







Hadoop是一个开源的分布式计算框架,它可以处理大规模的数据集。Hadoop的核心组件是Hadoop分布式文件系统(HDFS)和MapReduce编程模型。Hadoop还包括一些其他的子项目,如Hive,Pig,Spark等,提供了不同层次的数据处理能力。
本文将介绍如何在Ubuntu系统中安装配置Hadoop
目录
集群规划
| hadoop100 | hadoop200 | hadoop201 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | ResourceManager NodeManager | NodeManager | NodeManager |
配置虚拟机
0、安装vim工具
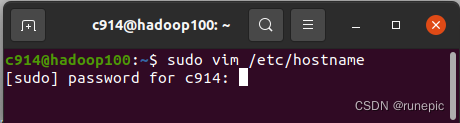
sudo apt install vim1、修改虚拟机名
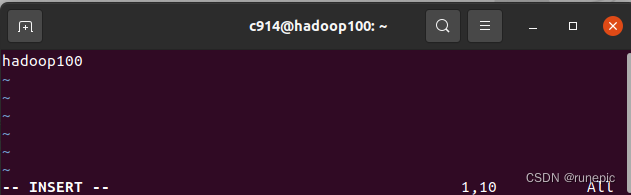
sudo vim /etc/hostname 键入密码,sudo进入管理员权限修改
输入 i ,进入编辑模式,编辑修改,Esc 然后 :wq 保存退出
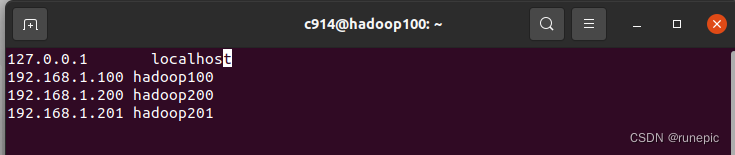
2、配置虚拟机之间的映射文件
sudo vim /etc/hosts同样方式编辑保存
3、设置ip
可以从Ubuntu网络设置里面配置,之前文章有提及,也可按照如下方式配置:
sudo gedit /etc/netplan/01-network-manager-all.yaml修改如下:
# Let NetworkManager manage all devices on this system
network:
version: 2
renderer: NetworkManager
ethernets:
ens33:
dhcp4: false
optional: true
addresses: [192.168.1.100/2]
gateway4: 192.168.1.2
nameservers:
addresses: [192.168.1.2,8.8.8.8,8.8.4.4]参数含义:addresses 地址 子网掩码;gateway4网关;addresses dns
虚拟机重启网络服务
service network restart4、克隆虚拟机
VMware中克隆出另外两台虚拟机,根据设置的ip地址,修改三台虚拟机的/etc/hosts中的ip地址,以及主机名,ip配置文件如下:
# Let NetworkManager manage all devices on this system
network:
version: 2
