







1、什么是Pgsql数据库?
PostgreSQL是一个功能强大的开源对象关系型数据库系统,他使用和扩展了SQL语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能,是目前功能最强大的开源数据库。
2、公司为什么用pg数据库
1. 开源免费:相比oracle数据库,pg是开源且免费的。
2. 稳定可靠:PostgreSQL是唯一能做到数据零丢失的开源数据库。
3. 支持广泛:PostgreSQL 数据库支持大量的主流开发语言,包括C、C++、Perl、Python、Java、Tcl以及PHP等。
4. mysql数据库比较轻便,适合中小型公司,对于我们公司要存储大量的空间数据,虽然两者都支持空间数据,但是mysql支持的不太全面,专业空间数据库非PostgreSQL莫属,选用pgsql更合适。
3、常用函数
(1)算数运算符
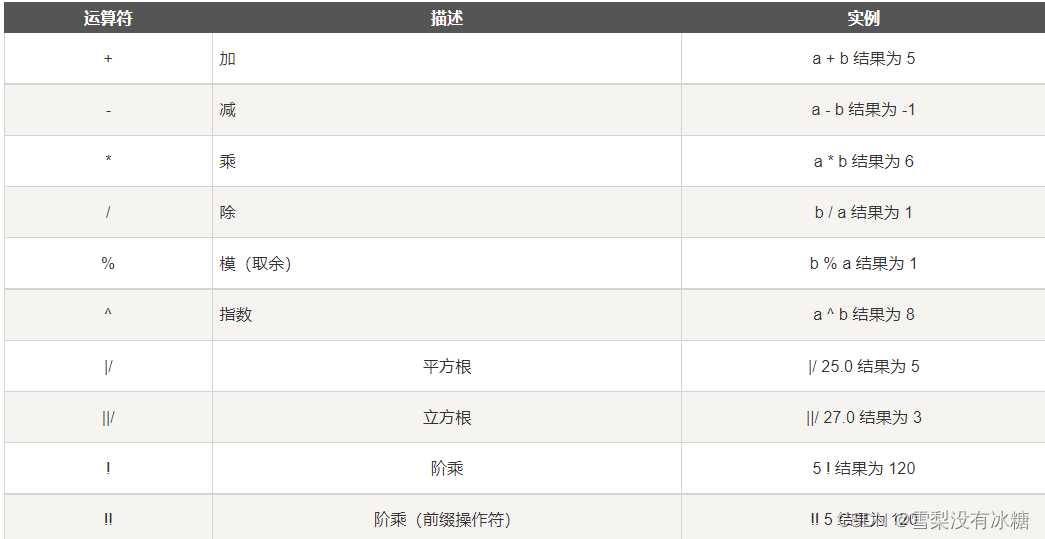
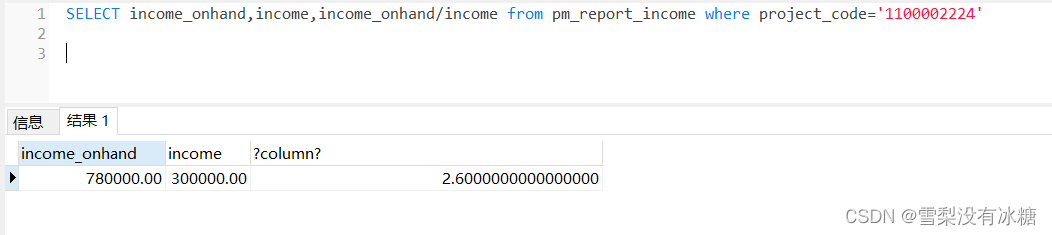
其中 / % 的区别
(2)and 和or 的用法主要是and 和or 的混合使用
①and and or
SELECT * from cm_capital_outflow where subject_class='99'and second_subject='31' or project_busi_line='07'
②and (and or)
SELECT * from cm_capital_outflow where subject_class='99'and (second_subject='31'or project_busi_line='07')
(3)With 的用法
With子句有助于将复杂的查询分解为更简单的语句,便于阅读,也可以当做一个为查询而存在的临时表,WITH 子句在使用前必须先定义.
