






一、背景
部门中一核心应用,因为各种原因其依赖的 MySQL 数据库一直处于高水位运行,无论是硬件资源,还是磁盘使用率或者 QPS 等都处于较高水位,急需在大促前完成对应的治理,降低各项指标,以保障在大促期间平稳运行,以期更好的支撑前端业务。
二、基本情况
2.1、数据库
目前该数据库是一主两从,且都是零售的物理机,运行多年已都是过保机器。同时因为 CPU 和磁盘较大,已无同规格的物理机可以增加一个从库。同时其中一个从库的内存减半且磁盘还是机械盘,出故障风险极高且 IO 性能低导致查询偏慢,出现过多次因性能问题切到另一个从库的情况。
以下是其 3 台机器的硬件资源信息,MySQL 版本、部署机房和硬件配置情况。其中 135 机器硬盘容量 128T 是统计显示有误,可以认为也是 16T。因为磁盘做了 RAID0,因此实际容量在 7T 左右。

2.2、磁盘空间
截止到 2 月底,各数据库磁盘空间占用情况如下:

从上表咱们可以看出,各数据库的磁盘空间占用已处于较高水位,急需需要治理,通过结转或删除数据来降低磁盘占用比例。
2.3、表空间
数据库存在大表其中一个原因是多条业务线共用一个应用,同时代码层面抽象的部分不够抽象,扩展部分又不容易扩展,导致数据都糅合和一起。
以下是所有的表空间占用情况,可以明显看到大部分的表数据量都在千万行以上,特别是前 7 张表的表空间占用都在 100 个 G 以上,数据行数也都在亿级以上,最多的是 status 表,30 亿行数据,典型的大库大表。
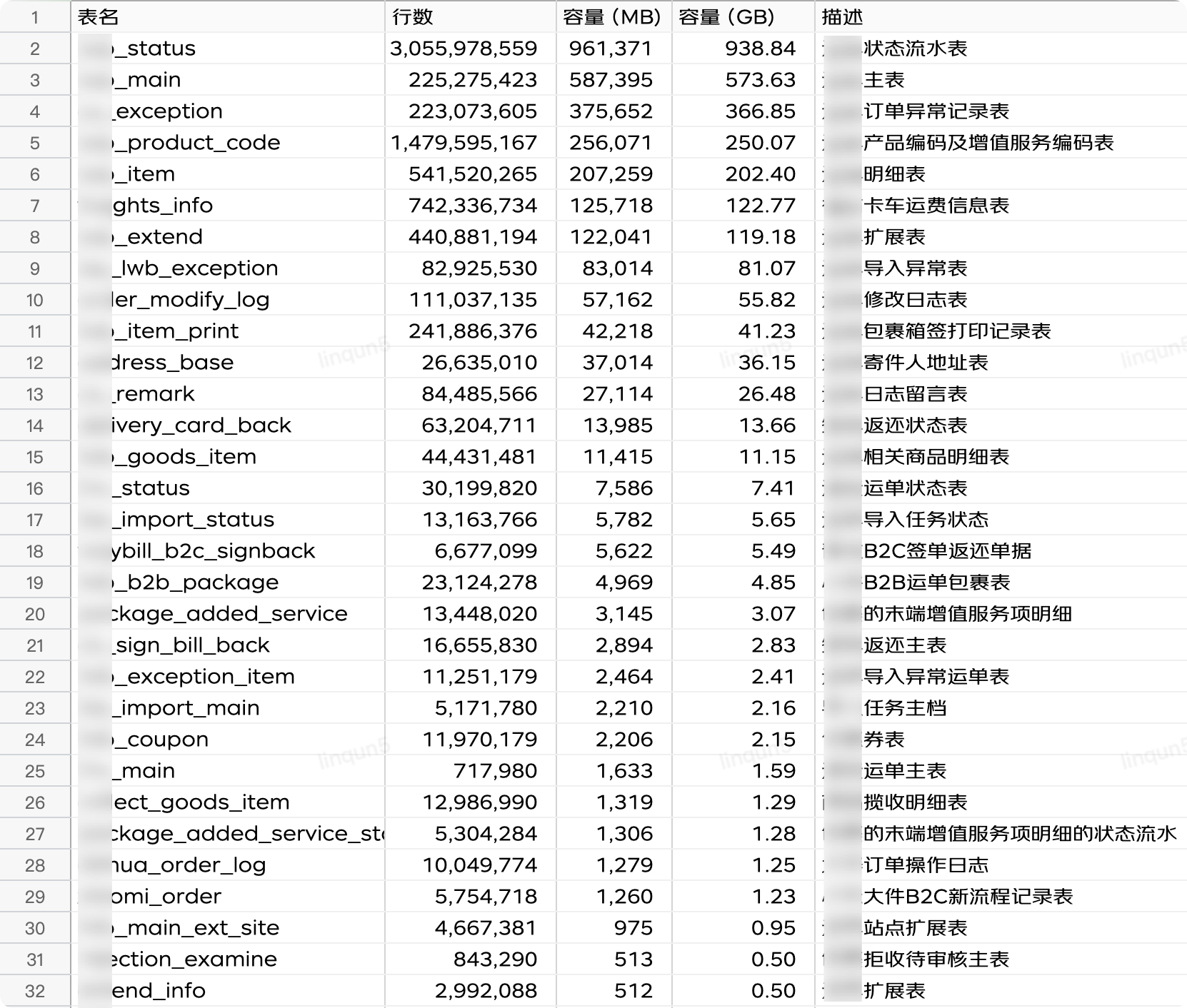
2.4、QPS 情况
黄色的为主库的 QPS,可以看出主库的查询量远大于从库,由于各种原因,应用代码里只有少部分的查询是走的从库,急需将部分流量大的查询接口从主库切到从库去查询;