renderer: NetworkManager
ethernets:
ens33:
dhcp4: false
optional: true
addresses: [192.168.1.200/2]
gateway4: 192.168.1.2
nameservers:
addresses: [192.168.1.2,8.8.8.8,8.8.4.4]
# Let NetworkManager manage all devices on this system
network:
version: 2
renderer: NetworkManager
ethernets:
ens33:
dhcp4: false
optional: true
addresses: [192.168.1.201/2]
gateway4: 192.168.1.2
nameservers:
addresses: [192.168.1.2,8.8.8.8,8.8.4.4]配置SSH免密登录
因为三台服务器组成了一个集群,如果不配置免密访问,那么在集群启动时会N多次提示要输入密码,操作如下(三台服务器均如此操作)生成密钥:
ssh-keygen -t rsa # 生成密钥对,一路回车即可
执行下面命令将该三个服务器的密钥文件导入本机的已认证密码集中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh hadoop200 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh hadoop201 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将公共秘钥分发给其他服务器
scp ~/.ssh/authorized_keys c914@hadoop200:/home/c914/.ssh/
scp ~/.ssh/authorized_keys c914@hadoop201:/home/c914/.ssh/
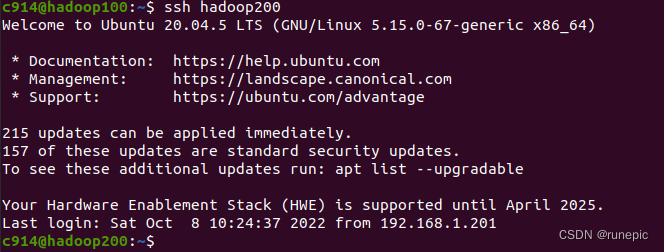
再次使用ssh命令测试是否可以免密访问其他主机
ssh hadoop200
ssh hadoop201
如果没有提示输入密码,说明免密登录已经成功配置。
配置hadoop
1、将官网下载好的压缩包(hadoop-3.2.4.tar.gz)复制到桌面,解压到指定文件夹
tar -zxvf hadoop-3.2.4.tar.gz -C /usr/local/hadoop2、添加环境变量vim ~/.bashrc
修改后刷新source ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin验证
