







 本文深入探讨了特征工程的重要性和实践,涉及时间序列数据(如交通流量)的周期性分析,多特征数据的分布理解,以及缺失值处理策略。特征构造与选择的方法,如基于周期性、相关性分析和机器学习模型的特征构建与重要性评估,都为提升模型精度提供了关键步骤。
本文深入探讨了特征工程的重要性和实践,涉及时间序列数据(如交通流量)的周期性分析,多特征数据的分布理解,以及缺失值处理策略。特征构造与选择的方法,如基于周期性、相关性分析和机器学习模型的特征构建与重要性评估,都为提升模型精度提供了关键步骤。
目录
1.什么是特征工程
很多同学在拿到数据集之后不知道怎么处理,数据决定了模型精度的上限,只有前期对原始数据理解、分析、处理透彻了,才能有助于后期的分类或回归模型的训练。特征工程说白了就是通过一系列数据分析手段不断提升原始数据集的质量,包括但不限于:数据字段(或特征)的理解,数据变量间关系分析,数据预处理中的异常值检测和缺失值填充,特征分析(特征筛选,特征构建等),下面将详细讲述这些内容。
2.原始数据集变量的理解与分析
拿到一个数据集后,首先要对数据中的变量(特征)含义以及变量(特征)分布情况有个初步的了解。不同应用场景的数据集有不同的处理方式和思路,要根据原始数据集的分布规律理解数据,进而选择合适自己数据集的分析方法,下面以时间序列数据和多特征数据为例详细说明。
2.1时间序列数据分析
交通流数据(或共享单车数据)是具有代表性的时间序列数据,该数据可能具有周期性、连续性、随机性和波动性。一般情况下,原始交通流数据集包含两个字段,一个是datetime日期字段,一个是该日期对应的交通流量,可以通过Python查看数据中的字段信息,如下:
import pandas as pd
train=pd.read_csv('D:/traffic/feng.csv')#加载数据,数据路径可根据自己的保存路径读取
train.head()#展示数据的前5行输出结果:
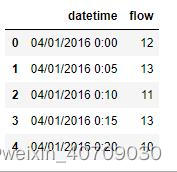
可以看出datetime字段不是数值型,为了便于处理,首先把该字段转换成数值型,分别提取年月日分钟等信息,如下:
