<result_am_electro_data> list = new ArrayList<>();
if(results.getNumFound() > 0){
for(SolrDocument doc:results){
result_am_electro_data en = new result_am_electro_data();
en.setApp_pc(Double.valueOf(doc.get(“acc_pc”).toString()));
en.setGuid(doc.get(“guid”).toString());
en.setId(doc.get(“id”).toString());
en.setSt_code(doc.get(“st_code”).toString());
en.setSt_name(doc.get(“st_name”).toString());
en.setTm(doc.get(“tm”).toString());
en.setSt_lang(BigDecimal.valueOf(Double.valueOf(doc.get(“st_long”).toString())));
en.setSt_lat(BigDecimal.valueOf(Double.valueOf(doc.get(“st_lat”).toString())));
list.add(en);
}
}
return list;
}
4、solr数据初始化方式
将数据库数据初始化到solr中,比较常用的两种方式有通过配置文件进行初始化,也可以通java API方式同步,下面介绍一下sqlserver数据同步到solr的两种方式。
通过配置文件:
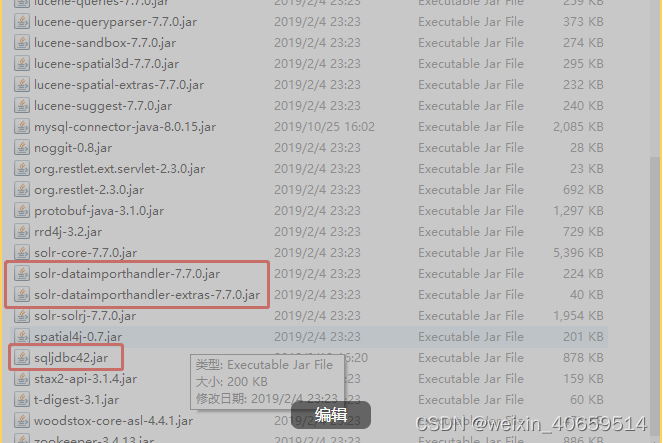
1、先将sqlserver的驱动包以及solr同步的依赖包拷贝到C:\home\solr-7.7.0\server\solr-webapp\webapp\WEB-INF\lib:
2、创建solr的core,这里使用命令创建:solr.cmd create -c core_02
3、然后修改配置文件
进入core_02的conf目录,修改solrconfig.xml配置文件,修改内容如下:
在标签后填写如下内容
data-config.xml再conf目录下创建data-config.xml文件,内容如下
3.1单表同步至solr的data-config.xml配置:
<?xml version="1.0" encoding="UTF-8" ?>单表最后再修改conf下的managed-schema,修改内容如下
3.2多表关联查询结果同步至solr的data-config.xml配置:
<?xml version="1.0" encoding="UTF-8" ?>多表关联最后再修改conf下的managed-schema,修改内容如下
4、重启solr,在页面上进行如下操作,即可将数据从sqlserver同步到solr中
停止命令:solr.cmd stop all
启动命令:solr.cmd start
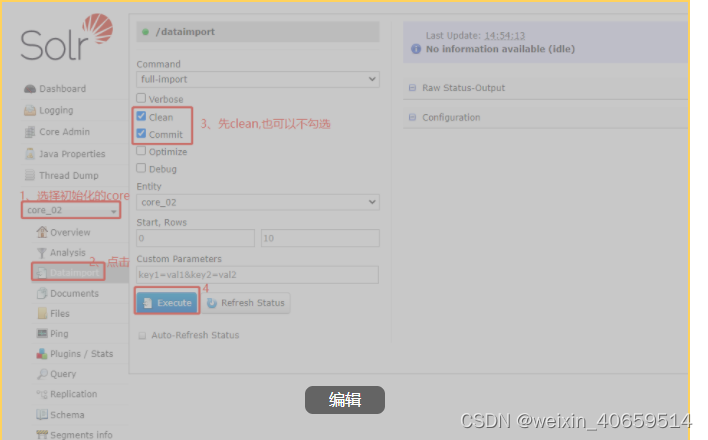
或者直接点击下面链接即可实现全量导入:
http://localhost:8983/solr/core_04/dataimport?command=full-import&clean=true&commit=true&wt=json&indent=true&verbose=false&optimize=false&debug=false&id=1
5、简单查询一下同步结果
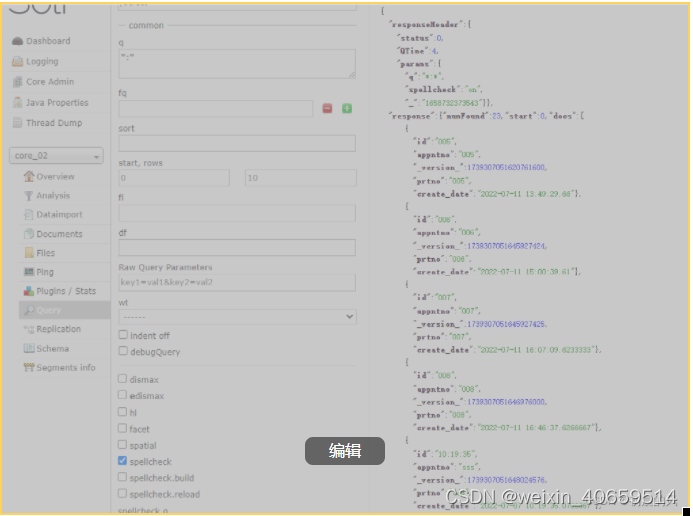
通过API方式
通过编写solr API方式将sqlserver数据同步到solr中,此代码参数主要有要同步的solrcore名称,关系型表的主键、数据库用户名、密码、驱动器、数据库连接地址、要操作的数据库名称、solr连接地址以及同步方式(增量同步还是初始化),
因此一个代码可以实现增量和全量的自动切换。
具体代码如下:
public class SyncDateToSolr {
public static void main(String[] args) {
