






答:三步
- 在图片处理软件中将图片源文件进行分层。
- 找出所有文字图层,发布文字翻译需求,从供应商获取进行翻译后的文字。
- 将翻译后的文字替换源图片文字图层,保存导出。
好勒,本期问题已完美解决,让我们下期…诶这位观众你干嘛,有什么问题我们好好说,有什么不理解的我就再重新讲一遍,咱先把刀放下。
咱观众可真是笃实好学,听到要下课了都按捺不住心中的一腔热血啊,那我就再简单补充亿点!
其实要手工处理好图片翻译除了这些基本的步骤,还需要对文案图层样式进行适配,微调布局等等。一张图片的工作量不大,十张图片的工作量也还好。那如果有成千上百张呢,这时候效率就成了一个亟需解决的问题。通过AI识图来进行图片翻译工作,不失为一个流程优化辅助的方向。
1. 整体流程
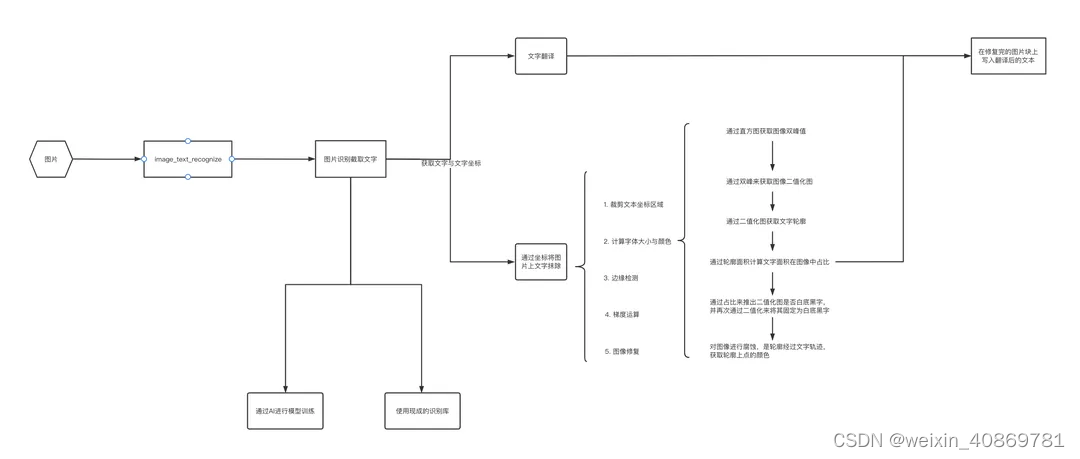
2. 前置概念
2.1 OCR
-