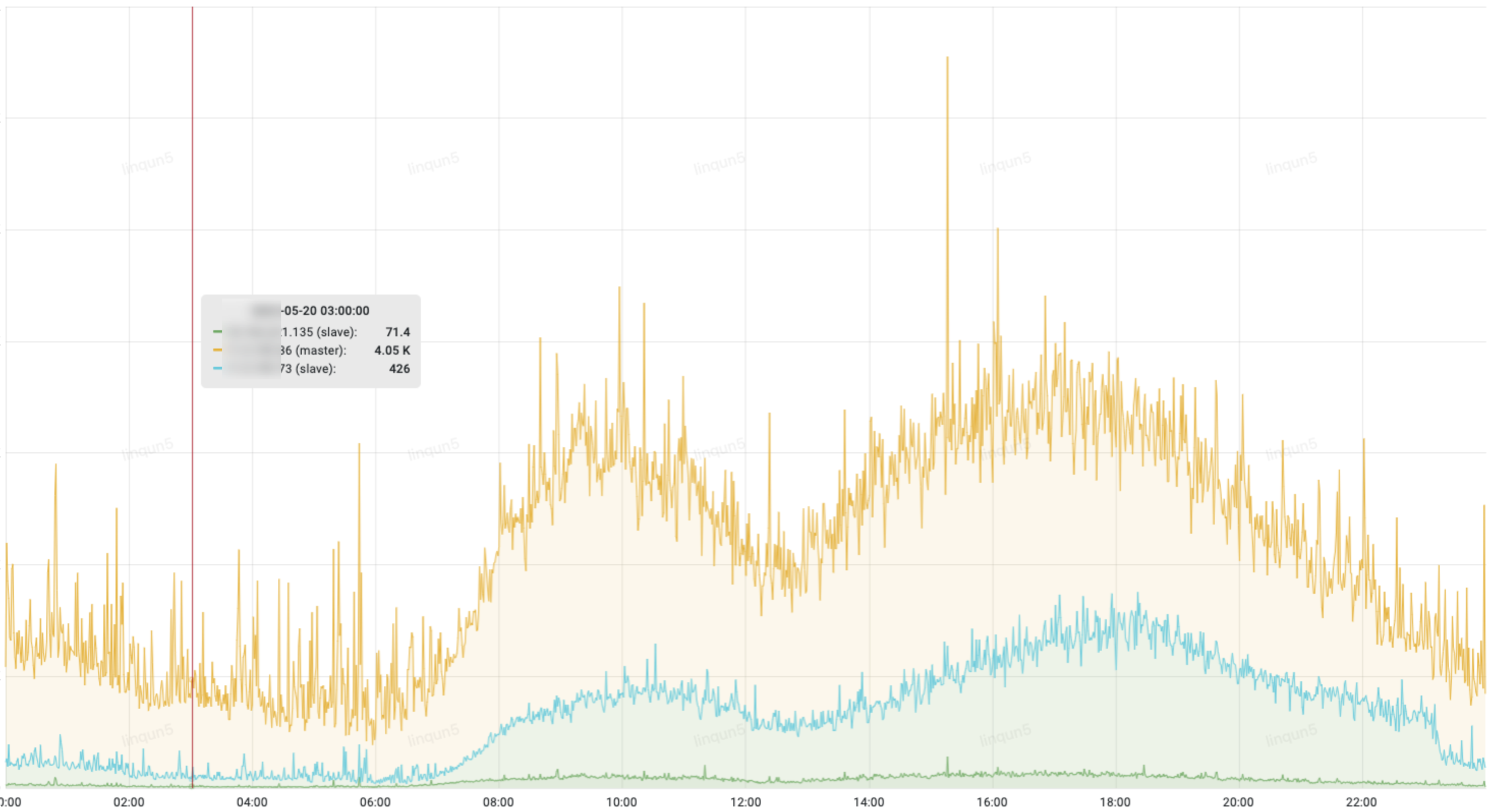
2.5、慢 SQL
不论是主库还是从库,都有偶发的慢 SQL 查询,引发磁盘繁忙,影响系统稳定性。
三、治理目标
1.数据结转,降低磁盘使用率,处较低水位运行。
治理目标:将表空间占用大于 100G 的 7 张表(xxx_status、xxx_main、xxx_exception、xxx_product_code、xxx_item、freights_info、xxx_extend)先进行集中结转,保留一年数据后进行常态化结转,按天结转,将数据量保持在 365 天;
1.降低主库 QPS,保障主库安全。
治理目标:将主库的高频查询切换到从库查询,使主库白天 QPS 降低 30%,近一个月上午峰值平均在 20k,下午峰值平均在 25k;治理的目标为:上午峰值 15k,下午峰值 18k;
1.慢 SQL 治理,避免导致磁盘繁忙而影响整体业务。