String tableName = “”;
String uniqueKey = “”;
String userName = “”;
String password = “”;
String driver = “”;
String solrurl = “”;
String dburl = “”;
String db = “”;
String mode = “”;
if(args.length < 9){
System.out.println("程序没有参数退出");
System.exit(0);
}else{
tableName = args[0];
uniqueKey = args[1];
userName = args[2];
password = args[3];
driver = args[4];
solrurl = args[5];
dburl = args[6];
db = args[7];
mode = args[8];
}
Properties proper = GetProperties.getProper();
String sql = proper.getProperty(tableName);
String sqlUrl = dburl+";DatabaseName="+db;
try {
saveSqlserverToSolr(tableName,uniqueKey,sql,userName,password,driver,solrurl,sqlUrl,mode);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("程序执行结束");
}
public static void saveSqlserverToSolr(String core,String key,String sql,String USERNAME,String PASSWORD,String DRIVERNAME,String solrUrl,String sqlurl,String mode) throws Exception{
String yesday = DateUtil.getYesterDate();
String solrurl = "";
String selectSqlInc = "";
if(mode.equals("inc")){
selectSqlInc = sql + yesday+"';";
solrurl = solrUrl+core;
}else{
selectSqlInc = sql;
core=core.replaceAll("\\d+","");
solrurl = solrUrl+core;
}
Connection connection;
PreparedStatement preparedStatement;
HttpSolrClient solrClient = new HttpSolrClient.Builder(solrurl).withConnectionTimeout(10000).withSocketTimeout(60000).build();
Class.forName(DRIVERNAME);
connection = DriverManager.getConnection(sqlurl, USERNAME, PASSWORD);
System.out.println("拼接sql:"+selectSqlInc);
Statement sm = connection.createStatement();
ResultSet rs = sm.executeQuery(selectSqlInc);
ResultSetMetaData metaData = rs.getMetaData();
int count = metaData.getColumnCount();
String[] keys = key.split(",");
StringBuffer sb = new StringBuffer();
int m=0;
while (rs.next()) {
SolrInputDocument doc = new SolrInputDocument();
for(int i = 1;i <= count;i++){