OCR(optical character recognition)光学文字识别,指通过编程程序,在扫描仪或者计算机等载体上对图片进行读取解析,通过对其中的形状轮廓进行分析,并与AI训练出的文本库进行匹配,提取出计算机文字的过程。在高速发展的现代社会中落地了诸多场景,如交通,教育,医疗等等,相较于传统的人工方式极大的提高了生产效率。
-
卷积与图像识别
- 卷积究竟是卷个啥
积分公式: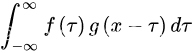
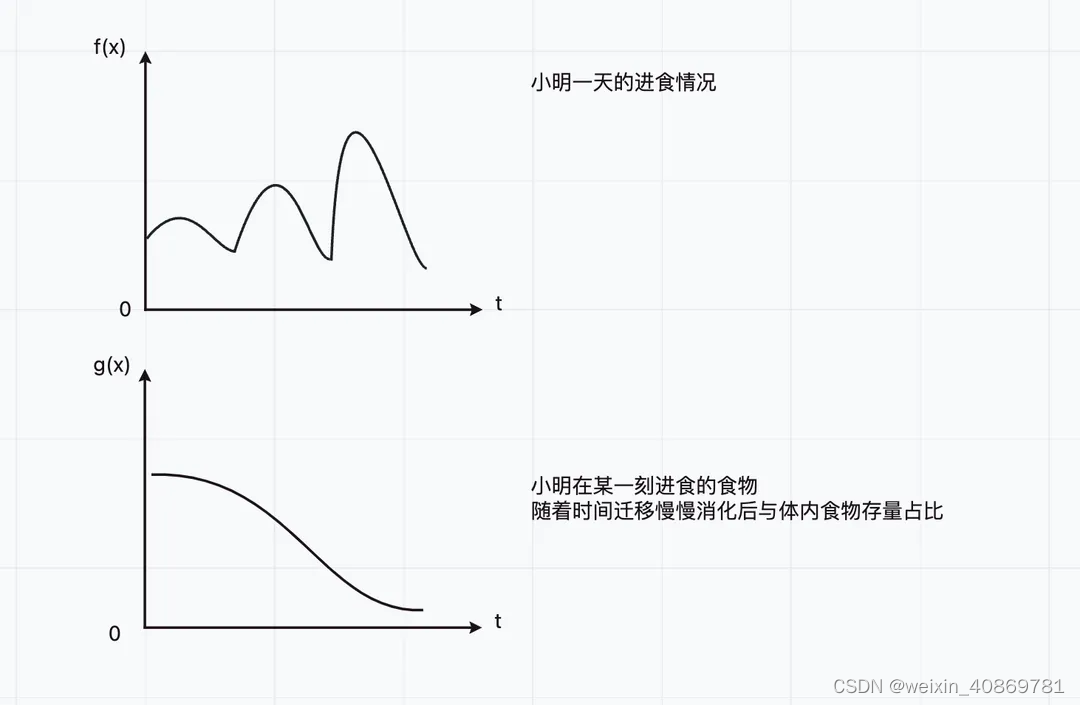
作为一个已经把积分知识原封不动的还给老师的学渣,我当机立断的停止思考,并在网上搜索卷积知识相关的讲解教程,经过一番学习(挣扎)之后,我决定以小明一天的饮食情况来切入主题。
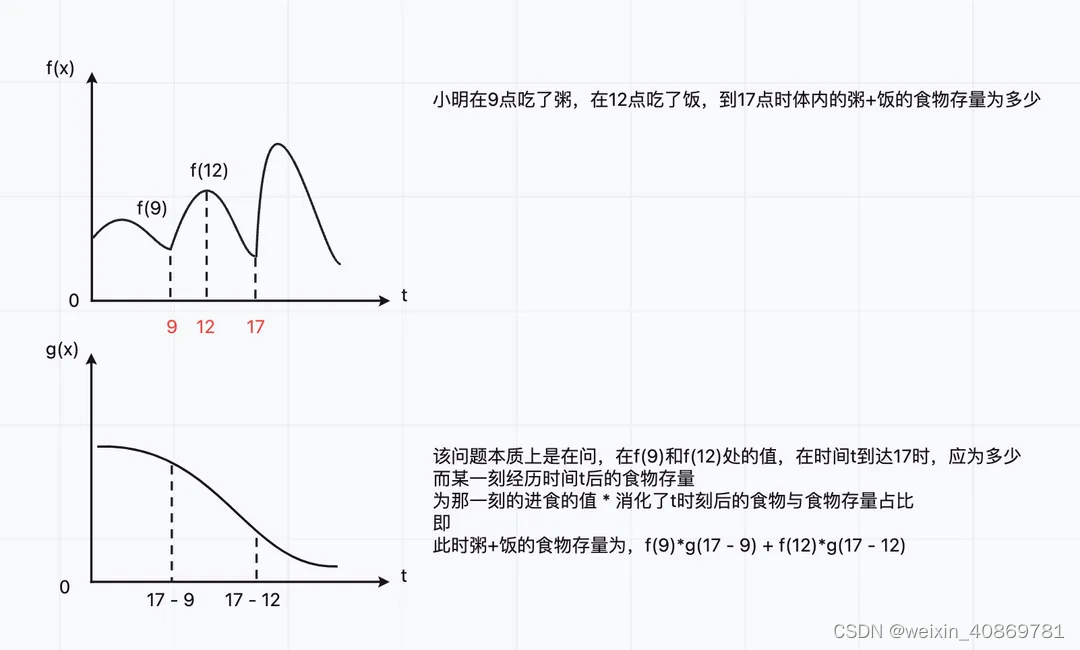
- 卷积究竟是卷个啥
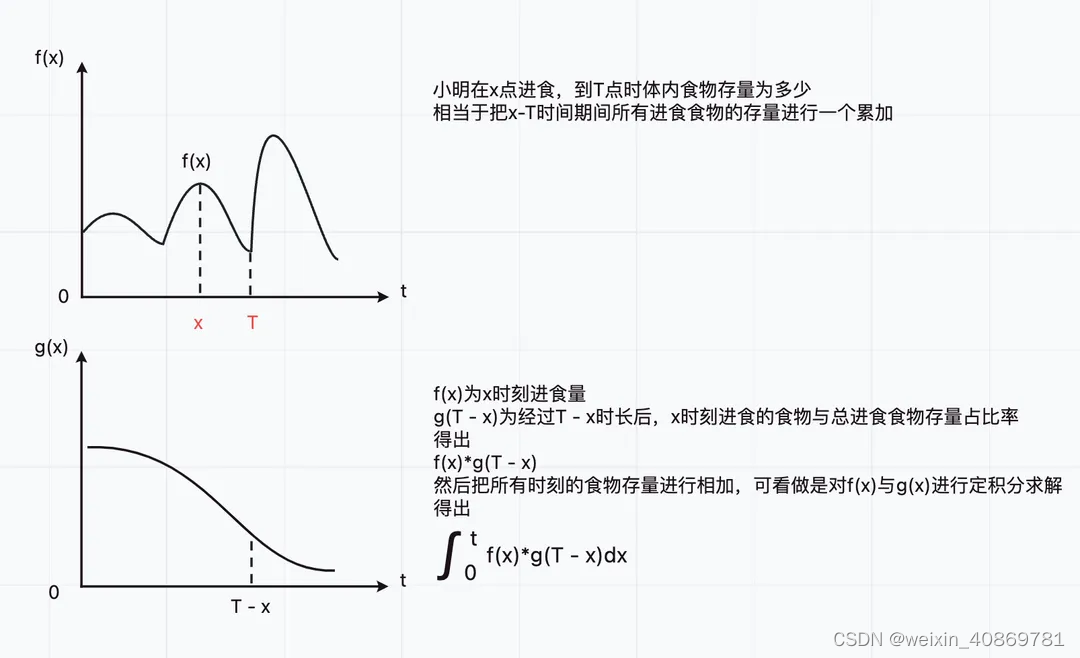
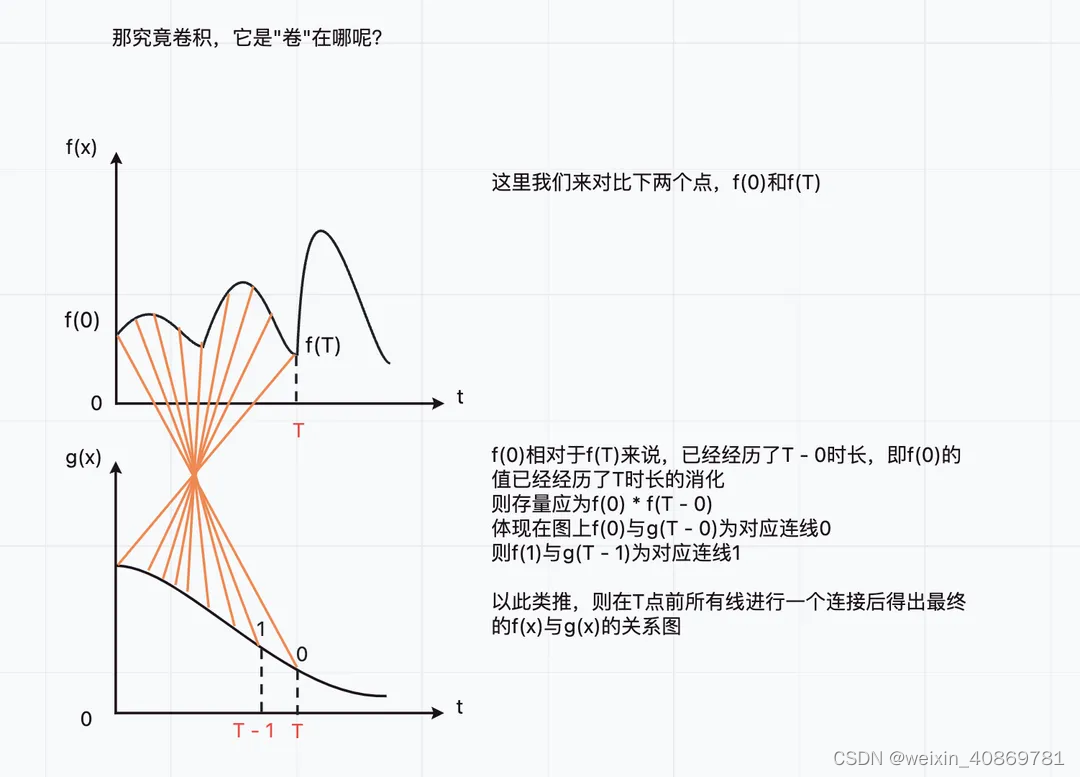
