






更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
随着 LLM 技术的发展,向量检索与向量数据库也受到业界持续关注,它们能够为LLM提供外置记忆单元,通过提供与问题及历史答案相关联的内容,协助LLM返回更准确的答案。不仅LLM,向量检索在OLAP引擎中也早已得到应用,旨在提升非结构化数据的分析和检索能力。
作为火山引擎旗下的OLAP引擎,ByteHouse推出了高性能向量检索能力。本篇聚焦ByteHouse对高性能向量检索能力的建设思路,并以“以图搜图”为例,详解OLAP的向量检索能力如何在具体场景中落地。
ByteHouse向量检索能力
向量检索,目标是查找与给定向量最相似的k个结果,目前广泛应用于以图搜图、推荐系统等场景。在实际使用场景中,向量检索针对的数据集大小通常会在 million 甚至 billion 级别,而查询延迟通常会要求在数毫秒到百毫秒内返回,通常会使用具有特殊结构的向量检索索引方式。
- 既有局限分析
目前比较流行的向量索引算法有 HNSW、Faiss IVF 等,这类基于向量索引的向量检索负载,通常具有构建时间长、资源消耗大等特点,且需要考虑如何高效管理索引构建任务所需资源;如何支持内存计算;如何与过滤语句结合以及资源消耗等一系列问题。
ByteHouse源自ClickHouse,但后者存在向量索引重复读取,相似度计算冗余等问题,对于延迟要求低、并发需求高的向量检索场景可用性较弱。
- 优化整体架构
基于上述分析,ByteHouse在向量检索能力上进行了全面创新,团队基于 vector-centric 的思路,重新构建了高效的向量检索执行链路,结合索引缓存、存储层过滤等机制,使ByteHouse性能实现进一步突破。
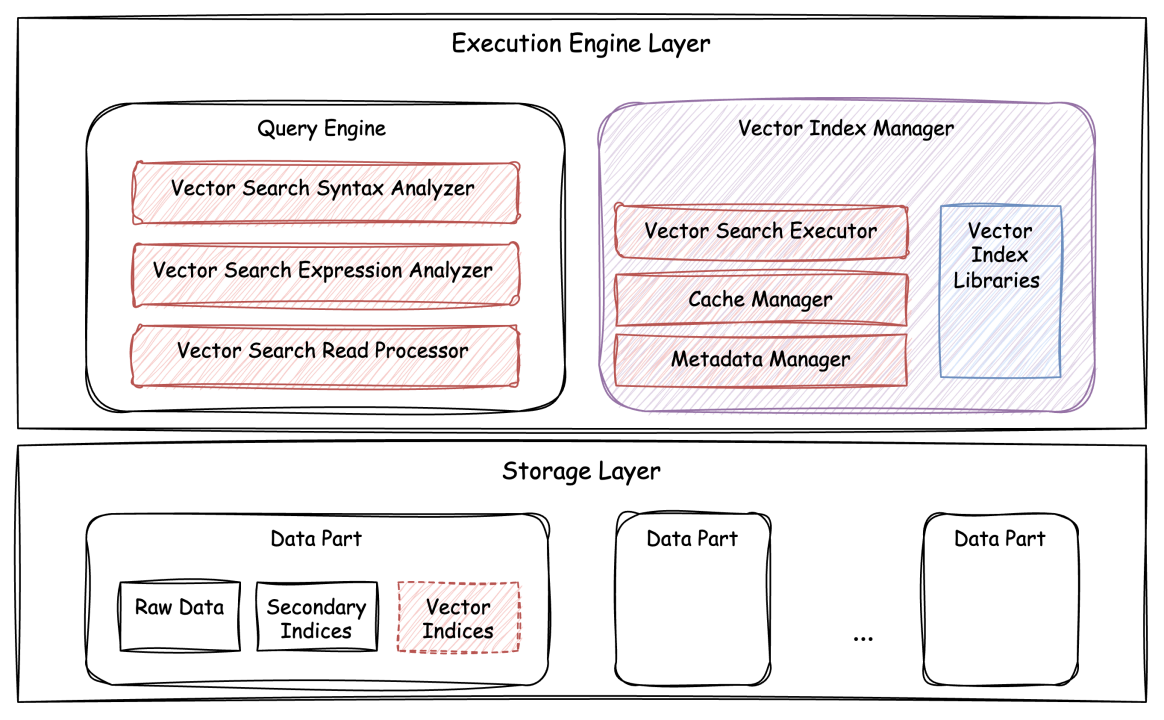
ByteHouse向量检索功能整体架构
下文将具体以“以图搜图”这一典型的向量搜索应用场景为例,详细解读ByteHouse如何实现高性能检索能力的落地与优化。
向量检索能力落地以图搜图场景
在舆情监测领域,某头部公司将ByteHouse向量检索能力应用在“以图搜图”场景中。
为了更好提供舆情监测服务,该公司在全网不断扩大监测范围,整体数据规模达到12亿,期望在 64 核、256GB内存的资源下,达到秒级以下的搜索速度。
对比行业其他产品单query latency在几秒或十秒级别的情况,ByteHouse在优化前可达到700-800 毫秒,经过一系列优化后,最终可在约 150-200 毫秒的时间内,能够从大规模数据中查找出近似的 1000 张图片及其相似度评分。