治理目标:10s 以上的彻底消除;5s 以上的,消除 80%;1s 以上的消除 60%;底数是过去一个月(1s 以上慢 sql);
四、治理方案
4.1、大表数据结转
根据这 7 张表的业务属性不同,结转的类型也不相同;比如对于历史数据无意义的,可以将历史数据直接删除,比如 xxx_exception;另外一类是纯历史数据,比如流水数据 xxx_status 表,结转方式是同步大数据平台后就可以删除;最后是业务主数据,是需要同步大数据平台和需要结转至历史库的,比如 main、item 和 extend 表等;
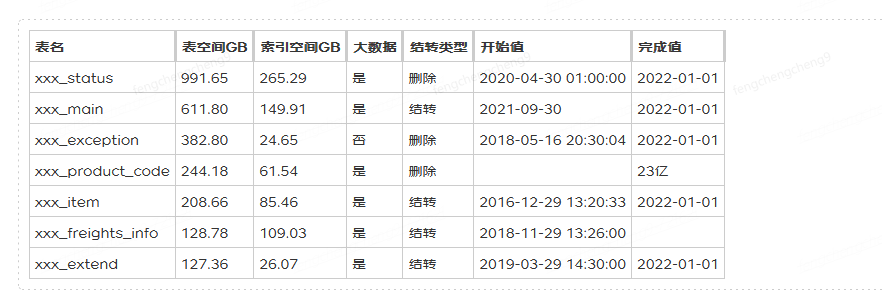
以下的统计表格是在同步大数据平台后集中删除和结转的空间释放情况,在 1 个月内对数据量在 1 亿以上并且占用空间在 100G 以上的 7 张大表进行了删除和结转后删除,使数据在保留 365 天的业务承诺时间范围内,降低了 470G(10%)的磁盘空间占用;