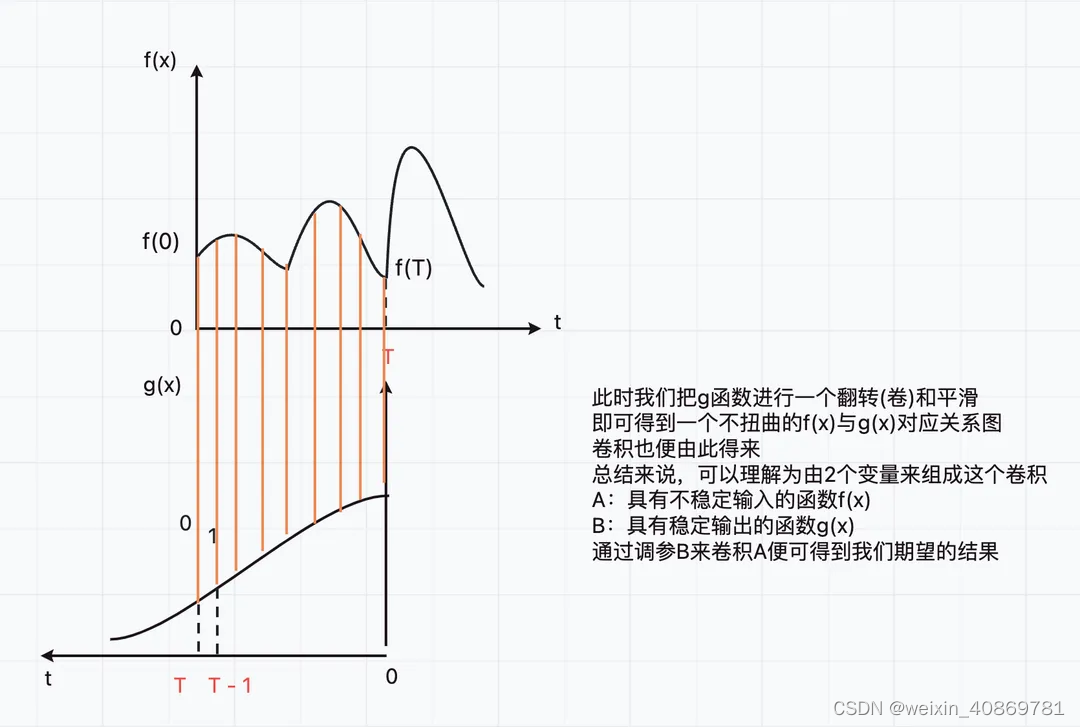
通过小明一天的饮食可以看出,其实我们是在无穷大小范围内,通过给定的具有不稳定输入的函数f(x)与具有稳定输出的函数g(x),求一个定积分,也就是把x ~ r期间,f®函数的值与g(x-r)函数的值乘积,并把当前给定的区间范围[-∞, +∞]内的所有乘积值累加。
- 图像识别中的卷积原理
- 那么我们怎么在图像中运用卷积的技术进行图像处理呢,首先我们来确定这2个函数,分别对应图像处理中的什么角色。
- 图像处理,需要2个参数,源图片文件和一个m*m的正方形卷积核。对于计算机来说,图像是由有限多个像素点组成的,每个像素点根据图像拥有的通道数,有具体数字来代表它的颜色。比如RGB图像,则一个像素点由3种颜色共同组成(B,G,R),而灰度图,则一个像素点由一个数值代表G通道的值。而通过将卷积核上的点一一对应源图像上的点乘积后的输出,即是我们期望得到的结果。
引用一张图
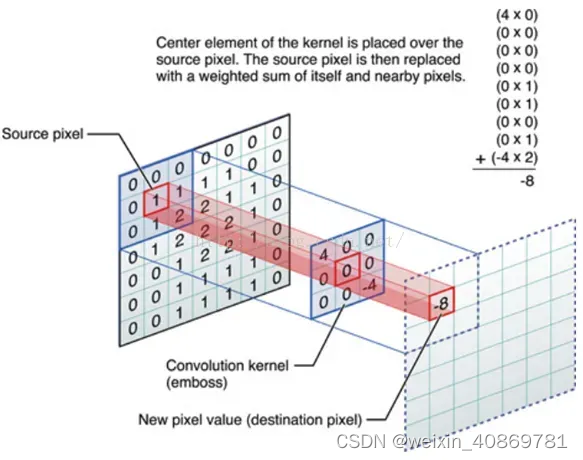
