







 随着技术的发展,前后端数据交互变得复杂。本文探讨了 GraphQL 作为前后端数据交互方案的原因,包括其出现的必然性和语言设计的必然性。通过对比 RESTful API,文章阐述了 GraphQL 如何通过其查询语言设计、按需获取数据和精确传递数据的能力,解决了传统接口的不足。此外,文章介绍了 GraphQL 的组成与工作原理,展示了如何构建 GraphQL 服务并讨论了其实现灵活性。作者坚信 GraphQL 在 BFF 和微前端架构中具有巨大潜力。
随着技术的发展,前后端数据交互变得复杂。本文探讨了 GraphQL 作为前后端数据交互方案的原因,包括其出现的必然性和语言设计的必然性。通过对比 RESTful API,文章阐述了 GraphQL 如何通过其查询语言设计、按需获取数据和精确传递数据的能力,解决了传统接口的不足。此外,文章介绍了 GraphQL 的组成与工作原理,展示了如何构建 GraphQL 服务并讨论了其实现灵活性。作者坚信 GraphQL 在 BFF 和微前端架构中具有巨大潜力。
随着多终端、多平台、多业务形态、多技术选型等各方面的发展,前后端的数据交互,日益复杂。
同一份数据,可能以多种不同的形态和结构,在多种场景下被消费。
在理想情况下,这些复杂性可以全部由后端承担。前端只管从后端接口里,拿到已然整合完善的数据。
然而,不管是因为后端的领域模型,还是因为微服务架构。作为前端,我们感受到的是,后端提供的接口,越发不够前端友好。我们必须自行组合多个后端接口,才能获取到完整的数据结构。
面向领域模型的后端需求,跟面向页面呈现的前端需求,出现了不可调和的矛盾。
在这种背景下,本着谁受益谁开发的原则。我们最后选择使用 Node.js 搭建专门服务于前端页面呈现的后端,亦即 Backend-For-Frontend,简称 BFF。
我们面临了很多不同的技术选型,主要围绕在权衡 RESTful API 和GraphQL。
正如标题所示,我们最终选用的是 GraphQL。
本文将介绍我们对 GraphQL 所作的考察、探索、权衡、技术选型与设计等多方面的内容,希望能给大家带来一些启发。
一、GraphQL 模式出现的必然性
面向前端页面的数据聚合层,其接口很容易在迭代过程中,变得愈加复杂;最终发展成一个超级接口。
它有很多调用方,各种不同的调用场景,甚至多个不同版本的接口并存,同时提供数据服务。
所有这些复杂性,都会反映到接口参数上。
接口调用的场景越多,它对接口参数结构的表达能力,要求越高。如果只有一个 boolean 类型的参数,只能满足 true | false 两种场景罢了。
以产品详情接口为例,一种很自然的请求参数结构如下:
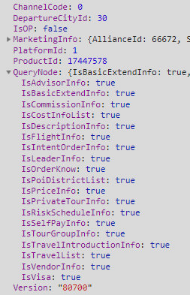
里面包含 ChannelCode 渠道信息,IsOp 身份信息,MarketingInfo 营销相关的信息,PlatformId 平台信息,QueryNode 查询的节点信息,以及 Version 版本信息。最核心的参数 ProductId,被大量场景相关的参数所围绕。
审视一下 QueryNode 参数,很容易可以发现,它正是 GraphQL 的雏形。只不过它用的是更复杂的 JSON 来描述查询字段,而 GraphQL 用更简洁的查询语句,完成同样的目的。
并且,QueryNode 参数,只支持一个层级的字段筛选;而 GraphQL 则支持多层级的筛选。
GraphQL 可以看作是 QueryNode 这种形式的参数设计的专业化。相比用 JSON 来描述查询结果,GraphQL 设计了一个更完整的 DSL,把字段、结构、参数等,都整合到一起。
仿照格林斯潘第十定律:
任何C或Fortran程序复杂到一定程度之后,都会包含一个临时开发的、不合规范的、充满程序错误的、运行速度很慢的、只有一半功能的Common Lisp实现。
或许可以说:
任何接口设计复杂到一定程度后,都会包含一个临时开发的、不合规范的、只有一半功能的 GraphQL 实现。
从 SearchParams, FormData 到 JSON,再到 GraphQL 查询语句,我们看到不断有新的数据通讯方式出现,满足不同的场景和复杂度的要求。
站在这个层面上看,GraphQL 模式的出现,有一定的必然性。
二、GraphQL 语言设计中的必然性
作为一个查询相关的 DSL,GraphQL 的语言设计,也不是随意的。
我们可以做一个思想实验。
假设你是一名架构师,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