String columnName = metaData.getColumnName(i);
String value = rs.getString(columnName);
for(int j = 0;j < keys.length;j++){
if(keys[j].equals(columnName)){
sb.append(value).append("_");
}else{
continue;
}
}
doc.setField(columnName,value);
}
sb.delete(sb.length()-1,sb.length());
doc.setField("id", sb.toString());
sb.delete(0,sb.length());
solrClient.add(doc);
m++;
System.out.println("已经处理:"+m+"条数据了");
}
solrClient.commit();
solrClient.close();
sm.close();
connection.close();
}
}
代码中读取配置文件的代码如下:
public class GetProperties {
public static Properties getProper() {
Properties properties = new Properties();
try {
//增量,一天
// InputStream is = GetProperties.class.getClassLoader().getResourceAsStream(“inc_sql.properties”);
//全量
InputStream is = GetProperties.class.getClassLoader().getResourceAsStream(“full_sql.properties”);
properties.load(is);
} catch (Exception e) {
e.printStackTrace();
}
return properties;
}
}
其中full_sql.properties的文件内容如下:
am_message_info1=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021110’
am_message_info2=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021111’
am_message_info3=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021112’
am_message_info4=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021113’
am_message_info5=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021100’
am_message_info6=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021101’
am_message_info7=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021102’
am_message_info8=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021103’
am_message_info9=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021090’
am_message_info10=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021091’
am_message_info11=select massid,guid,massage,tm from am_message_info where left(CONVERT(varchar(100), tm, 112),7)=‘2021092’