可以看出源图上对应卷积核大小的方格,与卷积核对应格子的数值相乘后相加,即是结果图像中当前像素点的值,注意通过卷积核卷积后的图像总会少一圈像素点,通常在源图像最外层加上0值像素以补全结果。
由此可推出,具有不稳定输入的函数f(x)可以理解为每一个由不同像素值组成的原始图像,而具有稳定输出的函数g(x)可以称为与原始图像进行作用的点,所有作用点合起来称为卷积核。并由此引出以下几种常见的图像处理策略,以达到满足我们期望的结果图像。
3. 技术选型
3.1 市面上有许多第三方库实现了ocr的流程,这里对离线端部分库做了试验
-
离线端:
- pytesseract
-
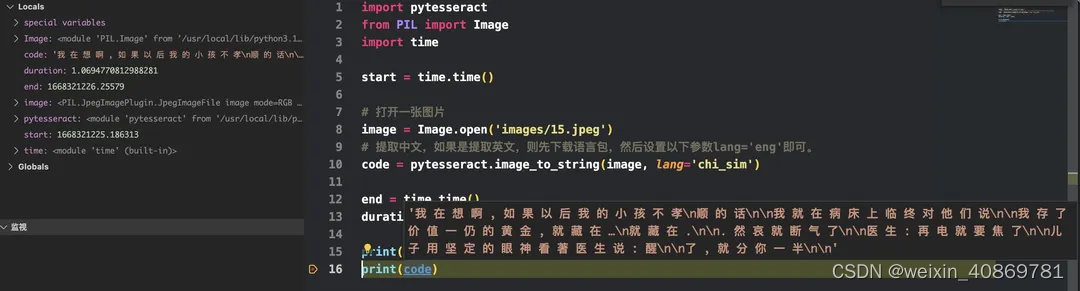
-
执行时间:1.0694s
-
速度较快,但只能获取文本,无法获取文本坐标
-
- cnocr
-
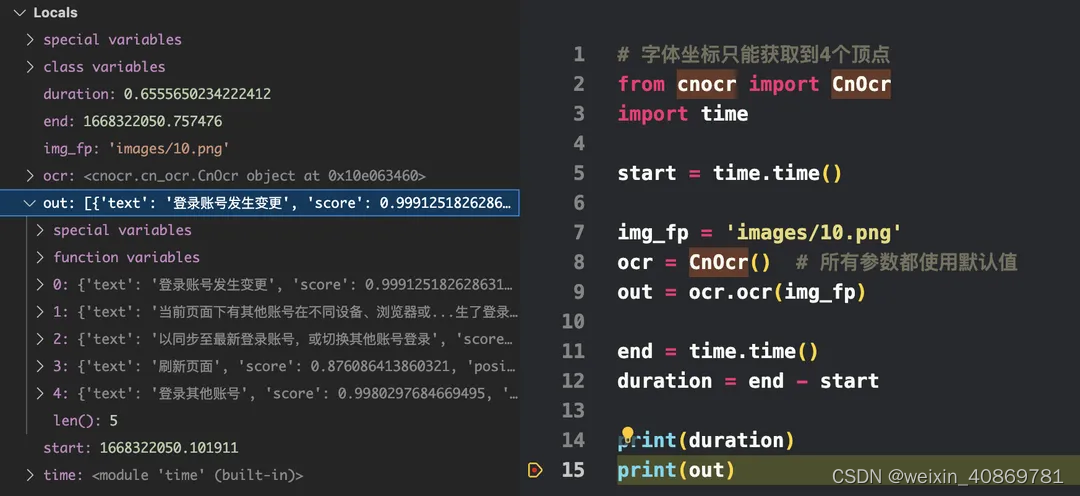
-
执行时间:0.655s
-