格式: with 自定义表名1 as(后面跟着sql语句的查询),自定义表名2 as(后面跟着sql语句的查询)
① 多个表合并当做一个临时表
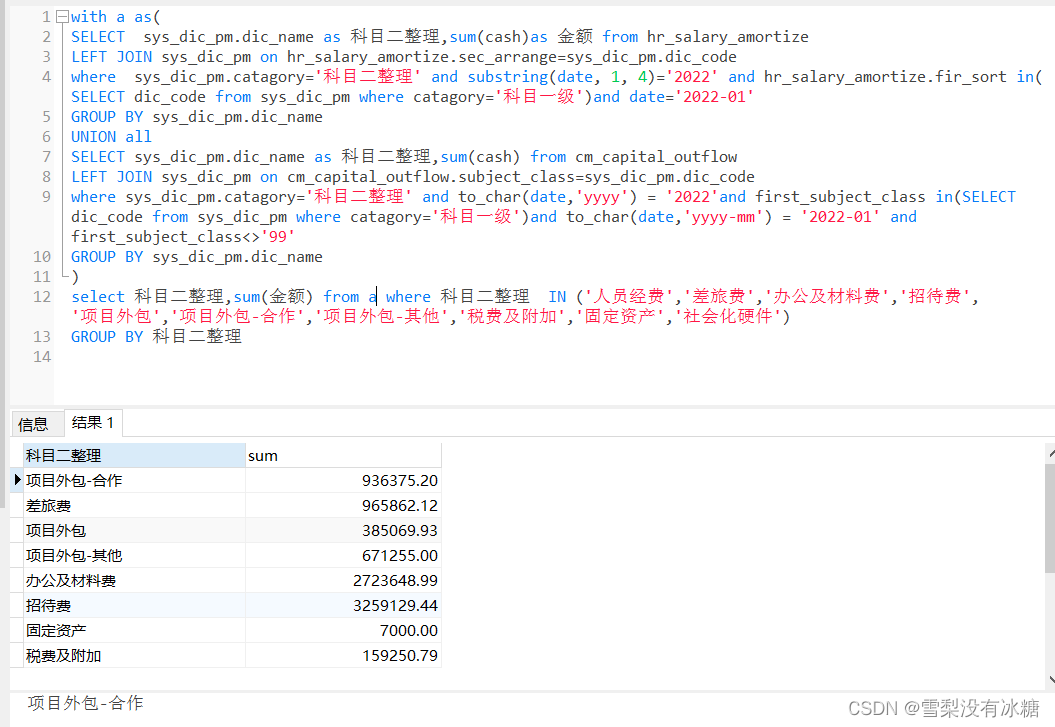
② 多个表中的数值,进行加减乘除等运算。
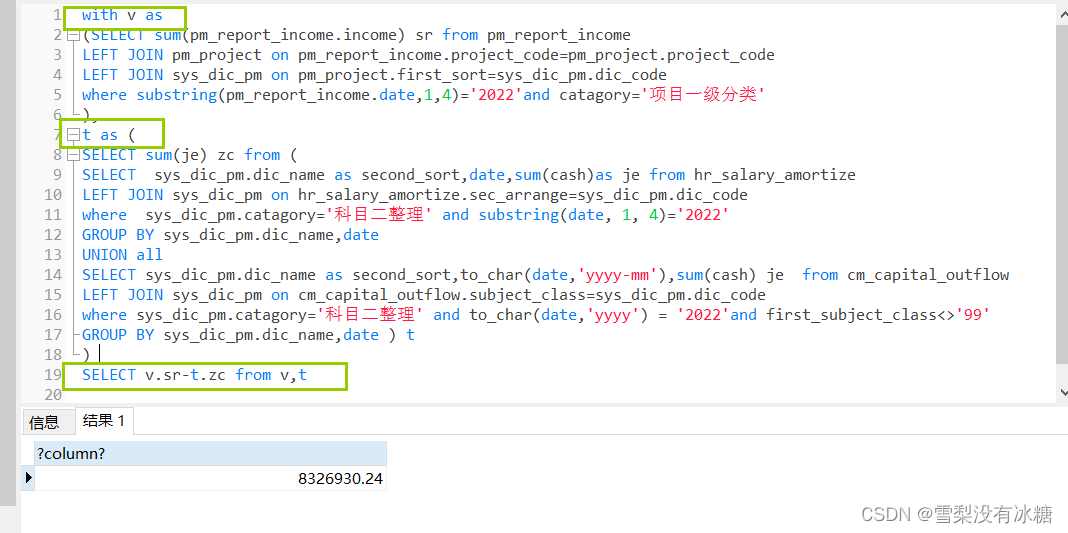
(4)递归查询
在 WITH 子句中可以使用自身输出的数据
1.向上递归
with RECURSIVE hr_dept1 as(
SELECT * from hr_dept where dept_id='489614256'
union
SELECT hr_dept.* from hr_dept,hr_dept1 where hr_dept.dept_id=hr_dept1.parent_id)----递归查询
SELECT dept_id,dept_name,dept_type,parent_id from hr_dept1
ORDER BY dept_type
1 )sql中with hr_dept1 as () 是对一个查询子句做别名,同时数据库会对该子句生成临时表;
2 ) recursive 是一个函数,他会把查询出来的结果再次代入到查询子句中继续查询
3 )最后一句select后跟的字段必须少于等于hr_dept和hr_dept1中字段。
2.向下递归
with RECURSIVE hr_dept1 as(
SELECT * from hr_dept where dept_id='51597175'
union
SELECT hr_dept.* from hr_dept,hr_dept1 where hr_dept.parent_id=hr_dept1.dept_id)
SELECT dept_id,dept_name,dept_type,parent_id from hr_dept1
ORDER BY dept_type
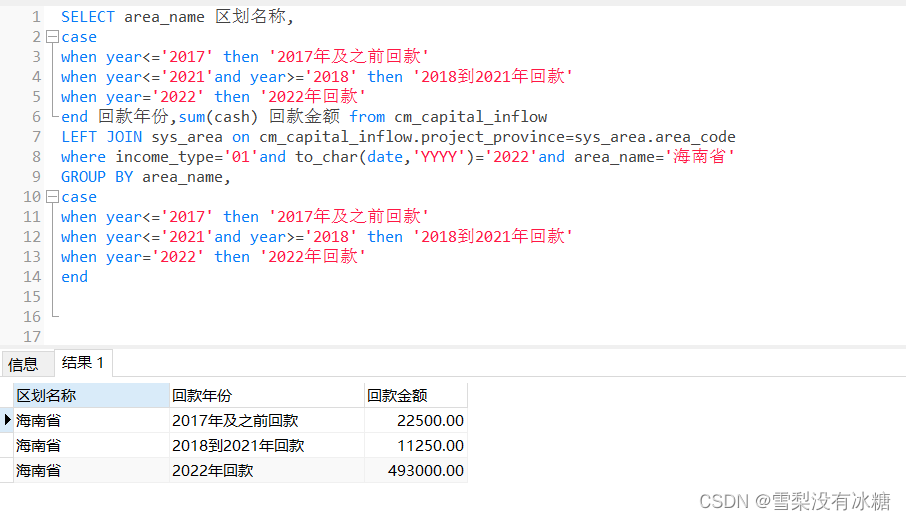
(5)case then的用法
格式:casewhen thenwhen then… end
① 查询多个时间范围,统计每个时间范围的数值
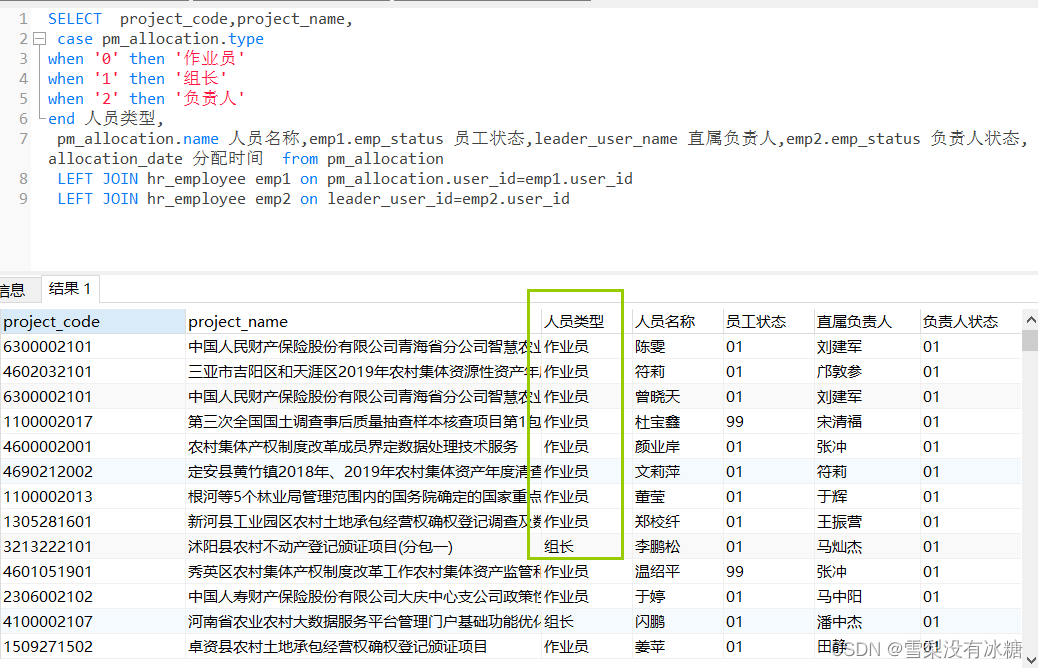
② 给字典项赋值,适用于字典项较少的,小于等于3个字典项的。
(6)HAVING
HAVING 子句配合 GROUP BY 子句,在创建的分组上设置条件
例子:查询一个表中身份证号重复的数据。
SELECT id_card ,count(*) FROM hr_employee