那么,ByteHouse是如何实现上述性能的?具体而言,ByteHouse主要在向量检索计算下推、过滤操作优化、数据冷读问题优化几个方面采取了优化措施。此外,由于资源有限,还进行了索引构建资源限制。
优化一:计算下推优化
在典型的OLAP场景中,数据进入后,会生成多个Data Part,按批聚合。按照算子执行,对每个Part进行 Vector Search 和 Attributes Read,然后对每个Part做TopK。这在投影列较多的情况下,产生很大的资源消耗。
对此,ByteHouse团队进行了如下优化。
- 首先,对每个 Part 进行 Vector Search,相当于将一个算子拆分成三个算子,先做Vector Search。
- 然后,对 Vector Search 的结果进行全局排序,此时不读取标量信息列。
- 最后,在全局排序的结果上,执行Read Task,得到最终结果。
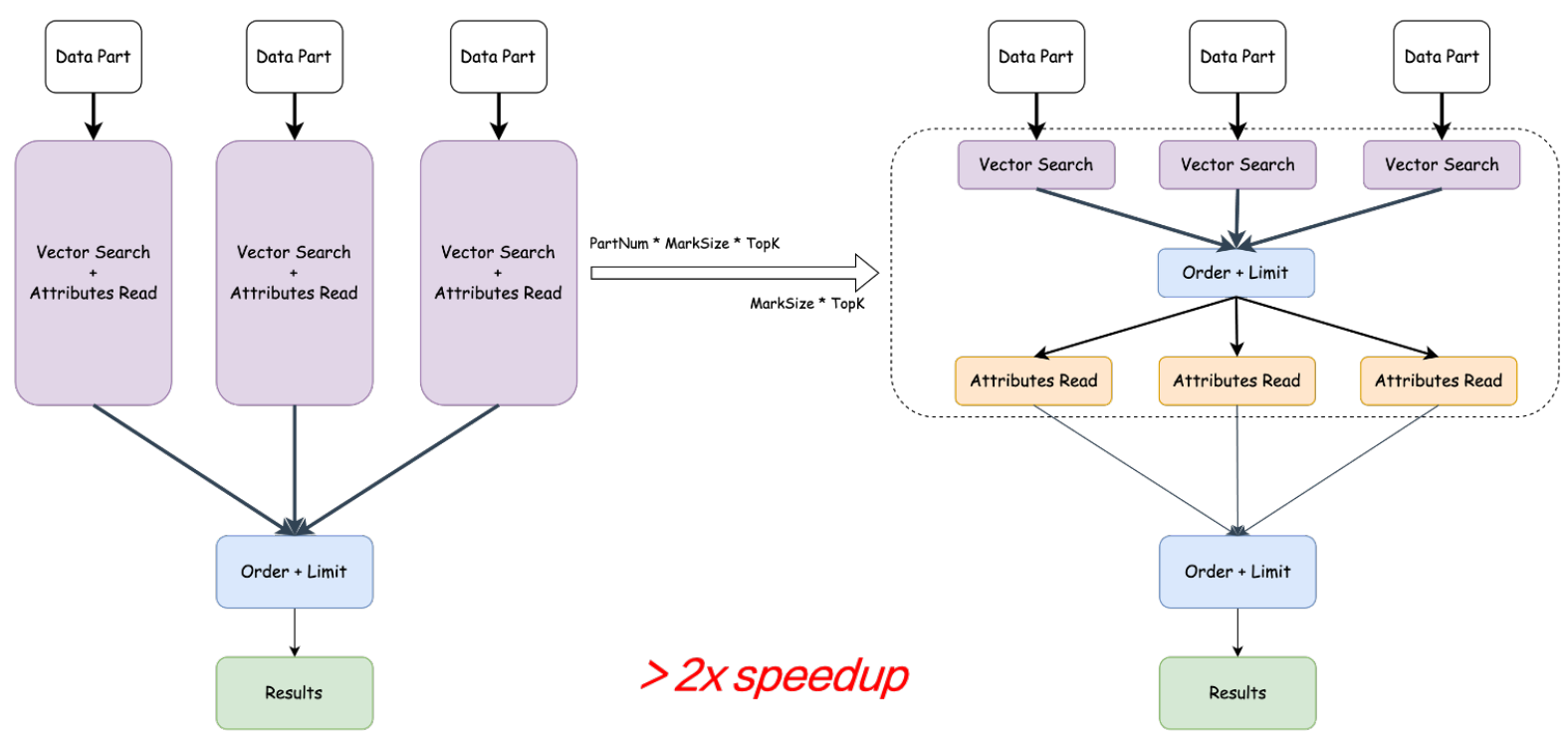
计算下推优化
通常而言,数据是分批写入的,每一批都会有一个Part,Part一般大于 100。那么,在优化后的实际场景测试中,延迟基本可以做到两倍以上的速度提升。
优化二:过滤操作优化
在优化标量与向量混合查询场景上,主要围绕以下三点进行优化。
- 基于标量主键范围查找
标量其实是一个排序键,类似于 MySQL 中的主键。通常,在进行搜索时,会先进行标量过滤,从而获取符合查询条件的数据。如果按一般方法计算,就会有很大的消耗。
由于标量本身是有序的,所以可简单理解为:只需读取首尾部分数据,进行过滤,构建符合条件的row id bitmap。比如在计算timestamp大于某个值的情况时,只需计算开始和结束位置所对应的行,因为中间结果都是符合的。
- 加速标量列剪枝
数据剪枝,主要是根据实际情况对物理上的键排列分区,包括对主键和辅助索引的分区,以此来加速查询。
- 存储层过滤
在存储层面进行优化,将过滤条件下推到存储中,尽量减少 IO 操作。对类似OLAP和OLTP的数据库而言,查询动作的底层会有很高的计算开销。因此ByteHouse针对典型场景,会在底层进行更多过滤,以此减少 CPU 和内存资源的使用。此外,对于热数据行做了Cache加速。
优化三:向量数据冷读问题优化
- 使用索引需要index结构全载入内存
向量索引方面,ByteHouse接入了 hnswlib、faiss 两个比较流行的检索算法库,支持HNSW、IVF_PQ、IVF_PQ_FS等多种常用索引。此外,考虑到向量检索需要在内存中执行,还加入了向量索引缓存机制,确保查询涉及的Data Part的索引能够常驻内存,以实现低延迟的向量检索。