速度较快,能获取文本与文本框四个顶点坐标
-
- EasyOCR
-
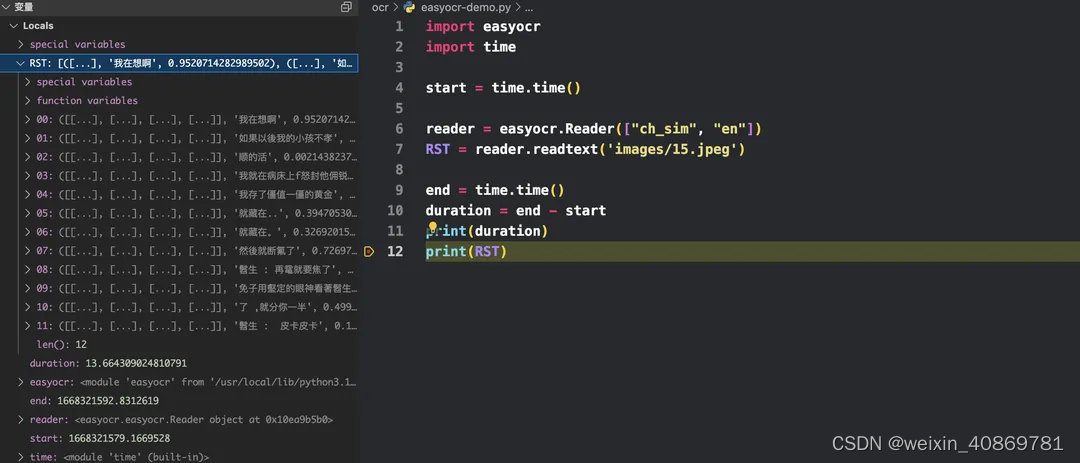
-
执行时间:13.664s
-
识别率高,但速度巨慢,能获取文本与文本坐标
-
- Chineseocr
- chineseocr_lite
- PaddleOCR
- TrWebOCR
- pytesseract
-
API:
-
基于几点考虑,最终尝试用 EasyOCR + 腾讯云翻译 来实现图片翻译
-
在调研过程中偏向于用离线端方案,开源库灵活性较强,并且有可能可以自己训练翻译模型。而API端不开源,并且服务费用成本高,需要花费一定成本。
-
EasyOCR支持自带80多种语言包支持,应用场景较广,并且能获取到文本具体坐标,对于图片比较有利文本替换的实现。
-
腾讯云api文档齐全,并且有较高的免费额度以供测试

-
基于1期方案实现后考虑自己训练模型,来解决EasyOCR翻译慢的问题。
-
4. 步骤拆解
4.1 图片识别截取文字
- 通过前期技术调研后确定通过EasyOCR来实现这部分功能
import easyocr
import cv2
def detect(imagePath, lang):
# 解析繁体/英文/数字
reader = easyocr.Reader(lang)
RST = reader.readtext(imagePath)
origin_cv_image = cv2.imread(imagePath)
result = []
texts = []
...
...
if __name__ == '__main__':
# 读取文件
_, imagePath, *lang = sys.argv
if(len(lang) == 0):
lang = ["ch_sim", "en"]
new_image = detect(sys.argv[1], lang)
cv2.imshow('new_image', new_image)
cv2.waitKey()
cv2.destroyAllWindows()
...