#通过pandas将日期划分为year/month/day/time
train['year']=pd.DatetimeIndex(train['datetime']).year
train['month']=pd.DatetimeIndex(train['datetime']).month
train['day']=pd.DatetimeIndex(train['datetime']).day
train['hour']=pd.DatetimeIndex(train['datetime']).hour
train.head(10)
输出结果:
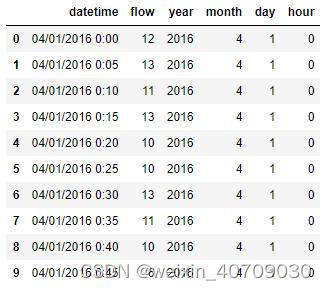
这次打印了10行数据,可以看到生成了新的字段year,month,day,hour。
共享单车数据(kaggle官网下载的数据集,里面涉及到不同领域的竞赛数据集,感兴趣的同学可以去官网看看)也存在同样的问题,datetime字段处理前:
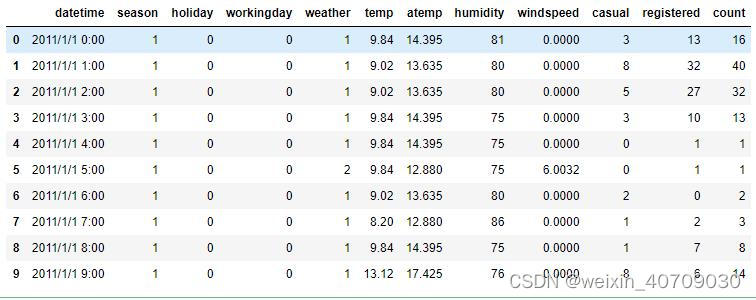
datetime字段处理后:
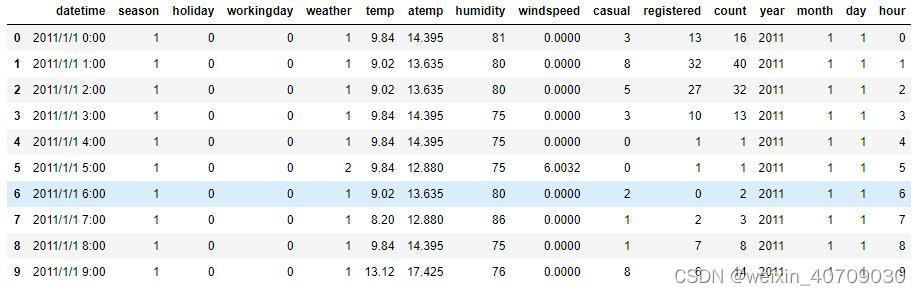
那么数据中变量的具体分布、范围、波动又是什么情况呢?话不多说,先来看看每个字段的统计量,依旧以共享单车数据集为例:
train.describe()输出结果:
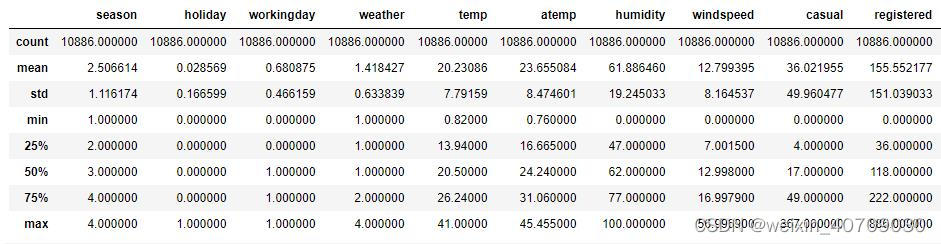
现在就可以看到每个变量的总体数量、均值、方差、最大最小值等信息 。接下来,也可以通过统计图的方式直观的分析每个变量的分布,前面说到,时间序列数据都是有周期性的,大家可以通过Python或者直接在Excel中画出该变量的折线图、直方图等。
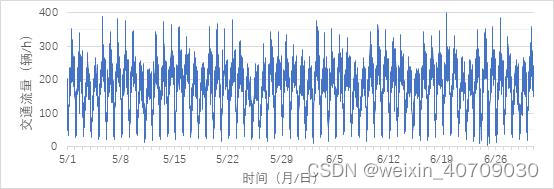
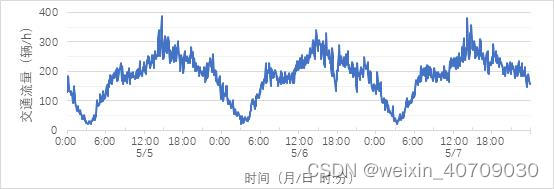
嗯,这样就直观多了,大家可以明显看到交通流数据的周期特性 ,掌握了自己数据集本身的一些分布特性,就可以对症下药,选择合适的方法或者模型进行预测。