3、修改hadoop配置目录的多个文件 :/usr/local/hadoop/hadoop-3.2.4/etc/hadoop
以下的路径皆需和实际安装文件情况对应
- 运行配置文件 hadoop-env.sh
vim hadoop-env.sh在配置文件中设置 Java 的 Home 路径
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/java/jdk1.8.0_341
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.4
- 编辑配置文件 core-site.xml
vim core-site.xml设置Hadoop 可读写目录,作为数据存储目录,在配置文件中增加如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9000</value>
</property>
<!-- zk地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop100:2181,hadoop200:2181,hadoop201:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/c914/hadooptest/hdata</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>c914</value>
</property>
</configuration>- hdfs-site.xml 配置文件
vim hdfs-site.xml<configuration>
<!--指定HDFS中副本的数量,默认值是3,此处可以省略-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop201:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/c914/hadooptest/hdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/c914/hadooptest/hdata/dfs/data</value>
</property>
</configuration>mapred-site.xml 配置文件
vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME= /usr/local/hadoop/hadoop-3.2.4</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME= /usr/local/hadoop/hadoop-3.2.4</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME= /usr/local/hadoop/hadoop-3.2.4</value>
</property>
</configuration>- yarn-site.xml 配置文件
vim yarn-site.xml添加以下内容,包括之后便于应用
<configuration>
<!-- 指定MapReduce走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.min-healthy-disks</name>
<value>0.0</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>100.0</value>
</property>
</configuration>
- 配置workers
vim workers添加主机名列表
hadoop100
hadoop200
hadoop201分发到其他节点
将整个安装目录发送到其他节点
scp -r /usr/local/hadoop/ c914@hadoop200:/usr/local/
scp -r /usr/local/hadoop/ c914@hadoop201:/usr/local/
启动与关闭
1、启动
hadoop首次启动时需要进行NameNode初始化,只在主节点上操作。
hadoop namenode –format在主节点上启动NameNode
start-all.sh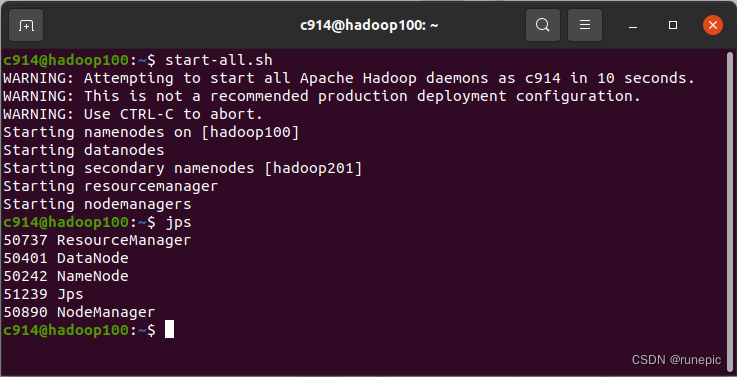
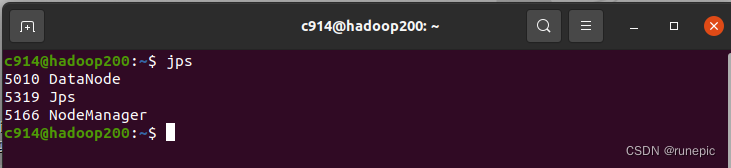
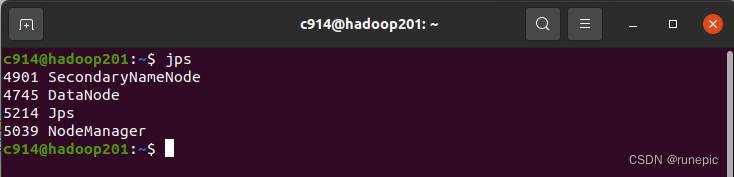
2、关闭
stop-all.sh管理界面
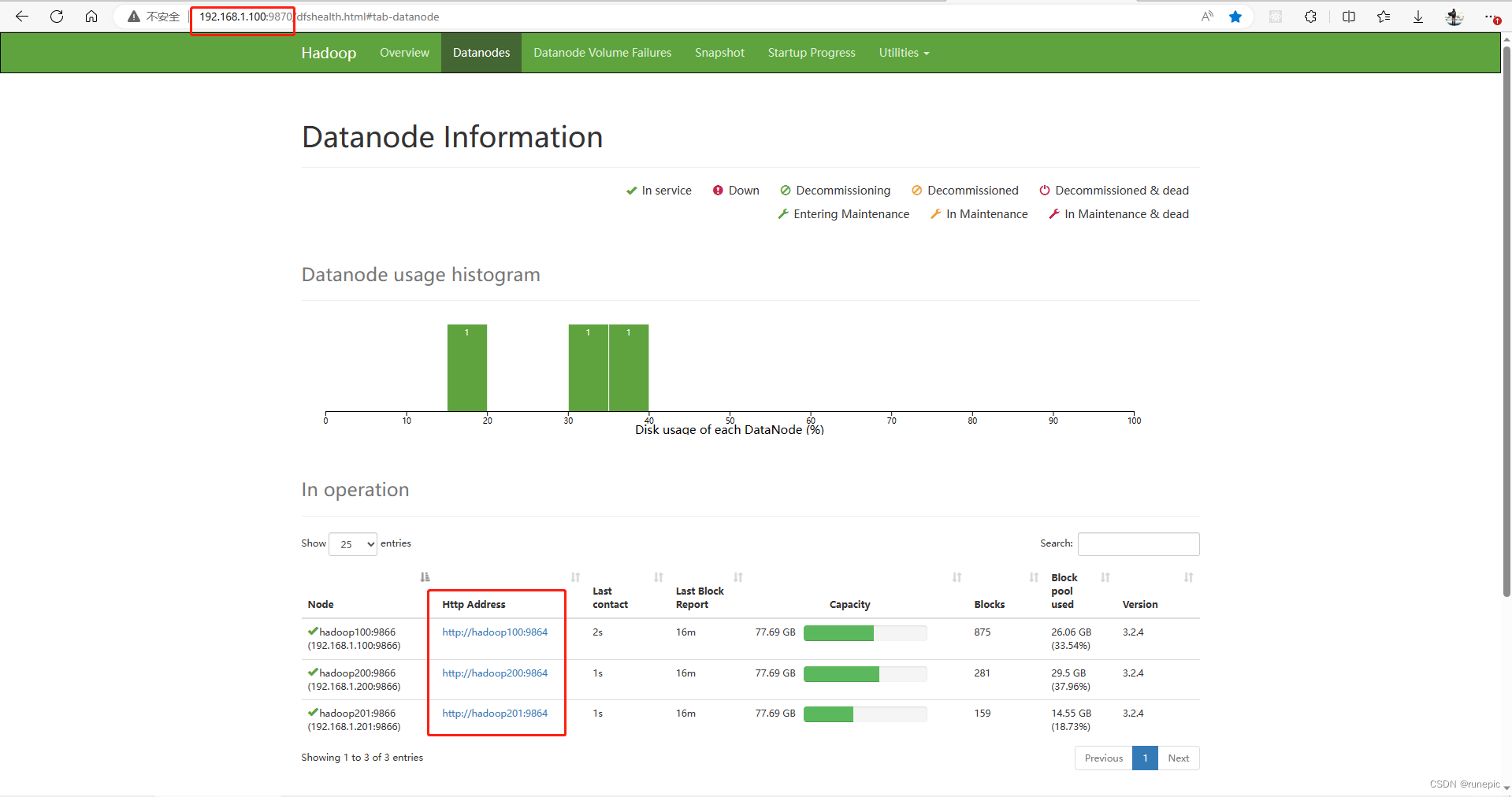
如果上述结果都输出成功,就可以到浏览器中查看网页:
主节点IP地址:9870/ (hdfs所在主机的IP地址,到9870即可,自动跳转)
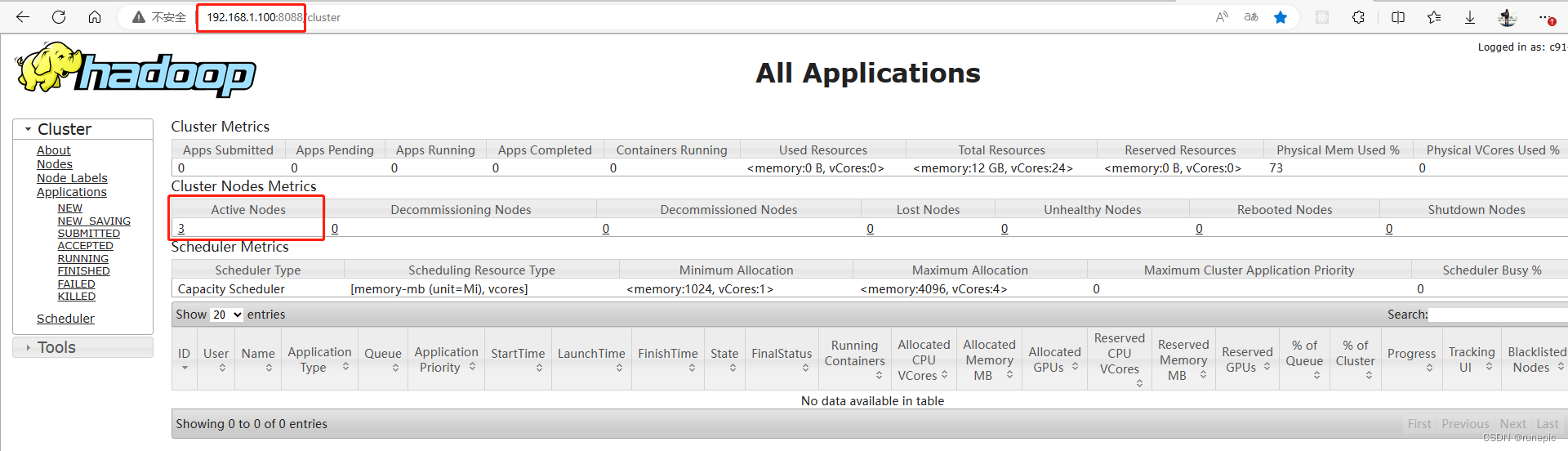
http://192.168.1.100:8088/cluster/
查看8088端口: yarn配置的节点IP地址:8088/cluster (yarn所在的主机的IP地址)

















 3694
3694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