GROUP BY id_card
HAVING count(*) >1
UNION 和 UNION all 的区别
①UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
②UNION ALL 操作符可以连接两个有重复行的 SELECT 语句。
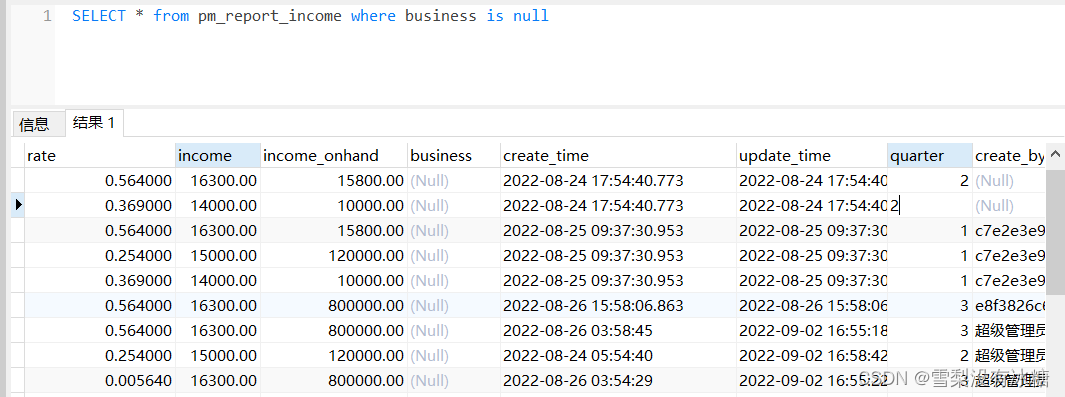
(7)null 和空字符串的区别
①查找字段为 NULL的数据
②查找字段为 空字符的数据
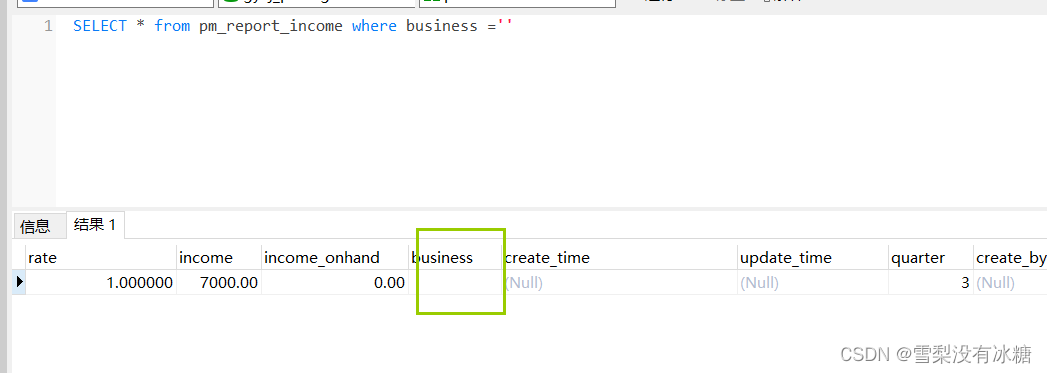
另外 不等于分别是 is not null <>‘’,比如查询一个表,某一个字段不为空的数据,最好加上两个条件 business is not null and business <>‘’
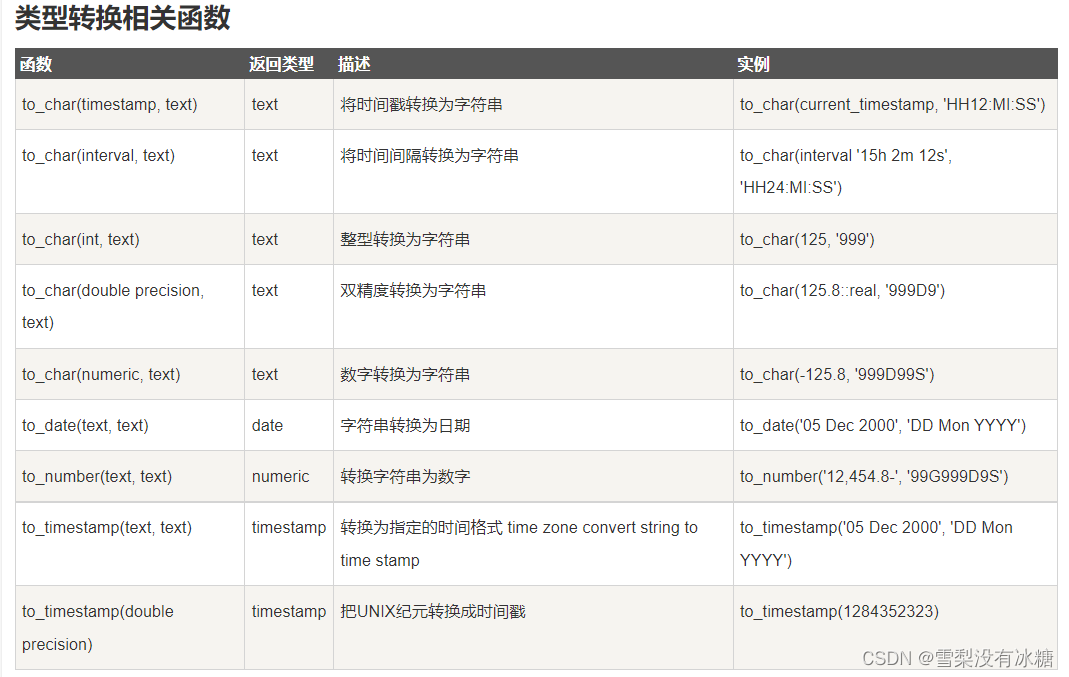
(8)常用时间、日期函数
需要结合 to_date 、to_char两个函数使用,库表时间类型有的是varchar类型的,要转成时间类型
① 获取当前时间
SELECT current_timestamp
② 获取当前日期
--date 是varchar类型
SELECT * from hr_salary_amortize where to_date(date,'yyyy-mm')
=CURRENT_date
--date 是date类型
SELECT * from cm_capital_outflow where date=CURRENT_date
③ 获取当前月份
--date 是varchar类型
SELECT * from hr_salary_amortize where date=to_char(now(),'yyyy-MM')
--date 是date类型
SELECT * from cm_capital_outflow where to_char(date,'yyyy-MM-dd') = to_char(now(),'yyyy-MM-dd')
④ 获取当年的数据
--date 是varchar类型
SELECT * from hr_salary_amortize where substring(date, 1,4)=to_char(now(),'yyyy')
--date 是date类型
SELECT * from cm_capital_outflow where to_char(date,'yyyy') = to_char(now(),'yyyy')
⑤获取近7天的数据