2.2 多特征数据分析
多元回归预测是机器学习中非常典型的一种预测案例,有些数据集中包含很多个特征(变量),这些特征的分布以及特征之间的关系是必须要弄清楚的,所谓知己知彼百战不殆。依然可以通过上述方式查看每个特征的统计量:
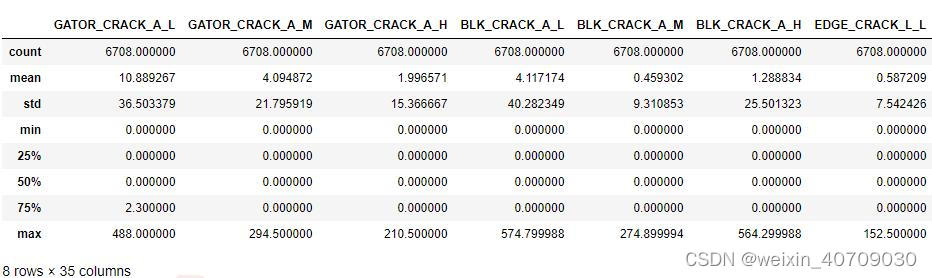
可以看出有35个特征,可以说是很多了。不同的是,这些多特征数据的分布不一定具有周期性甚至有些可能第一眼看上去是毫无规律的。像图片中的数据集,同一个特征的分布范围差异很大,不同特征之间的分布差异也很大。为了避免不同特征变量数据分布差异性导致的模型过拟合现象,可以对原始数据进行归一化操作,把数据映射到0~1范围之内处理。数据归一化是一个非常简单的操作,在这里就不多加赘述了。
像这种多特征数据集,也可以通过Python数据可视化查看多变量间的分布,对特征之间的分布关系有个初步的了解,如下:
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(data,hue='Category')
plt.show()输出结果:
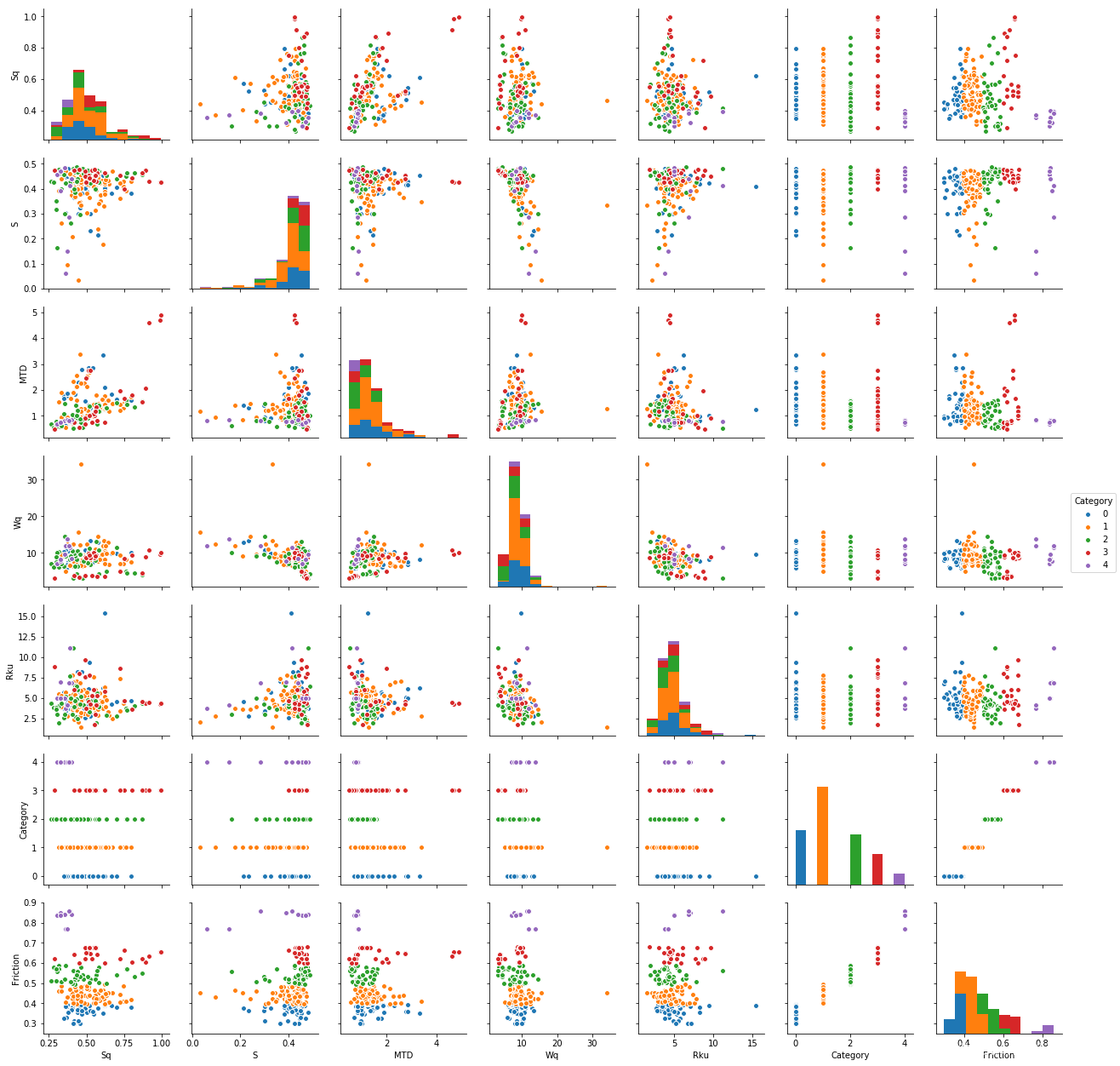
上述多变量分布图可以很清楚地看到每个特征的分布,以及两个特征之间的分布散点图 。当然,也可以查看单个变量的分布,这个就简单很多了,可以学习专门的Python数据可视化课程。
这一part仅仅只是数据集中变量的初步分析与理解,目的是大概知道数据长什么样子,如何分布的。当然,有些数据集中可能存在一些问题,比如异常值、缺失值等,这里重点讲述一些缺失值的处理。
3.数据缺失值处理
首先,还是可以通过Python缺失值可视化查看原始数据集中缺失值的分布情况,如下:
import missingno as msno #missingno库提供了可视化工具来查看数据缺失情况
import pandas as pd
import numpy as np
#数据读取
data_path = 'D:/dataset/'
data = pd.read_csv(data_path + 'IRIyuanshi.csv', encoding='gb2312')