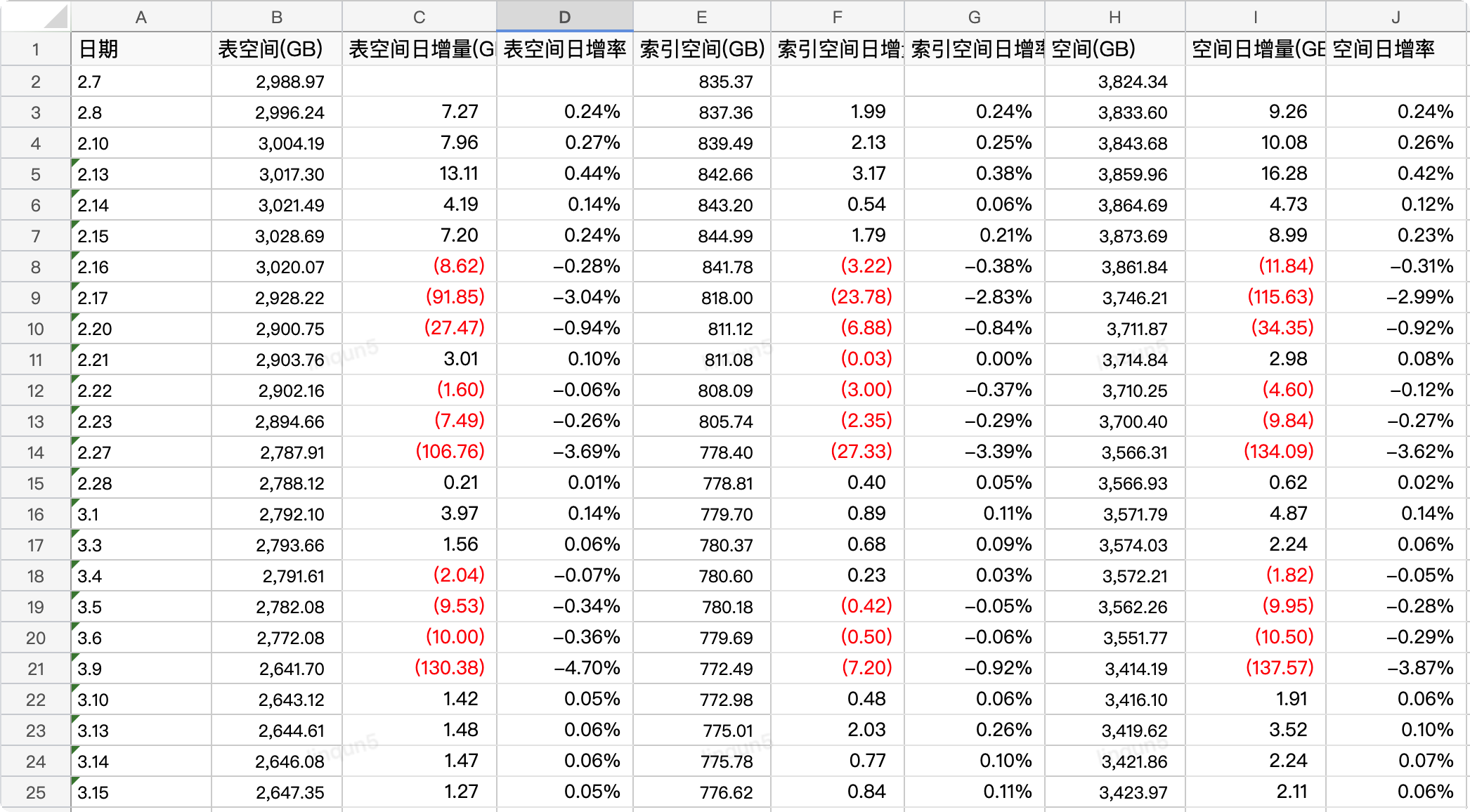
PS:红色数字部分为负值,也就是磁盘的释放空间。
4.2、拦截无参数查询
运单主档查询偶发会有无任何参数的查询,引发严重慢 SQL,造成数据库磁盘繁忙度严重飚高,极大地影响了其他业务操作,而由于入口众多和交叉调用,如果在入口做参数校验工作量及风险都比较大,所以采用 MyBatis 的插件机制在 dao 层做拦截,直接拒绝掉无参数的查询,上线后就再没有出现过因无参查询而出现慢 SQL 而导致的磁盘繁忙情况;
mybatis-config.xml 里的 plugin 配置:

ParameterInterceptor 关键代码如下:
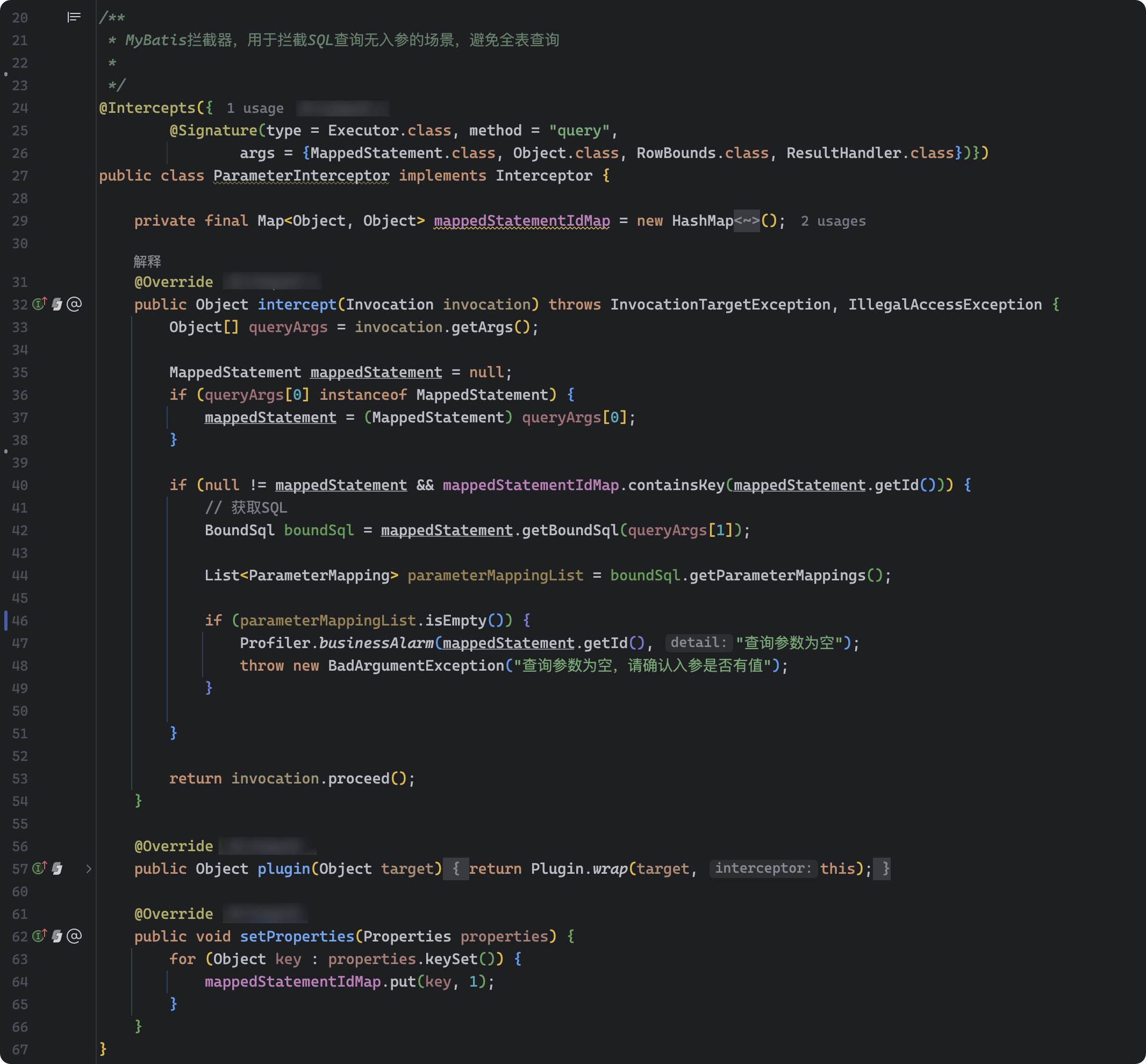
源代码如下:
复制代码
4.3、查询切从库