SELECT * from cm_capital_outflow where to_char(date,'yyyy-mm-dd') BETWEEN to_char( CURRENT_DATE - INTERVAL '7 day', 'yyyy-mm-dd' ) AND to_char( CURRENT_DATE, 'yyyy-mm-dd' )
⑥获取近一个月的数据
SELECT * from cm_capital_outflow where to_char(date,'yyyy-mm-dd') BETWEEN to_char( CURRENT_DATE - INTERVAL '1 months', 'yyyy-mm-dd' ) AND to_char( CURRENT_DATE, 'yyyy-mm-dd' )
⑦获取近一年的数据
SELECT * from cm_capital_outflow where to_char(date,'yyyy-mm-dd') BETWEEN to_char( CURRENT_DATE - INTERVAL '1 year', 'yyyy-mm-dd' ) AND to_char( CURRENT_DATE, 'yyyy-mm-dd' )
'yyyy-MM-dd hh24:mi:ss:ms'
(9)类型转换相关函数
(10)shape数据转json函数
select ST_AsGeoJSON(shape) from dt_yfcj LIMIT 1
(11) 多次关联一个表
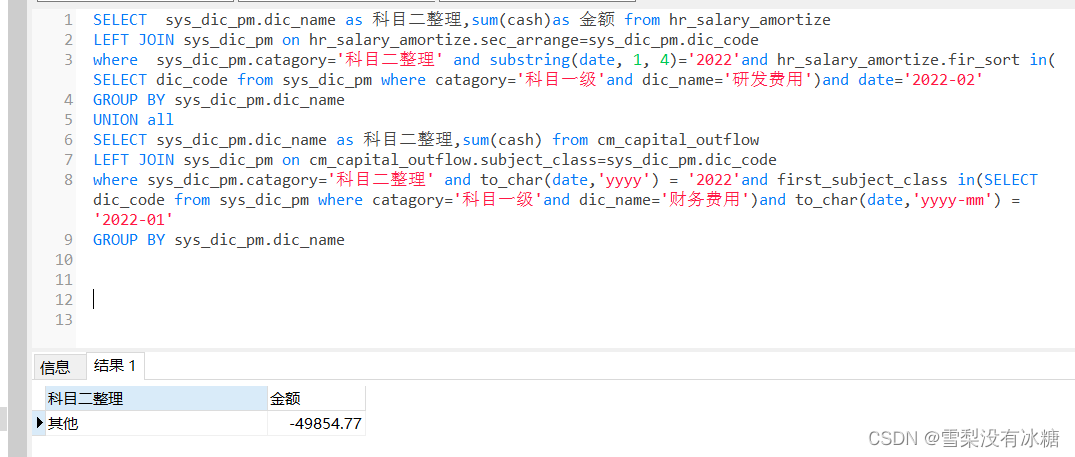
例如:一个表中有多个字典项,需要多次关联字典表
SELECT id as 唯一ID,date as 日期,cash as 金额,payee as 对方单位名称,bank_remarks as 银行摘要,bank as
所属银行或现金,pm1.dic_name as 一级科目,pm2.dic_name as 二级科目,subject_class as 科目二分类,employee as 支出所属人员,
employee_department as 所属部门,employee_province as 所属省份,employee_district as 所属大区,project_code as 项目编码,project_name as 项目名称,project_type as 项目类型,project_province as 项目省份,remark as 审核备注
from cm_capital_outflow
