






自 2012 年以来,人工智能模型训练算力需求每 3-4 个月翻一番,每年人工智能训练模型所需算力增长幅度高达 10 倍。这就带来了一个挑战:我们如何让 AI 更快、更高效?答案可能就藏在光的世界里。
光学计算, 一个充满潜力的领域,主张利用光的速度和特性将机器学习应用的速度和能效提升到新的高度。但是,要实现这一目标,我们必须解决一个难题:如何有效地训练这些光学模型。过去,人们依赖于数字计算机来模拟和训练光学系统,但受限于光学系统所需的精确模型和大量的训练数据,这使得光学系统的能力受到了极大的限制。而且,随着系统复杂性的增加,这些模型的建立和维护变得越来越困难。
近期,清华大学戴琼海院士、方璐教授研究团队抓住了光子传播具有对称性这一特性,将神经网络训练中的前向与反向传播都等效为光的前向传播,开发出了一种全前向模式 (FFM, fully forward mode) 学习的方法。 通过 FFM 学习,研究人员不仅能够训练出具有数百万参数的深层光学神经网络 (ONNs),还能实现超敏感的感知和高效率的全光学处理,从而减轻了 AI 对光学系统建模的限制。
该研究以「Fully forward mode training for optical neural networks」为题,成功登上顶级期刊 Nature。
研究亮点:
-
实现了在现场高效地并行进行机器学习操作,减轻了数值建模的限制
-
推出了对于给定网络规模具有最先进性能的光学系统,FFM 学习也表明,训练具有数百万参数的最深光学神经网络可达到与理想模型相当的精度
-
FFM 学习不仅促进了快几个数量级的学习过程,还可以推动深度学习神经网络、超灵敏感知和拓扑光子学等领域的发展

论文地址:
https://doi.org/10.1038/s41586-024-07687-4
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
7 大数据集汇聚,在多层分类实验中创建相位设置为零的输入复场
该研究共使用了 7 种数据集,在多层分类实验中,每个样本均被用于创建相位设置为零的输入复场 (input complex field):
MNIST 数据集。 该数据集是一个包含 10 个类别的手写数字集合,由 6 万个训练样本和 1 万个测试样本组成。
Fashion-MNIST 数据集。 该数据集包含 10 个不同类别的时尚产品,同样由一个 6 万个样本的训练集和一个 1 万个样本的测试集组成。
CIFAR-10 数据集。 该数据集是 8 千万小图像数据集的一个子集,包含 5 万个训练图像和 1 万个测试图像。
ImageNet 数据集。 该数据集是一个由 WordNet 层次结构组成的图像数据库,在该层次结构中,每个节点由成百上千张图像描绘,总共有 1.2 亿张用于训练的图像和 5 万张用于测试的图像。
MWD 数据集。 该数据集包含 4 种不同户外场景(日出、晴天、下雨和多云)的天气状况图像。它总共包含 1,125 个样本,其中 800 个用于训练,325 个用于测试。