主库 QPS 高峰期达 30k/s,长期处于高位运行,需要梳理出 TOP10 的查接口来切从库查询,而应用中接口众多,无法逐个接口查各接口的调用量,可以利用 JSF 的 filter 功能结合 UMP 业务监控来统计 provider 的调用次数,再通过 Python 程序获取统计数据生产统计报表。
JSF 的配置文件新增 filter
复制代码
JsfInvokeFilter 的代码:
复制代码
业务监控点列表
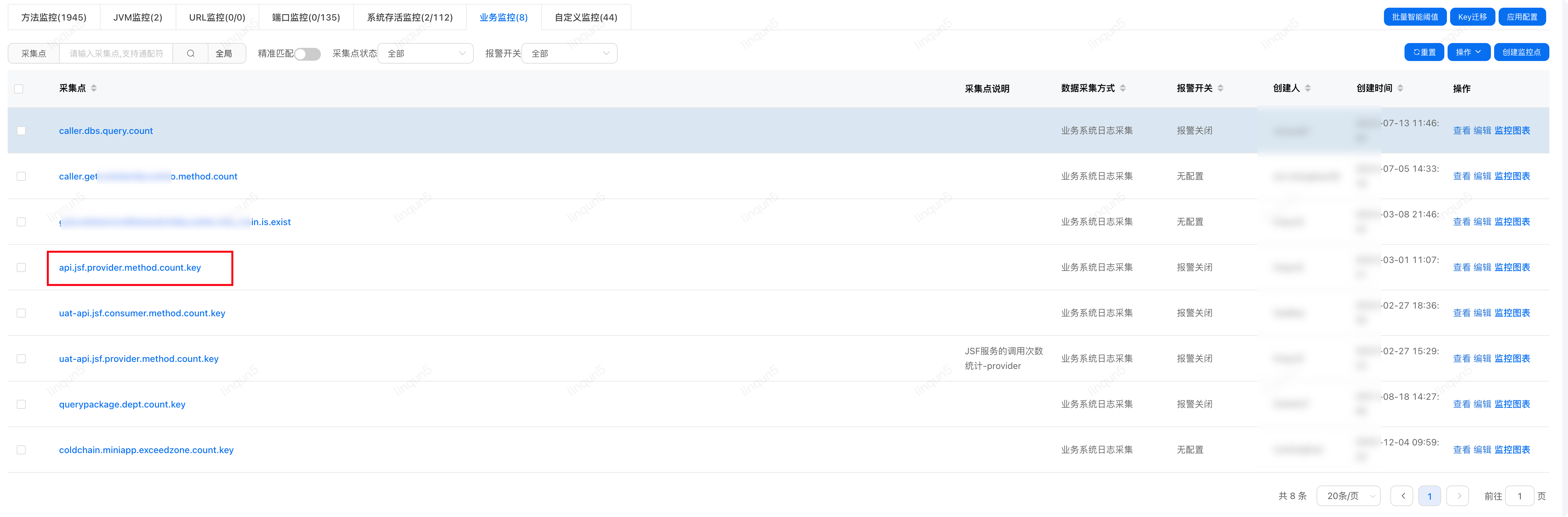
明细项
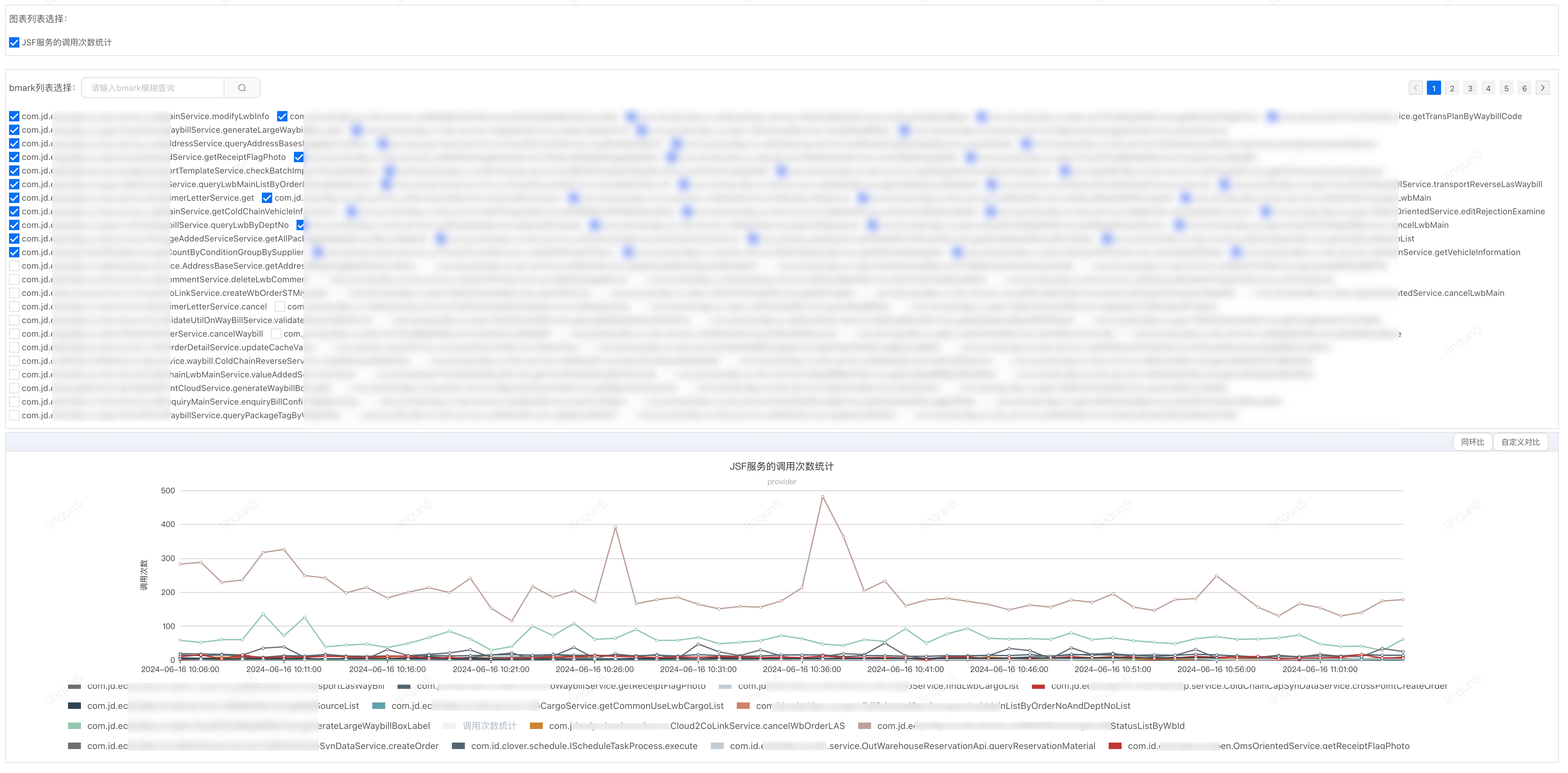
Python 脚本
复制代码
Cookie 的代码如下:
复制代码

分析 Top10 接口的切从库方案:
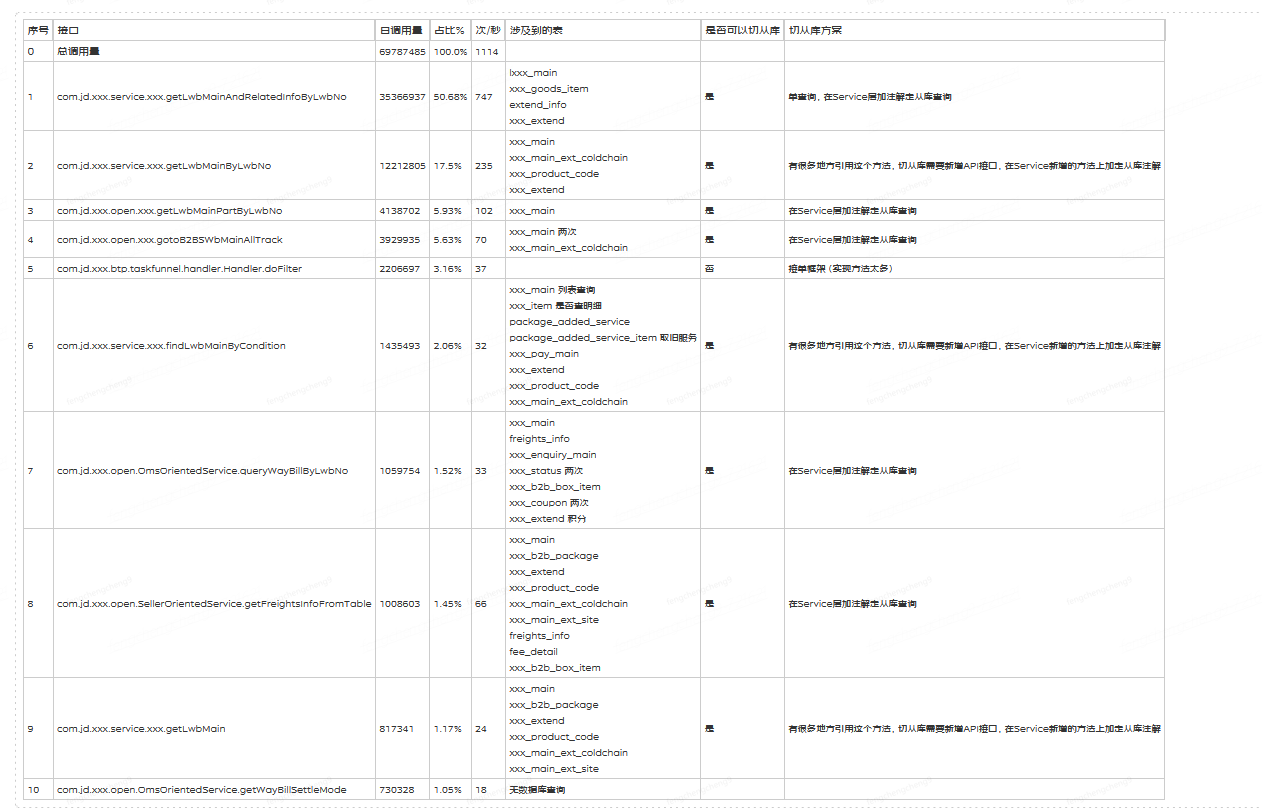