LEFT JOIN sys_dic_pm pm1 on cm_capital_outflow.first_subject=pm1.dic_code and pm1.catagory='科目一级'
LEFT JOIN sys_dic_pm pm2 on cm_capital_outflow.second_subject=pm2.dic_code and pm2.catagory='科目二级'
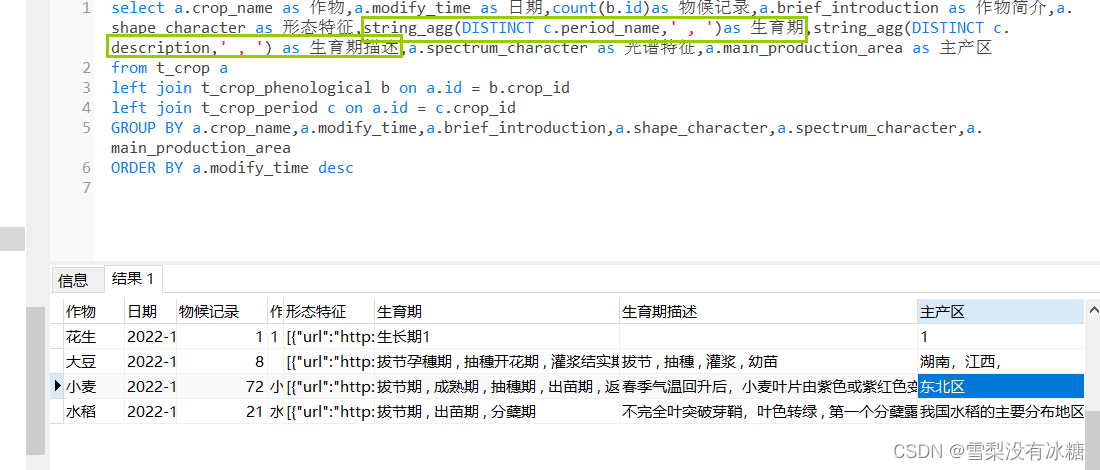
(12)string_agg聚合函数:几行数据中的 同一 单字段值根据连接符拼接
格式:string_agg(字段名,‘,’),将多行结果字符串拼接到一行
(13)有分隔符串的数据,取出来作为关联条件
使用函数:regexp_split_to_array(字段名,’分割符’)
SELECT name,sys_area.qhmc 目的地,lcsj,lcnznh 牛只编码,s1.value 性别,s2.value 品种 from
(SELECT unnest(regexp_split_to_array(lcnzbh,',')) lcnznh,qhdm,to_char(lcsj,'yyyy-MM-dd') lcsj from yw_cattle_departure where to_char(gmt_created,'yyyy')='2023'and lcyy='001') m
LEFT JOIN yw_cattle on m.lcnznh=yw_cattle.nzbh
LEFT JOIN yw_subject on yw_cattle.subject_id=yw_subject.uuid
LEFT JOIN sys_area on m.qhdm=sys_area.qhdm
LEFT JOIN sys_dic s1 on yw_cattle.sex=s1."key" and s1.category='nzxb'
LEFT JOIN sys_dic s2 on yw_cattle.sex=s2."key" and s2.category='nzpz'
where yw_cattle.qhdm like '640522%'
(14)A表关联B表,只取B表最新的数据,且需要查询出其他字段
PARTITION BY: 表示分组
ORDER BY: 表示排序
SELECT a.qhmc,ljmy 累计免疫,zhjzsl 待免疫牛只 from (
SELECT qhmc,sum(mynzsl) ljmy from yw_immune_register where qhdm like '640522208%'and mysj>='2023-04-01'and mysj<='2023-04-30'