msno.matrix(data, labels=True)

白色表示缺失,黑色表示有值,可以看出缺失值还挺多,这种情况应该怎么办呢?缺失值的处理方法有很多,其中一种最简单粗暴的是直接删除。当然,删除也要有依据。首先,考虑一下自己数据集的大小 ,当数据集足够大,且某几行的缺失值实在是太多,如上图中数据集的情况,其中几行数据几乎全是空白,那就可以酌情删除。
另一种是采用不同的方法进行填充。常见的数据缺失值填充方法包括但不限于:均值、中位数、众数、线性拟合、邻近插值法、多项式插值法、拉格朗日插值法、B样条插值法,三次样条插值法以及基于机器学习模型预测缺失值方法。基于机器学习模型预测方法就是将其他特征作为输入,缺失特征作为输出训练模型,来预测缺失值,这样就将缺失值填充问题转化为回归预测问题。当然,当数据集中缺失值分布较为散乱随机时,预测法就不适用了,可以尝试采用各种插值法。至于用哪一种方法,可以根据自己数据集中缺失值的分布特点决定。
这里给大家安利一个操作简单的数据分析软件spss,具有缺失值填充功能,里面集成了5种不同的缺失值填充算法。首先在软件中导入自己的数据集:
我随便找了一个数据,如下:

可以看到,里面有一些随机缺失,接下来就是填充了,选择“分析”->“缺失值分析” ->“多重归因” ->“归因缺失数据值”
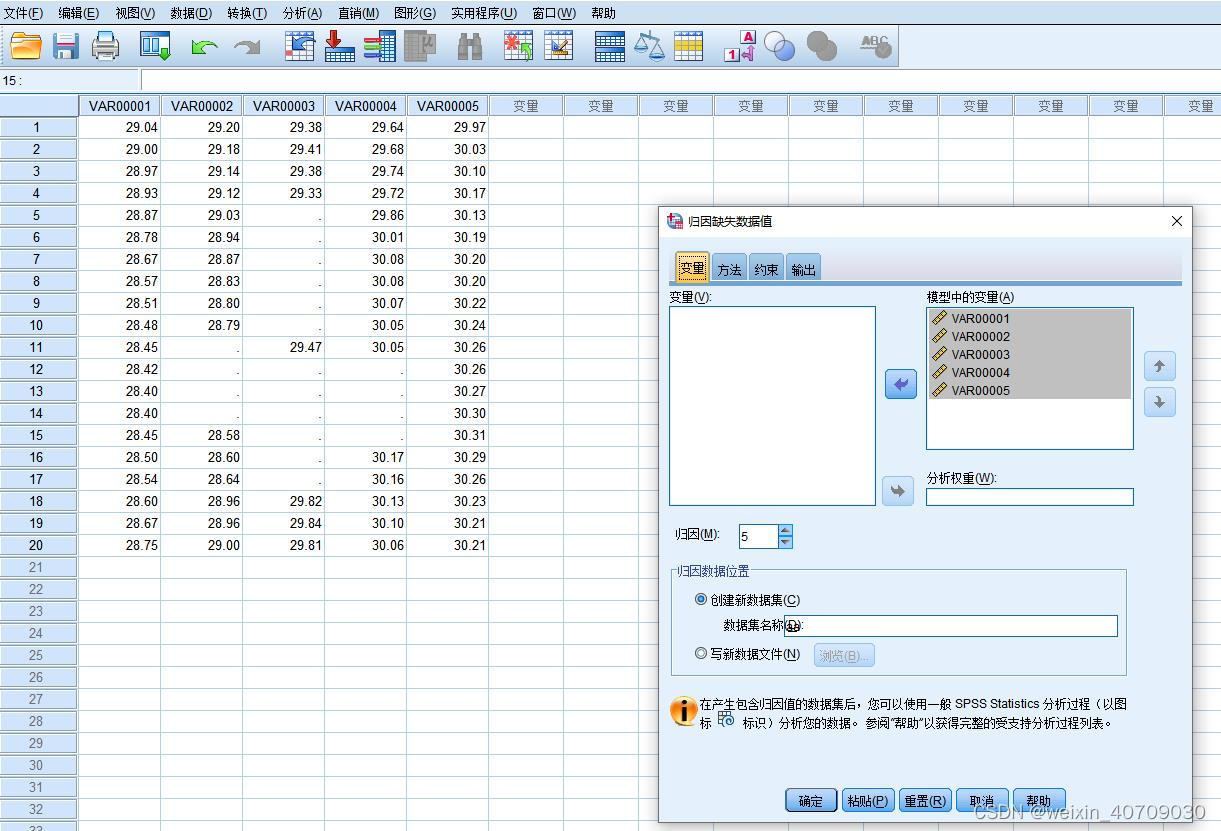
“归因”这里默认5,表示选择5种填充方法,也可以根据需求选1,2,3,4种方法
以下就是填充结果:
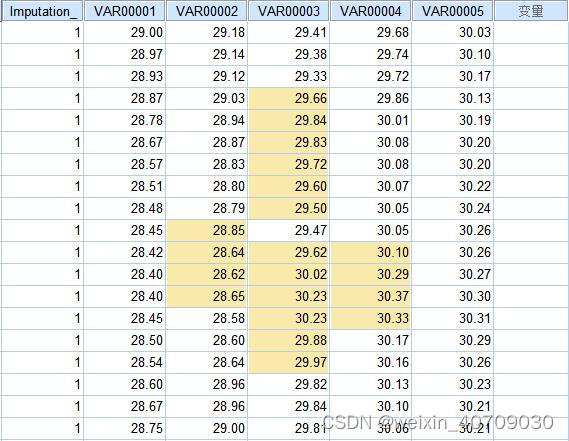
数据问题处理完成后,接下来就该分析和筛选特征了,重点讲一下特征构造思路和特征选择
4.特征分析
4.1特征构造
特征构造方法其实主要还是依据数据集而定。首先还是讲一下时间序列类型的数据,以前面提到的交通流数据为例,一般交通流数据看似给了两列特征,实际上可以根据datetime特征挖掘出好多信息。比如,根据年月日等信息可以衍生出季节信息、今天是否工作日,是否节假日,是否周末等等,甚至可以根据小时信息构造出是否高峰期、晚高峰、早高峰等特征。为什么要构造这些特征,因为前面也有说到交通流的分布是具有周期性的,或以季节为周期或以月份为周期或以小时为周期,构造这些特征可以为我们带来有效信息,便于模型学习到更多更准确的规律。