鸢尾花数据集。 该数据集由 3 种鸢尾花物种组成,每个物种有 50 个样本。数据集中的每个原始样本包含四个描述鸢尾花形状的条目。在 PIC 实验中,每个条目都被复制以创建四个相同的数据点,最后产生总共 16 通道的输入数据。
Chromium target 数据集。 该数据集由带有不同区域(反射区和半透明区)的玻璃铬板组成。反射区代表物理场景本身(字母目标 T、H 和 U),在训练过程中,使用单个反射区,并在同一平面内移动以产生 9 个不同的训练场景。
光学系统进行重新参数化,构建可微嵌入式光子神经网络 FFM
传统意义上,光学相关的人工智能都是通过离线建模和优化进行设计的,如下图 a 所示,这会导致设计效率和系统性能有限。不仅如此,一般的光学系统为了实现各种功能,会根据根据折射率的可调谐特性 (tunability),将光学系统分为调制区 (modulation regions,深绿色) 和传播区 (propagation regions,浅绿色) 两个不同的区域, 如下图 b 所示。
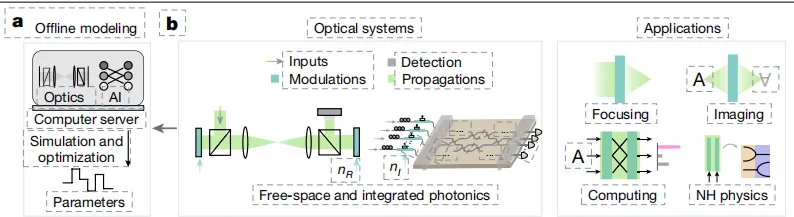
传统光学系统的设计图示
该研究发现,由麦克斯韦方程组控制的光学系统可以被重新参数化为可微嵌入式光子神经网络,且神经网络的梯度下降训练一直是推动其发展的关键因素。因此,该研究对于 FFM 的机器学习原理构建下图 c 所示, 由于光学系统中的部分区域可以映射到神经网络中与神经元连接,从而可以在输入和输出之间构建一个可微分的现场神经网络 (onsite neural network)。
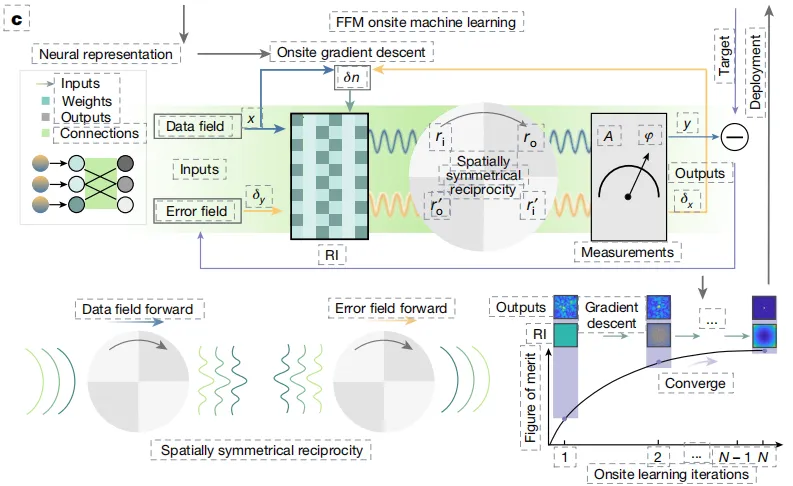
FFM 的机器学习原理
紧接着,该研究利用空间对称互易性,数据和误差计算共享前向物理传播和测量,并且计算现场梯度 (onsite gradients) 以更新设计区域 (图 c 右上及左下区域) 的折射率。通过现场梯度下降,光学系统逐渐收敛 (图 c 右下区域)。
训练可用于对象分类的单层光神经网络,FFM 学习可达到与理想模型相当的精度
为了展示 FFM 学习的有效性,该研究首先使用基准数据集训练了一个用于对象分类的单层光神经网络,然后在下图 a 中展示了使用 FFM 学习的深度自由空间中光神经网络的自训练过程,并在下图 b 中可视化了其在 MNIST 数据集上的训练结果。
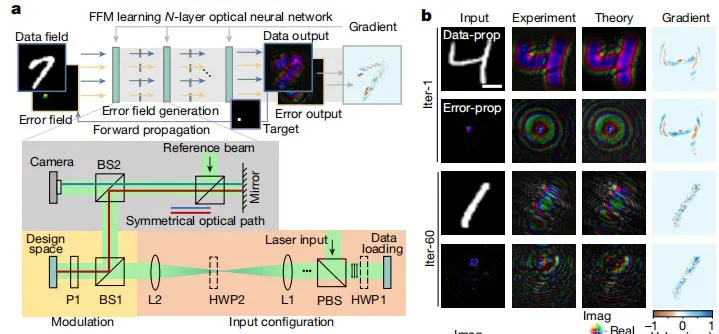
单层光神经网络训练图解
如下图 c 所示,实验光场和理论光场之间的结构相似性指数 (SSIM) 超过 0.97, 这表明相似性水平很高。而在下图 d 中,该研究进一步分析了多层光神经网络用于 Fashion-MNIST 数据集的分类。通过将层数从 2 逐步增加到 8,该研究发现利用 FFM 学习,神经网络性能可提高到 86.5%、91.0%、92.3% 和 92.5%,接近理论上的计算机模拟准确率。
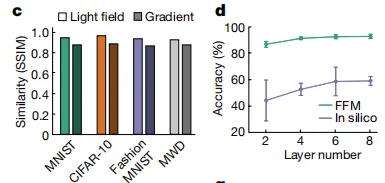
多层光神经网络的训练结果