GROUP BY qhmc)a
LEFT JOIN (
SELECT qhmc ,zhjzsl from (
SELECT row_number() over (partition by subject_id ORDER BY gmt_created desc) id,* from yw_immune_register)
t where id=1 and mysj>='2023-04-01'and mysj<='2023-04-30' and qhdm like '640522208%')b
on a.qhmc=b.qhmc
(15)A表关联B表,只取B表最新的数据,不需要查询其他字段
SELECT a.nzbh 牛只编号,a.ebh 耳标编号,c.temp 体温,c.jbu 步数,c.create_time 监测,case a.sfdb when '1' then '正常' else '掉标' end as 是否掉标状态 FROM yw_cattle a
LEFT JOIN (SELECT equipment_id,max(create_time) as create_time FROM yw_ebmonitor GROUP BY equipment_id) b on a.ebh=b.equipment_id
LEFT JOIN yw_ebmonitor c on b.equipment_id=c.equipment_id and b.create_time=c.create_time
WHERE a.ebh <>'' and a.subject_id in (SELECT subjectid from sys_user where nikename='李兴虎');
(16)两个sum值相除
SELECT cast(
(SELECT sum(mynzsl) myzs from yw_immune_register
LEFT JOIN sys_dic on yw_immune_register.ymlx=sys_dic.key and category='ymlx'
where qhmc='南湾村'and mysj>='2023-04-01'and mysj<='2023-04-30'and value='口蹄疫O型二价灭活疫苗')*100
/
(SELECT sum(clsl) zcnz from yw_immune_register
LEFT JOIN sys_dic on yw_immune_register.ymlx=sys_dic.key and category='ymlx'