- 对图片扫描后,获取包含文本与文本坐标的数据结构
4.2 计算文本大小、颜色,并进行翻译
- 循环扫描结果,取出每行文字的左上角与右下角坐标
- 将坐标文字存储到一个数组,将文字也存储为一个数组
- 调用腾讯云翻译接口对文字数组进行批量翻译,减少网络请求次数
- 循环坐标文字数组,计算文字大小与颜色,颜色处理比较麻烦,下面单独讲解
- 调用put_text_into_image,将翻译好的文本替换进原始图片对应文本坐标位置
def detect(imagePath, lang):
# 解析繁体/英文/数字
reader = easyocr.Reader(lang)
RST = reader.readtext(imagePath)
origin_cv_image = cv2.imread(imagePath)
result = []
texts = []
for detection in RST:
# easyocr获取到文字区域的左上角坐标
left_top_coordinate = tuple(detection[0][0])
# easyocr获取到文字区域的右上角坐标
right_bottom_coordinate = tuple(detection[0][2])
# easyocr获取到的文字
text = detection[1]
texts.append(text)
result.append([
left_top_coordinate,
right_bottom_coordinate,
text,
])
# 调取api对文字进行翻译
allTexts = transformText(texts)
for inx, val in enumerate(result):
ltc, rbc, t = val
font = ImageFont.load_default()
#字体大小
fontScale = int(abs(ltc[0] - rbc[0]) / len(allTexts[inx]))
# 如果是英文句子,则字体大小进行一个2.2倍的放大,暂时以这个方案解决字体过小问题
if pattern.fullmatch(allTexts[inx]):
fontScale = int(fontScale * 2.2)
color = get_text_color(
cv2.resize(
origin_cv_image[ltc[1]:rbc[1], ltc[0]:rbc[0]],
(0, 0),
fx=10,
fy=10,
interpolation=cv2.INTER_CUBIC
)
)
font = ImageFont.truetype(
fontType,
fontScale,
encoding="unic"
)
origin_cv_image = put_text_into_image(
origin_cv_image, ltc, rbc, allTexts[inx], font, color, fontScale
)
return origin_cv_image
- 字体颜色处理,调研了5种方案的可行性,最终暂定先采用方案3来实现
-
- 获取轮廓,缩小轮廓让其刚好经过线上的点,取点的颜色
-
- 获取轮廓,缩小轮廓让其刚好经过线上的点,取所有点的颜色的平均值
-
- 通过获取图片双峰值,通过双峰值对图像二值化处理后,得到文字轮廓,通过计算文字轮廓面积与总面积占比,得出二值化结果是白底黑字还是黑字白底,然后再通过二值化将其统一成白底黑字,将原图进行腐蚀,缩小轮廓让其刚好经过线上的点,取点的颜色
-
- 直方图,取2个波峰的值,一个是背景一个是字体颜色
-
- 取区域内平均色值
-
# 阈值分割:直方图技术法
def threshTwoPeaks(image):
#转换为灰度图
if len(image.shape) == 2:
gray = image
else:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 计算灰度直方图
histogram = calcGrayHist(gray)
# 寻找灰度直方图的最大峰值对应的灰度值
maxLoc = np.where(histogram == np.max(histogram))
firstPeak = maxLoc[0][0] #灰度值
# 寻找灰度直方图的第二个峰值对应的灰度值
measureDists = np.zeros([256], np.float32)
for k in range(256):
measureDists[k] = pow(k - firstPeak, 2) * histogram[k]
maxLoc2 = np.where(measureDists == np.max(measureDists))
secondPeak = maxLoc2[0][0]
return [firstPeak,secondPeak]
def get_text_color(originImg):
img = originImg.copy()
img = cv2.pyrMeanShiftFiltering(img, 10, 50)
# 通过波峰值获取字与背景颜色
[max_color, min_color] = threshTwoPeaks(img)
# 获取字体轮廓内面积、计算其与总面积占比
ratio = get_font_color_ratio(img, min_color, max_color)
# 计算出阈值与二值化的策略和应该填充的颜色值
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 15*15的矩形卷积核
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(15, 15))
RedThresh = get_redThresh(gray_img, min_color, max_color, ratio)