还有一种比较简单的思路就是某个与目标变量相关度较高的特征的统计值、线性和非线性变换等,比如某个或多个特征的均值、方差、标准差等,再比如变量的对数变换,平方变换、两个变量的加减法或乘法等。但是构造出来的新特征也存在这种情况:不含有效信息,对模型没有帮助,并且很有可能成为冗余特征。因此,在构造新特征时应根据自己数据集的实际情况分析,或者为了保证新构造的特征的有效性,可以进一步通过特征相关性分析方法确定。
4.2特征选择
特征选择有很多种思路,包括但不限于:删除无关重要的特征,删除含有大量缺失值的特征,删除低方差特征,卡方检验,特征相关系数分析法(比如计算两个特征之间的皮尔逊相关系数),主成分分析法,基于机器学习模型的特征重要性分析方法等。
首先讲一下相关性系数分析法,在python中绘制特征热力图,查看特征与特征、特征与目标变量之间的相关性关系,如下:
data_path = ''
train = pd.read_csv(data_path + 'D:/frication/hw75.csv', encoding='gb2312')
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
corrmat = train.corr()
f,ax = plt.subplots(figsize=(15,12))
ax.set_xticklabels(corrmat,rotation='horizontal')
#可以设置热力图的色系,字体,字体颜色,字体大小等
sns.heatmap(corrmat,square=True,annot=True,annot_kws={'size':10, 'family' : 'Times New Roman'},vmax=1,vmin = 0,xticklabels= True, yticklabels= True,linewidths=1,linecolor= 'white', cmap="YlGnBu")