where qhmc='南湾村'and mysj>='2023-04-01'and mysj<='2023-04-30'and djlx='1' and value='口蹄疫O型二价灭活疫苗')
as decimal(18,2)
) 免疫进度
(17)日期上加天数
--时间轴,临近生产日期是预警日期
SELECT djsj 配种日期,to_char(djsj+INTERVAL '280 day','yyyy-mm-dd') 预产日期
from (
SELECT row_number() over (partition by ebh ORDER BY djsj desc) xh,* from yw_cattle_breed where djlx='006')
t where xh=1 and ebh='6405225555555'
(18)数字+null
with a as (
SELECT sys_area.qhmc xz ,yw_immune_register.qhmc xzc ,sum(cncsl*cncjl) cnjl,sum(smwcncsl*smwcncjl) wcnjl ,sum(mynzsl) ljnz,clsl ,ymsl from yw_immune_register
LEFT JOIN sys_area on substring(yw_immune_register.qhdm,1,9)=sys_area.qhdm
where ymlx='001' and to_char(mysj,'yyyy-mm')='2023-04'and yw_immune_register.qhdm like '640522%'
GROUP BY sys_area.qhmc ,yw_immune_register.qhmc ,clsl,ymsl
ORDER BY yw_immune_register.qhmc)
SELECT xz 乡镇,xzc 行政村 ,COALESCE(cnjl,0)+COALESCE(wcnjl, 0) 疫苗使用量,ljnz 累计免疫牛只 ,ljnz*100/clsl 免疫密度,ljnz*100/ymsl 免疫进度 from a
(19)统计不为空的数据条数
SELECT count(*) 智能耳标 from yw_cattle where ebh is not null and sfzc='1'and ebh<>'' and qhdm like '640522%'and to_char(gmt_created,'yyyy')='2023'
(20)计算每个月份累加
函数:sum(jcmn) over (ORDER BY yf)