# 统一成白底黑字
binarization = cv2.dilate(RedThresh,kernel)
cnts,hierarchy = cv2.findContours(
binarization,
cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE
)
cnts = np.delete(cnts, 0)
if len(cnts)>=2 and (cnts[0] & cnts[0][0] & cnts[0][0][0]).any():
point = list(cnts[0][0][0])
else:
point = None
if point:
# GBR
color = tuple(originImg[point[1], point[0]])
else:
color = (0,0,0)
return color[::-1]
4.3 将翻译好的文本替换到图像上
- 计算出文本轮廓
- 修复图片,去除掉运算后得出的文本轨迹包括到的内容
- 将文本写入原图
def put_text_into_image(origin_cv_image, lt, rb, text, font, color, fontScale):
size = 3
# 裁剪文本坐标,[y0:y1, x0:x1]
text_img = origin_cv_image[lt[1]:rb[1], lt[0]:rb[0]]
cv2.imwrite('text_img.png', text_img)
# 裁剪文本坐标,[y0:y1, x0:x1]
# 边缘检测
img = cv2.imread('text_img.png')
canny_img = cv2.Canny(img, 200, 150)
cv2.imwrite('canny_img.png', canny_img)
# 边缘检测
# 梯度运算
rate = int(fontScale/2)
if rate > 15:
rate = 15
img = cv2.imread('canny_img.png', 1)
k = np.ones((rate, rate), np.uint8)
img2 = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, k)
cv2.imwrite('gradient_img.png', img2)
# 梯度运算
# 图像修复,将通过梯度运算出来的图片与原始图像进行融合
repair_cv_image = repair(origin_cv_image, lt, rb)
# 图像修复
# 在修复完的图片块上写入文本
return write(repair_cv_image, lt, rb, text, font, color)
# 在修复完的图片块上写入文本
4.3.1 裁剪文本区域,缩小处理范围,调高程序执行效率
text_img = origin_cv_image[lt[1]:rb[1], lt[0]:rb[0]]
4.3.2通过运算来得出文本轮廓,这里涉及到几个算法的概念。经过几个算法的效果对比,最终采用了轮廓获取效果较为准确的梯度运算。
img = cv2.imread('canny_img.png', 1)
k = np.ones((rate, rate), np.uint8)
img2 = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, k)
cv2.imwrite('gradient_img.png', img2)
4.3.3 进行图像修复,将修复好的图片块与原图融合
# 修复图像
def repair(origin_cv_image, lt, rb):
# 读取梯度运算后的图片
gradient_png = cv2.imread('gradient_img.png', 0)
# 裁剪原图坐标为[y0:y1, x0:x1]
src_img = origin_cv_image[lt[1]:rb[1], lt[0]:rb[0]]
# 将通过梯度运算出来的图片与裁剪原图进行融合修复,去除掉梯度运算轨迹包括到的内容
dst = cv2.inpaint(src_img, gradient_png, 5, cv2.INPAINT_TELEA)
# 将修复完的图片块再放回去
origin_cv_image[lt[1]:rb[1], lt[0]:rb[0]] = dst
return origin_cv_image
4.3.4 在修复完的图片块上写入文本
def write(IMG, lt, rb, text, font, color):
# 将图片的array转换成image
img_pil = Image.fromarray(cv2.cvtColor(IMG, cv2.COLOR_BGR2RGB))
# 进行图像绘制
draw = ImageDraw.Draw(img_pil)
# 进行文本写入
draw.text(lt, text, font=font, fill=color) #PIL中BGR=(255,0,0)表示红色
#PIL图片转换为numpy
img_ocv = np.array(img_pil)
IMG = cv2.cvtColor(img_ocv,cv2.COLOR_RGB2BGR)
# 圈出图片上文字区域
# return cv2.rectangle(IMG, lt, rb, (0,255,0), 3)
return IMG
5. 仓库地址
https://github.com/lcoln/image_text_recognize
6. DEMO演示
-

-
emmm…目前识别速度和精度还有许多提升空间😂
7. TODOLIST
- 自训练模型替换EasyOCR以提高文字识别速度和精度
- 尝试与js交互,实现本地化翻译















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