通过优化读操作切换至从库查询,降低了主库 30%的 QPS 流量,白天峰值从 25k 降低到 17.5k;
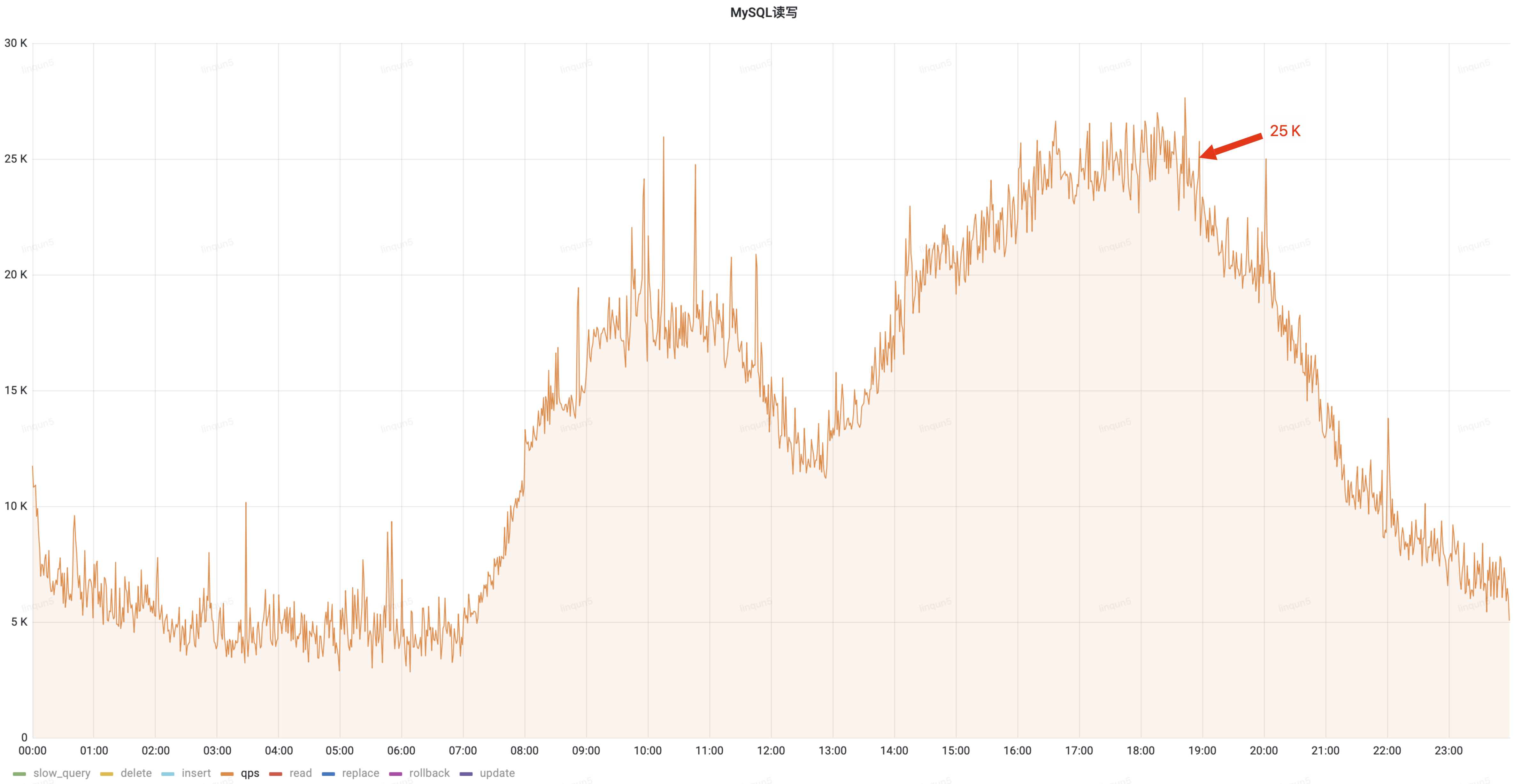
治理前 QPS(峰值 25k)
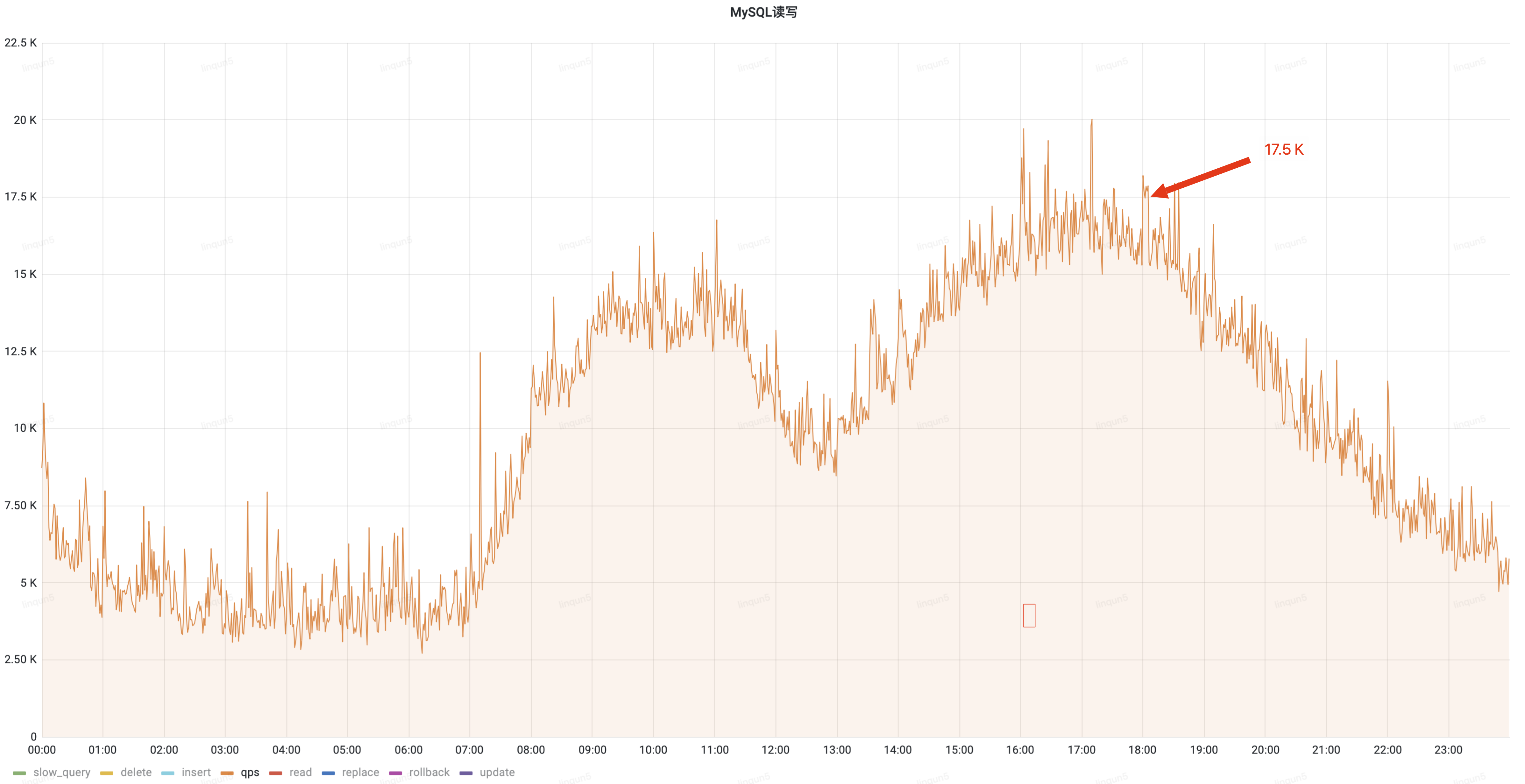
治理后 QPS(峰值 17.5k)
4.4、慢 SQL 治理
通过对慢 SQL 设定有针对性的治理,成功地彻底消除 10s 以上的慢 SQL;5s 以上的,消除 80%;1s 以上的消除 60%。
关于慢 SQL 的治理不过多介绍,采用的都是通用分析和治理方法,有很多的文章都有介绍。需要注意的是在治理过程中要做好灰度,完全验证后再全量上线运行。
五、写在最后
可能有同学会想到分库分表,一个是在规划中提前部署分库分表,一个是现在使用分库分表技术进行治理;关于前一个问题由于时间久远咱们不做过多讨论,关于未使用分库分表进行治理的原因是业务规划的问题,目前此应用业务较为稳定,如采用分库分表治理动作比较大风险较高,ROI 不高,故以上治理方案以稳定为主降低风险为辅。
还有一个治理方案是迁云,利用云计算的弹性及快速恢复等特性降低来运行风险,因为业务的不可中断性,此方案必须是在线迁移,涉及双数据库从双写到双读,再到单读,最后单写,还有数据一致性检查和同步等,成本较高。同时云数据库未能有如此大的磁盘容量和 CPU 核数,所以此方案需要结合分库分表方案同时进行,更增加了成本和风险,但此方案目前是在计划中的,如业务有较大幅度增长,以上治理也已无法满足时,将采用迁云加分库分表,且分库和分表是分期进行推进。
六、探讨
大家在日常及大促中有其他好的治理方案的话,欢迎发在评论区一起探讨。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