此代码的是打包上传到linux执行,架包的名称为:Solr_Study-1.0-SNAPSHOT.jar,具体执行的脚本如下:
#!/bin/bash
#while [ true ]
#do
#数据库用户名
username=sa
password=atmk!123
driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
solrurl=http://172.18.255.197:8983/solr/
dburl=jdbc:sqlserver://172.18.255.197:1433
db=sy_bd
mode=full
#获取当前小时
h=date "+%H"
#获取当前分钟
m=date "+%M"
#每天凌晨3点10分跑定时任务
if [[ KaTeX parse error: Expected 'EOF', got '&' at position 13: h -eq 15 ]] &̲& [[ 4 -eq 4 ]]…(cd "$(dirname "
0
"
)
"
;
p
w
d
)
c
o
n
f
p
a
t
h
=
0")"; pwd) confpath=
0")";pwd)confpath={dir}/conf
for line in cat ${confpath}/inc_save_data.properties
do
table_flag=KaTeX parse error: Expected '}', got 'EOF' at end of input: …ine%%:*} if [ xtable_flag == x"exe_table" ];then
table_nm=${line%%#*}
table_nm=${table_nm:10}
line=KaTeX parse error: Expected '}', got '#' at position 6: {line#̲*\#} key_flag={line%%😗}
key=“”
if [ x k e y f l a g = = x " k e y " ] ; t h e n k e y = {key_flag} == x"key" ];then key= keyflag==x"key"];thenkey={line%%#*}
key=${key:4}
java -jar Solr_Study-1.0-SNAPSHOT.jar $table_nm $key $username $password $driver $solrurl $dburl $db $mode
fi
fi
done
其中配置文件inc_save_data.properties内容如下:
exe_table:am_message_info1#key:massid#
exe_table:am_message_info2#key:massid#
exe_table:am_message_info3#key:massid#
exe_table:am_message_info4#key:massid#
exe_table:am_message_info5#key:massid#
exe_table:am_message_info6#key:massid#
exe_table:am_message_info7#key:massid#
exe_table:am_message_info8#key:massid#
exe_table:am_message_info9#key:massid#
exe_table:am_message_info10#key:massid#
exe_table:am_message_info11#key:massid#
exe_table:am_message_info12#key:massid#
exe_table:am_message_info13#key:massid#
exe_table:am_message_info14#key:massid#
exe_table:am_message_info15#key:massid#
5、solr索引增量同步方式
5.1 通过配置方式实现增量同步:
5.1.1、修改data-config.xml内容:
<?xml version="1.0" encoding="UTF-8" ?>5.1.2 再修改managed-schema,内容如下:
注意:用于增量的字段类型设置成pdate
或者定时访问下面链接即可实现增量导入:
http://localhost:8983/solr/core_04/dataimport?command=delta-import&clean=false&commit=true&wt=json&indent=true&verbose=false&optimize=false&debug=false
5.2 实时性要求高的话,可以在调用接口时调用api方式同步数据
5.2.1 假如新增或修改一条数据时,也将数据同步到solr的代码实现方式
再执行保存数据到sqlserver时,也调用保存数据到solr的接口,实现数据实时同步
//将数据保存到sqlserver代码:
@Insert(“insert into AM_ELECTRO_DATA(guid,tm,acc_pc) values(#{guid},#{tm},#{acc_pc})”)
public void saveData(AM_ELECTRO_DATA_TWO en);
//将数据保存到solr代码
@Override
public void saveData(AM_ELECTRO_DATA_TWO en) throws Exception {
SolrInputDocument doc = new SolrInputDocument();
doc.addField(“id”,en.getGuid());
doc.addField(“guid”,en.getGuid());
doc.addField(“tm”,en.getTm());
doc.setField(“acc_pc”,en.getAcc_pc());
solrClient.add(doc);
//solrClient.commit(“AM_ELECTRO_DATA”);
solrClient.commit();
}
5.2.2 在进行删除数据时,同时删除sqlserver和solr
//删除sqlserver数据代码
@Delete(“delete from AM_ELECTRO_DATA where guid=#{id}”)
public void deleteByID(String id);
//删除solr数据代码
@Override
public void deleteByID(String id) throws Exception {
//solrClient.deleteById(“AM_ELECTRO_DATA”,id);
solrClient.deleteById(id);
solrClient.commit();
}
5.3 实时性要求不高的话,可以T+1调用API方式同步的方式:
api的方式和初始化的api是一样的,就是将shell脚本中的mode有full改为inc即可
6、sqlserver和solr性能对比
总之来说,solr在数据量比较大和模糊查询性能要比sqlserver高很多
6.1 数据量为8263649性能对比
sqlserver耗时:0.566
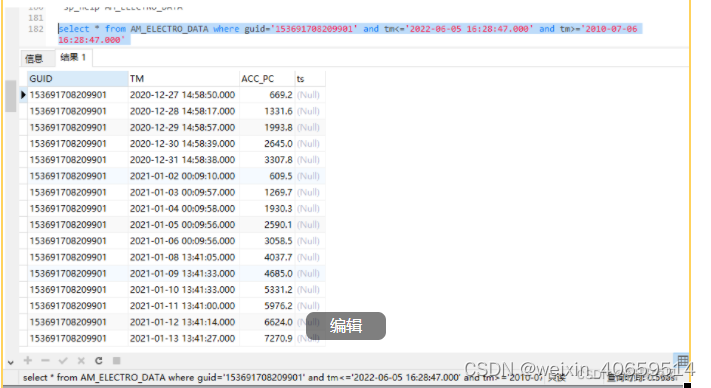
solr耗时:0.960
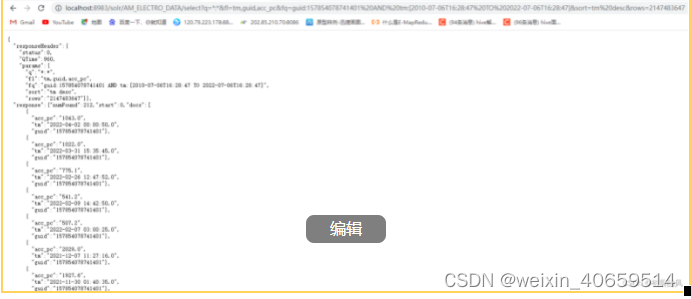
6.2 数据量为34898880性能对比
sqlserver耗时:6.527
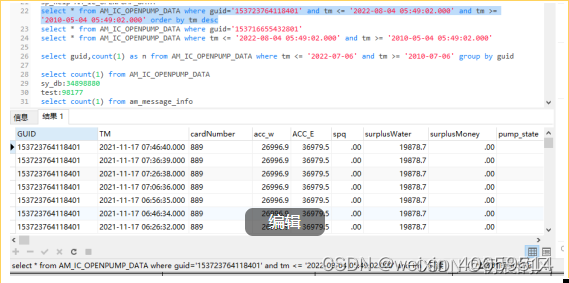
solr耗时:0.912
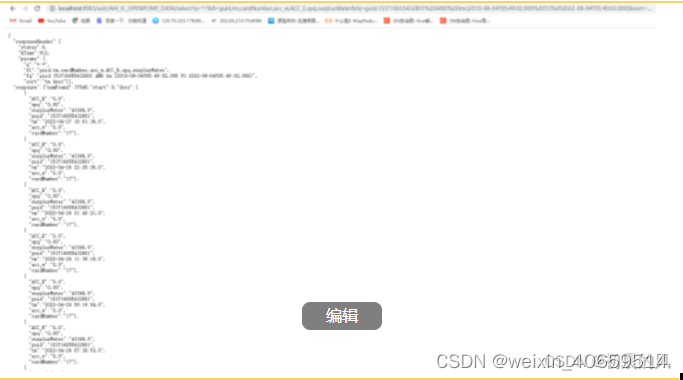
6.3 数据量为一亿两千万的数据
sqlserver耗时:55.528
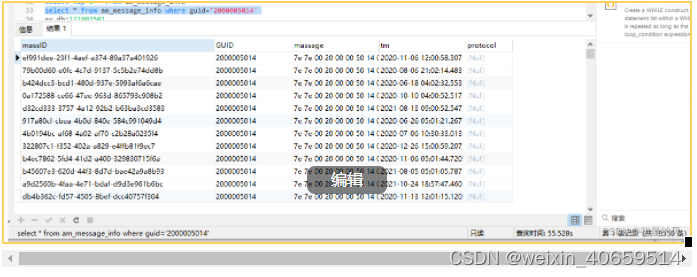
solr耗时:0.354
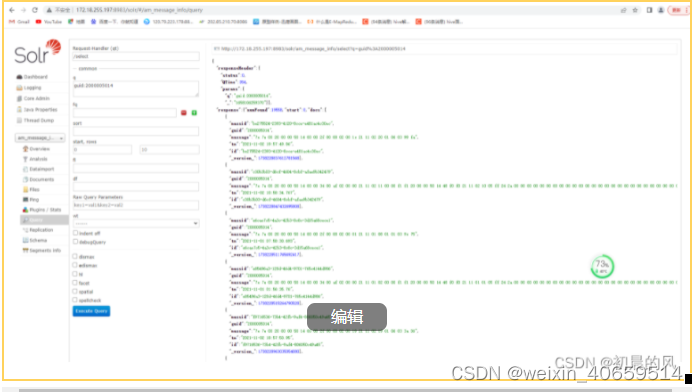
6.4 模糊查询性能对比
数据量:8263649
sqlserver查询用时:68.394
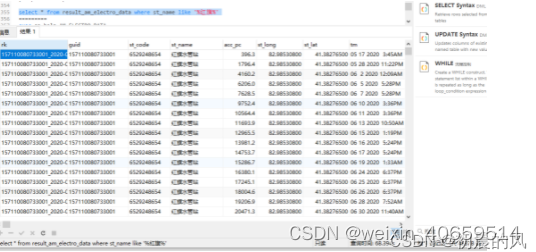
solr查询用时:0.346















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









