






PyTorch深度学习框架60天进阶学习计划 - 第45天:神经架构搜索(一)
第一部分:详解DARTS的可微分搜索空间
大家好!欢迎来到我们PyTorch深度学习框架进阶学习计划的第45天。今天我们将深入探讨神经架构搜索(Neural Architecture Search, NAS)中的一个重要方法——可微分架构搜索(Differentiable Architecture Search, DARTS)。
1. DARTS简介
传统的NAS方法通常依赖于离散搜索空间和基于强化学习或进化算法的搜索策略,计算成本极高。而DARTS通过将离散的架构搜索空间连续化,使整个搜索过程变得可微分,从而大大降低了计算成本。
DARTS的核心思想可以概括为:将架构搜索问题转化为架构参数的优化问题,并与神经网络的权重参数共同优化。这就好比我们不仅关心一个"厨师"(权重)如何烹饪,还关心他使用哪些"烹饪工具"(架构)。
2. DARTS的搜索空间
DARTS的搜索空间由一系列节点和边组成,形成一个有向无环图(DAG)。节点代表特征图,边代表操作。DARTS不是直接选择一个确定的操作,而是将每条边上的每个候选操作赋予一个权重参数,通过softmax函数计算操作的概率分布。
下面是DARTS搜索空间中常见的候选操作:
| 操作类型 | 描述 | PyTorch实现 |
|---|---|---|
| 3x3 可分离卷积 | 深度可分离卷积,节省参数 | nn.Sequential(nn.ReLU(), nn.Conv2d(...), nn.BatchNorm2d(...)) |
| 5x5 可分离卷积 | 更大感受野的深度可分离卷积 | 同上,但kernel_size=5 |
| 3x3 深度可分离卷积 | 先空间卷积再点卷积 | nn.Sequential(nn.ReLU(), SepConv(C, C, 3, stride, 1)) |
| 5x5 深度可分离卷积 | 更大感受野 | 同上,但kernel_size=5 |
| 3x3 平均池化 | 降采样并保留信息 | nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False) |
| 3x3 最大池化 | 提取显著特征 | nn.MaxPool2d(3, stride=stride, padding=1) |
| 恒等映射 | 直接连接 | Identity() |
| 零操作 | 无连接 | Zero(stride) |
3. DARTS的数学原理
在DARTS中,每条边(i,j)上的混合操作可表示为:
o ˉ ( i , j ) ( x ) = ∑ o ∈ O exp ( α o ( i , j ) ) ∑ o ′ ∈ O exp ( α o ′ ( i , j ) ) o ( x ) \bar{o}^{(i,j)}(x) = \sum_{o \in \mathcal{O}} \frac{\exp(\alpha_o^{(i,j)})}{\sum_{o' \in \mathcal{O}} \exp(\alpha_{o'}^{(i,j)})} o(x) oˉ(i,j)(x)=o∈O∑∑o′∈Oexp(αo′(i,j))exp(αo(i,j))o(x)
其中:
- O \mathcal{O} O是所有候选操作的集合
- α o ( i , j ) \alpha_o^{(i,j)} αo(i,j)是操作o在边(i,j)上的架构参数
- 通过softmax函数将架构参数转化为操作权重
DARTS的训练目标是联合优化网络权重参数w和架构参数α:
min
α
L
v
a
l
(
w
∗
(
α
)
,
α
)
\min_{\alpha} \mathcal{L}_{val}(w^*(\alpha), \alpha)
αminLval(w∗(α),α)
s.t.
w
∗
(
α
)
=
arg
min
w
L
t
r
a
i
n
(
w
,
α
)
\text{s.t. } w^*(\alpha) = \arg\min_{w} \mathcal{L}_{train}(w, \alpha)
s.t. w∗(α)=argwminLtrain(w,α)
4. DARTS的搜索过程代码实现
让我们来实现DARTS的核心组件:可微分操作混合。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义零操作
class Zero(nn.Module):
def __init__(self, stride):
super(Zero, self).__init__()
self.stride = stride
def forward(self, x):
if self.stride == 1:
return x.mul(0.)
# 对于stride>1的情况,需要对输入进行下采样
return x[:, :, ::self.stride, ::self.stride].mul(0.)