基于上述结果,该研究进一步提出非线性 FFM 学习,如下图 f 所示。在数据传播过程中,输出在进入下一层之前均进行了非线性激活,从而可记录非线性激活的输入并计算相关梯度。由于只需要前向传播,FFM 所提出的非线性训练范例适用于一般可测量的非线性函数,因此适用于光电和全光非线性光神经网络。不仅如此,非线性光神经网络的分类准确率从 90.4% 提高到 93.0%, 如下图 g 所示。
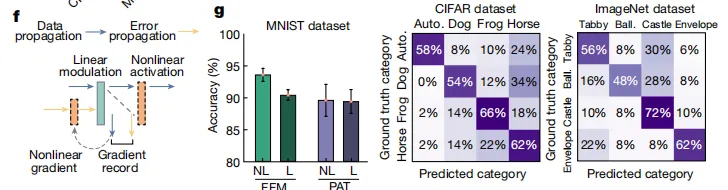
非线性 FFM 学习的训练结果
FFM 学习简化了复杂光子系统的设计,可实现全光现场重建和动态隐藏物体的分析
该研究还发现,FFM 学习克服了离线数值建模施加的限制,并简化了复杂光子系统的设计。 例如,该研究在下图 a, b 中分别展示了点扫描散射成像系统,以及利用粒子群优化 (PSO) 分析各种先进的优化方法。结果显示,基于梯度的 FFM 学习显示出更高的效率,在两个实验中经过 25 次设计迭代后收敛,在两种散射类型中的收敛损失值分别为 1.84 和 2.07。相比之下,PSO 方法至少需要 400 次设计迭代才能收敛,最终损失值为 2.01 和 2.15。
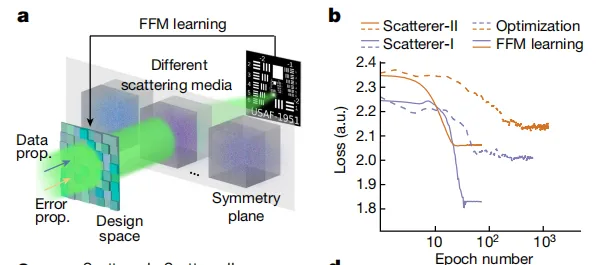
图示点扫描散射成像系统与优化方法比较
如下图 c 所示,该研究分析了 FFM 自设计的演变,显示出最初随机分布的强度轮廓逐渐收敛到一个紧密的点。在下图 d 中,该研究进一步比较了使用 FFM 和 PSO 优化焦点的半高全宽 (FWHM) 和峰值信噪比 (PSNR) 指标。在使用 FFM 的情况下,平均 FWHM 为 81.2 微米,平均 PSNR 为 8.46 分贝。
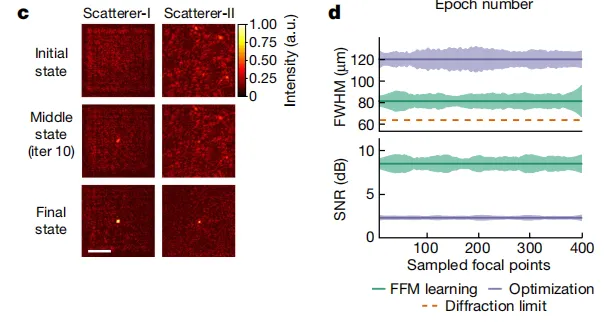
FFM 自设计演变分析与 PSO 优化焦点对比
该研究还发现,现场 FFM 学习为设计非常规成像模式提供了一个有价值的工具,特别是在无法精确建模的情况下, 如非视距任务 (NLOS) 等场景。如下图 a 所示,FFM 学习实现了全光现场重建和动态隐藏物体的分析。下图 b 则展示了 NLOS 成像。FFM 设计的波前恢复了所有 3 个字母的形状,每个目标的结构相似性指数达到 1.0。
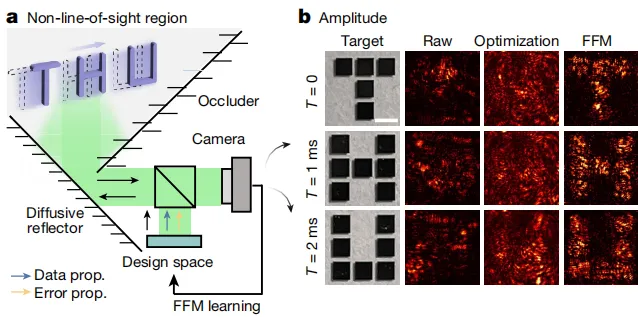
非常规成像模式与 NLOS 成像图示
除了动态成像能力外,FFM 学习方法还允许对 NLOS 区域中的隐藏物体进行全光学分类。该研究比较了 FFM 与人工神经网络 (ANN) 的分类性能。结果如下图 c 所示,在有足够光子的情况下,FFM 和 ANN 具有相似的性能,但 FFM 仅需要更少的光子进行准确分类。
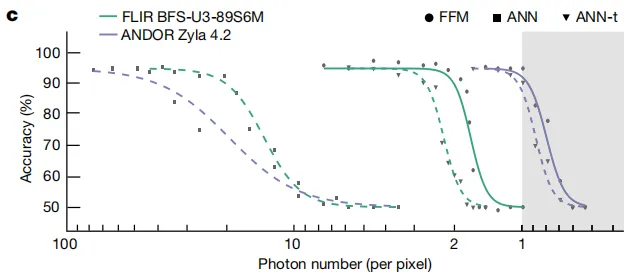
FFM 与 ANN 的分类性能比较
FFM 学习可扩展到集成光子系统的自设计,模拟需要大约 100 个周期才能收敛
该研究发现,FFM 学习方法可扩展到集成光子系统的自设计。如下图 a 所示,该研究使用串联和并联连接而成的对称光子核组成的集成神经网络来实现 FFM 学习。结果显示,矩阵的对称性允许误差传播矩阵和数据传播矩阵具有等效性。
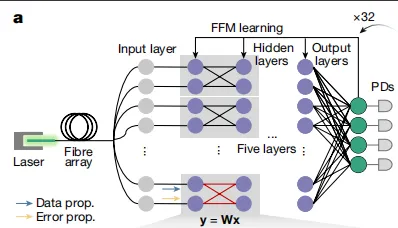
FFM 在集成光子系统的扩展