SELECT yf 月度,sum(jcmn) over (ORDER BY yf) 在场牛只 from(
SELECT to_char(gmt_created,'yyyy-mm') yf,count(nzbh) jcmn from yw_cattle where sfzc='1' and qhdm like '640522208%'and sex in ('002')
GROUP BY to_char(gmt_created,'yyyy-mm'))a
(21)获取多个表中的数据,但字段个数不同
select qymc 企业名称,qhmc 属地,lxr 联系人,lxdh 联系电话,sshy 所属行业,zycp 主营产品,jb 级别 from yw_jyzt_ltqy
union all
select ncmc,qhmc,nczxm ,lxdh,'--','--','--' from yw_jyzt_jtnc
union all
select hzsmc,qhmc,lszxm ,lxdh ,'--','--',bcdj from yw_jyzt_hzs
(22)一条数据中,多个字段值拼接在一起
例如根据qhdm查询省、市、县、乡镇、村
select ypbh 样品编号, concat_ws(' ',s1.qhmc,s2.qhmc,s3.qhmc,s4.qhmc,yw_germplasm.qhmc) 地点,zwmc 作物名称,zzmc 种质名称,zzlxmc 种质类型,zzlymc 种质来源,bzq 播种期,shq 收获期,zzytmc 种质用途 from yw_germplasm
left join sys_area s1 on substring(yw_germplasm.qhdm,1,2)=s1.qhdm
left join sys_area s2 on substring(yw_germplasm.qhdm,1,4)=s2.qhdm
left join sys_area s3 on substring(yw_germplasm.qhdm,1,6)=s2.qhdm
left join sys_area s4 on substring(yw_germplasm.qhdm,1,9)=s2.qhdm
另外多行数据,同一个字段的值拼接,再把多个字段拼接
string_agg(concat_ws(':',aaa,bbb),',' order by aaa asc) as xxx














 6048
6048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