# 定义恒等映射
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
# 定义可分离卷积
class SepConv(nn.Module):
def __init__(self, C_in, C_out, kernel_size, stride, padding):
super(SepConv, self).__init__()
self.op = nn.Sequential(
nn.ReLU(inplace=False),
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride,
padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=True),
nn.ReLU(inplace=False),
nn.Conv2d(C_out, C_out, kernel_size=kernel_size, stride=1,
padding=padding, groups=C_out, bias=False),
nn.Conv2d(C_out, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=True),
)
def forward(self, x):
return self.op(x)
# 定义混合操作
class MixedOp(nn.Module):
def __init__(self, C, stride):
super(MixedOp, self).__init__()
self._ops = nn.ModuleList()
# 定义所有候选操作
self._ops.append(SepConv(C, C, 3, stride, 1)) # 3x3 深度可分离卷积
self._ops.append(SepConv(C, C, 5, stride, 2)) # 5x5 深度可分离卷积
self._ops.append(nn.AvgPool2d(3, stride=stride, padding=1, count_include_pad=False)) # 3x3 平均池化
self._ops.append(nn.MaxPool2d(3, stride=stride, padding=1)) # 3x3 最大池化
self._ops.append(Identity() if stride == 1 else nn.AvgPool2d(3, stride=stride, padding=1)) # 恒等映射或下采样
self._ops.append(Zero(stride)) # 零操作
def forward(self, x, weights):
# 计算加权混合操作
return sum(w * op(x) for w, op in zip(weights, self._ops))
# 定义一个简单的DARTS单元
class DARTSCell(nn.Module):
def __init__(self, C_prev, C, num_nodes=4):
super(DARTSCell, self).__init__()
self.num_nodes = num_nodes
# 预处理输入
self.preprocess = nn.Conv2d(C_prev, C, 1, 1, 0, bias=False)
# 初始化混合操作
self.edges = nn.ModuleList()
# 第i个节点连接到前面所有节点的边
for i in range(self.num_nodes + 2): # +2 for input nodes
for j in range(i):
stride = 1 # 在实际应用中,可能会有不同的stride
self.edges.append(MixedOp(C, stride))
# 定义输出节点的连接
self.multiplier = 4
self.final_concat_dim = C * self.multiplier
def forward(self, x, weights):
# 预处理输入
s0 = self.preprocess(x)
# 保存中间节点的状态
states = [s0]
offset = 0
# 对每个节点进行计算
for i in range(self.num_nodes):
# 对每个前驱节点计算加权和
s = sum(self.edges[offset + j](h, weights[offset + j])
for j, h in enumerate(states))
offset += len(states)
states.append(s)
# 连接中间节点作为输出
return torch.cat(states[-self.multiplier:], dim=1)
5. DARTS训练过程
DARTS的训练过程分为两个阶段:
- 架构搜索阶段:联合优化架构参数α和权重参数w
- 架构评估阶段:使用搜索得到的最佳架构从头训练模型
下面是架构搜索阶段的简化代码:
def train_darts(model, train_queue, valid_queue, criterion, architect, optimizer, lr, epochs):
"""DARTS训练过程"""
for epoch in range(epochs):
# 训练
model.train()
for step, (x, target) in enumerate(train_queue):
# 更新架构参数
x_valid, target_valid = next(iter(valid_queue))
architect.step(x, target, x_valid, target_valid, lr, optimizer)
# 更新权重参数
optimizer.zero_grad()
logits = model(x)
loss = criterion(logits, target)
loss.backward()
optimizer.step()
# 验证
valid_acc = validate(model, valid_queue, criterion)
print(f'Epoch {epoch}: validation accuracy = {valid_acc:.2f}%')
6. DARTS架构搜索流程图
下面是DARTS架构搜索的流程图:
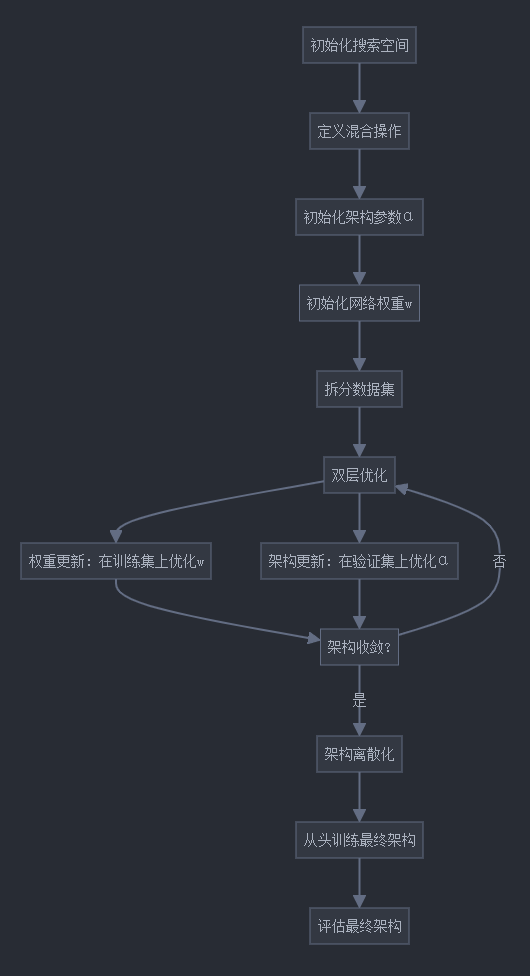
7. DARTS权重共享策略
DARTS的一个关键创新是权重共享策略。在传统NAS方法中,每个评估的架构都需要从头训练,计算资源消耗巨大。而DARTS通过在搜索过程中共享权重参数,大大提高了计算效率。
权重共享可以理解为:不同的架构使用相同的权重子集。这就像一个巨大的"超网络"(supernet),其中包含所有可能的架构,而每个特定架构只是这个超网络的一个子网络。
权重共享的优势:
- 减少训练时间:无需为每个架构从头训练
- 提高参数利用率:同一参数可用于多个架构
- 增强泛化能力:共享参数的架构在不同数据上表现更稳定
下面是一个简单的表格,对比了有无权重共享的NAS方法:
| 方法 | 计算资源需求 | 搜索时间(GPU天) | 优点 | 缺点 |
|---|---|---|---|---|
| 无权重共享NAS | 极高 | 1000+ | 架构评估准确 | 计算成本极高 |
| 权重共享DARTS | 中等 | 1-4 | 计算高效 | 可能存在架构坍塌问题 |
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