下图 e 对整个神经网络的误差进行了可视化。结果显示,在第 80 次迭代时,FFM 学习显示出比计算机模拟训练更低的梯度误差。
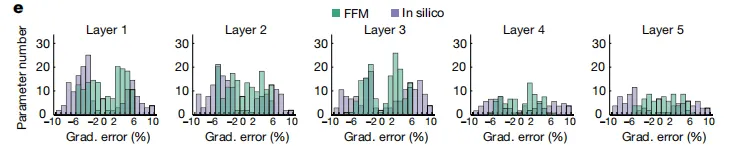
神经网络误差的可视化
而在设计精度的演变中,如下图 f 所示,理想模拟和 FFM 实验都需要大约 100 个周期才能收敛,但 FFM 方法的精度最优。
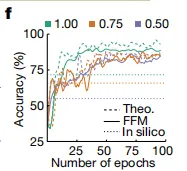
理想模拟与 FFM 的设计精度对比
智能光计算产业链已经逐步成熟,或将站上新时代风口
值得一提的是,基于本篇论文的研究成果,研究团队推出了「太极-II」光训练芯片。 「太极-II」的研发距离上一代「太极」仅过了 4 个月,相关成果也登上了 Science。论文的实验结果显示,「太极」的能效是英伟达 H100 的 1,000 倍。 这种强大的计算能力正是基于研究团队首创的分布式广度智能光计算架构。
论文链接:
https://www.science.org/doi/10.1126/science.adl1203
借由太极系列新产品的推出,智能光计算再次在引爆业内。 但在现实层面来看,无论是物理硬件,还是软件开发,亦或者应用方面,智能光计算都还需要进一步优化与探索。事实上,智能光计算的研究体系已经日臻成熟,北京大学、浙江大学、华中科技大学等多家院所高校均涉足其中,相关学术交流也日益频繁。但在具体的应用方向,不同高校领军人物为代表的研究团队各有侧重。例如:
清华大学戴琼海院士团队: 该团队正是本篇论文的作者,他们所研发的下一代 AI 光电融合芯片,已经完成了在智能图像识别、交通场景、人脸唤醒等应用场景的实验。据报道,相同准确率下,该团队的研究成果比现有 GPU 算力提升 3 千倍,能效提高 400 万倍,有望颠覆自动驾驶、机器人视觉、移动设备等领域的传统计算思路。
华中科技大学董建绩团队: 该团队研发的光电混合芯片,完成了人类表情识别的应用。
上海交通大学徐绍夫团队: 该团队研发的系列光电融合芯片,完成了人工智能、信号处理等方面的应用,完成了医学图像重构等方面的计算实验。
可喜的是,在研究人员的不懈努力下,我国的智能光计算芯片的进度已经与国外基本基本持平。过去 5 年间,全球范围内布局光计算的公司从零星几家,迅速增加到了数十家。在国外,最具代表性的是致力于打造全球首屈一指人工智能超级计算机的 Luminous Computing,以及用光子技术提升 AI 和高性能计算工作负载的性能和节能水平的 Lightmatter,这两家公司也均已获得超过 1 亿美元的融资。
在国内,以曦智科技、光子算数为代表的企业也已经加入国际光计算产业竞争领域。 这些初创公司都以光计算为核心,主打基于光芯片的光计算加速器,并配套开展软件、系统、原理机的研制与开发。总之,我国的光计算产业链已经逐步成熟,相关的产学研体系已经有效运转并高效落地。我们也期待,在这个新时代的风口,智能光计算能够为数字经济与新质生产力的发展提供澎湃动能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