plt.tick_params(labelsize=15)
labels = ax.get_xticklabels() + ax.get_yticklabels()
[label.set_fontname('Times New Roman') for label in labels]
#设置图例,设置图例的字体及大小
label_y = ax.get_yticklabels()
plt.setp(label_y , rotation = 360)
label_x = ax.get_xticklabels()
plt.setp(label_x , rotation = 90)
plt.show()
颜色越深说明变量相关度越高。但是该方法仅反映了特征之间的线性相关性,假如不清楚变量之间的关系,或者变量之间可能存在非线性关系,该方法就不适用了。下面介绍一种基于机器学习树模型的特征重要性分析方法,比如随机森林,XGBoost,LightGBM等都可以用来做特征选择。
#XGBoost特征选择
xgb = XGBRegressor(n_estimators=100)
xgb.fit(X_train, y_train)
# 绘制重要性曲线,max_num_feature参数设置输出前n个重要的特征
plot_importance(xgb,max_num_features=30)
plt.show()
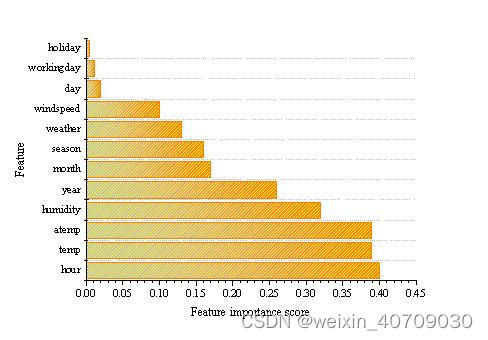
有些变量之间存在较高的相关性,可以去除掉冗余特征以降低模型复杂度。假如变量a与变量b高度相关(可根据特征热力图判断),而变量a的特征重要性较高(可根据基于机器学习模型的特征重要性分析方法判断),可以删除变量b保留变量a。
嗯,分享先到此结束,希望对沉迷于数据分析的小伙伴有所帮助!!!
以上仅为科研工作中的一些个人理解,也许存在不完善之处,欢迎指导与交流。

















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