在向量检索需要较高QPS的情况下,冷读可能就会成为性能瓶颈。当前支持的向量索引需要加载到内存中以后,才能进行高性能的向量检索计算,该层面的优化方法主要是将不同资源index结构载入内存。
- Cache Preload & Auto GC
在构建到内存的过程中,可能存在一些问题,例如:数据库重启,或导入新数据时,这些数据仍然是冷的。在OLAP存储时,使用的是 LSM 存储格式,进行数据Merge和自动 GC 流程。在数据库运行过程中的服务启动、数据写入等场景中,ByteHouse 可以自动将新的索引加载到内存中,并确保Cache中的过期数据能够自动回收。
优化四:索引构建资源限制
- 向量数据库workload特征
向量检索方面存在普遍关心的资源问题,使用向量检索会消耗较多的 CPU 和内存资源。为了避免资源开销过大,ByteHouse团队在资源使用层面进行了限制。
- 并发限制
在资源不足的情况下,限制 index 构建的线程级别以及后台的merge任务。不过,对资源进行限制,也会在保证资源使用的同时解决导致检索速度变慢的问题。
- 内存优化
为了减少资源使用开销,ByteHouse团队主要采取了以下措施。
- 使用 PQ、SQ 压缩,将向量的存储空间降低到原来的 1/4 或 1/3。例如,在精度要求不太高的情况下,将 float32 类型的数据压缩为 INT8 类型,从而将 4 字节的数据压缩为 1 字节,减少存储空间。
- 在训练过程中,需要支持增量训练。对于IVF系列,在构建索引时,不需要常驻内存,可以将其落盘。
优化后,ByteHouse在资源使用上取得了显著效果,在类似前述“以图搜图”的场景中,以很少的资源就能支撑大规模数据。
不仅仅向量检索引擎,ByteHouse具备全场景引擎能力
目前,ByteHouse已通过Vector引擎支持多种向量检索算法以及高效的执行链路,并且能够支撑大规模向量检索场景,达到毫秒级的查询延迟。
在“一元化数据、多元化引擎”的理念下,ByteHouse 致力于实现全场景引擎覆盖,以确保实现整体数据效能的最大化产出。除了支持向量检索能力的Vector引擎,ByteHouse还具有全文检索引擎、GIS引擎在内的全场景引擎,为用户提供一体化数据分析服务。
作为一款以提供高性能、极致分析能力的云数仓产品,早在2022年2月,ByteHouse在字节跳动的部署规模就已超1万8000台,单集群超2400台。未来,它还将持续为企业数据分析能力提供支持,助推数智化转型升级。
点击跳转 火山引擎ByteHouse 了解更多
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









