







简介
什么是ELK
ELK是起初由3个组件首字母组合而来的,三个组件分别是Elasticsearch、Logstash、Kibana。后续又加入了其他组件如Beats等。
Elasticsearch
Elasticsearch,简称ES,是一个开源的、高扩展的、分布式全文搜索引擎。
Elasticsearch是整个Elastic Stack技术栈的核心。
Elasticsearch可以近乎实时的存储、检索数据。
Elasticsearch有很好的扩展性,可以扩展到上百台服务器,可以处理PB级别的数据。
Logstash
Logstash是一个免费且开发的服务器端数据处理管道,能够从多个来源采集数据、转换数据。
Logstash还可以将数据发送到存储库中。
Beats
Beats是一个免费且开放的平台,集合了多种单一用途的数据采集器。
Beats可以从成百上千或成千上万台服务器和系统向Logstash或Elasticsearch发送数据。
Kibana
Kibana是一个免费且开发的用户界面,能够让Elasticsearch数据可视化。
Kibana可以为ElasticStack提供导航,可以进行各种操作。
Kibana可以跟踪查询负载,可以理解请求如何流经整个应用。
ElasticStack(ELK)
ELK和ElasticStack区别
ElasticStack的早期名字叫ELK,是由三个开源软件组成的数据处理框架。
由于后期新成员的加入到ELK中,ELK更名为ElasticStack。
ElasticStack家族成员可以放在一起使用,每个成员也可以单独使用,它们要解决的核心问题都是数据。
ElasticStack(ELK)优点
- 处理方式灵活:
- Elasticsearch是实时全文检索,具有强大的搜索功能。
- 配置相对简单:
- Elasticsearch全部使用JSON接口。
- Logstash使用模块配置。
- Kibana的配置文件非常简单。
- 检索性能高效:
- 基于优秀的设计,每次查询都是实时的,但可以达到百亿级数据的查询秒级相应。
- 集群线性扩展:
- Elasticsearch和Logstash都可以灵活线性扩展。
- 前端操作绚丽:
- Kibana的前端设计比较绚丽,操作也简单。
ElasticStack(ELK)可以搜集哪些日志
- 容器管理工具日志,如:Docker
- 容器编排工具日志,如:Docker Swarm、Kubernetes
- 负载均衡服务日志,如:LVS、HAProxy、Nginx
- Web服务器日志,如:Httpd、Nginx、Tomcat
- 数据日志,如:MySQL、Redis、MongoDB、Hbase、Kudu、PostgreSQL
- 存储日志,如:NFS、Ceph、HDFS、Fastdfs、Gluterfs
- 业务日志,如:Python、Java、Shell、PHP、C、C++等编程语言开发的APP
基本概念
Elasticsearch基本概念
Elasticsearch中有节点(Node)、索引(Index)、分片(Shard)、副本分片(Replica Shard)
- 节点(Node):物理概念,一个运行的Elasticsearch,一般位于一台服务器上的一个进程。
- 索引(Index):逻辑概念,包括配置信息mapping和倒排索引数据文件,一个索引的数据文件可能会分布于一台服务器,也有可能分布于多台服务器。
- 分片(Shard):为了支持大量数据,索引一般会按某种维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。一个节点一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同的索引。为了保证可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。分片有两种:主分片(Primary Shard)和副本分片(Replica Shard)。
- 副本分片(Replica Shard):同一个分片(Shard)的备份数据,一个分片可能会有0个或多个副本,这些副本中的数据保证强一致或最终一致。
- 主分片和副本分片区别:主分片支持读写(rw),副本分片只支持读(ro)。
Elasticsearch节点类型
一个Elasticsearch实例是一个节点,一组节点组成了集群。Elasticsearch集群中的节点可以配置为3种不同的角色:
- 主节点:控制Elasticsearch集群,负责集群中的操作,比如创建/删除一个索引,跟踪集群中的节点,分配分片到节点。主节点处理集群的状态并广播到其他节点,并接收其他节点的确认响应。
- 每个节点都可以通过设定配置文件elasticsearch.yml中的node.master属性为true(默认)成为主节点。
- 对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。主节点最好只有一个,用来控制和调配集群级的扩展。
- 数据节点(Data Node):持有数据和倒排索引。默认情况下,每个节点都可以通过设定配置文件elasticsearch.yml中的node.data属性为true(默认)成为数据节点。如果我们要使用一个专门的主节点,应将其node.data属性设置为false。
- 客户端节点(Transport Node):如果我们将node.master属性和node.data属性都设置为false,那么该节点就是一个客户端节点,扮演一个负载均衡的角色,将到来的请求路由到集群中的各个节点。
Elasticsearch集群中作为客户端接入的节点叫协调节点。协调节点会将客户端请求路由到集群中合适的分片上。对于读请求来说,协调节点每次会选择不同的分片处理请求,以实现负载均衡。
Elasticsearch集群状态
green:表示Elasticsearch集群中主分片和副本分片都可以正常访问;
yellow:表示Elasticsearch集群中部分副本分片无法正常访问;
red:表示Elasticsearch集群中部分主分片无法正常访问;
架构
在ElasticStack(ELK)中有多种不同架构,如EFK、ELK、ELFK、ELFK+Kafka等
EFK架构
架构图示
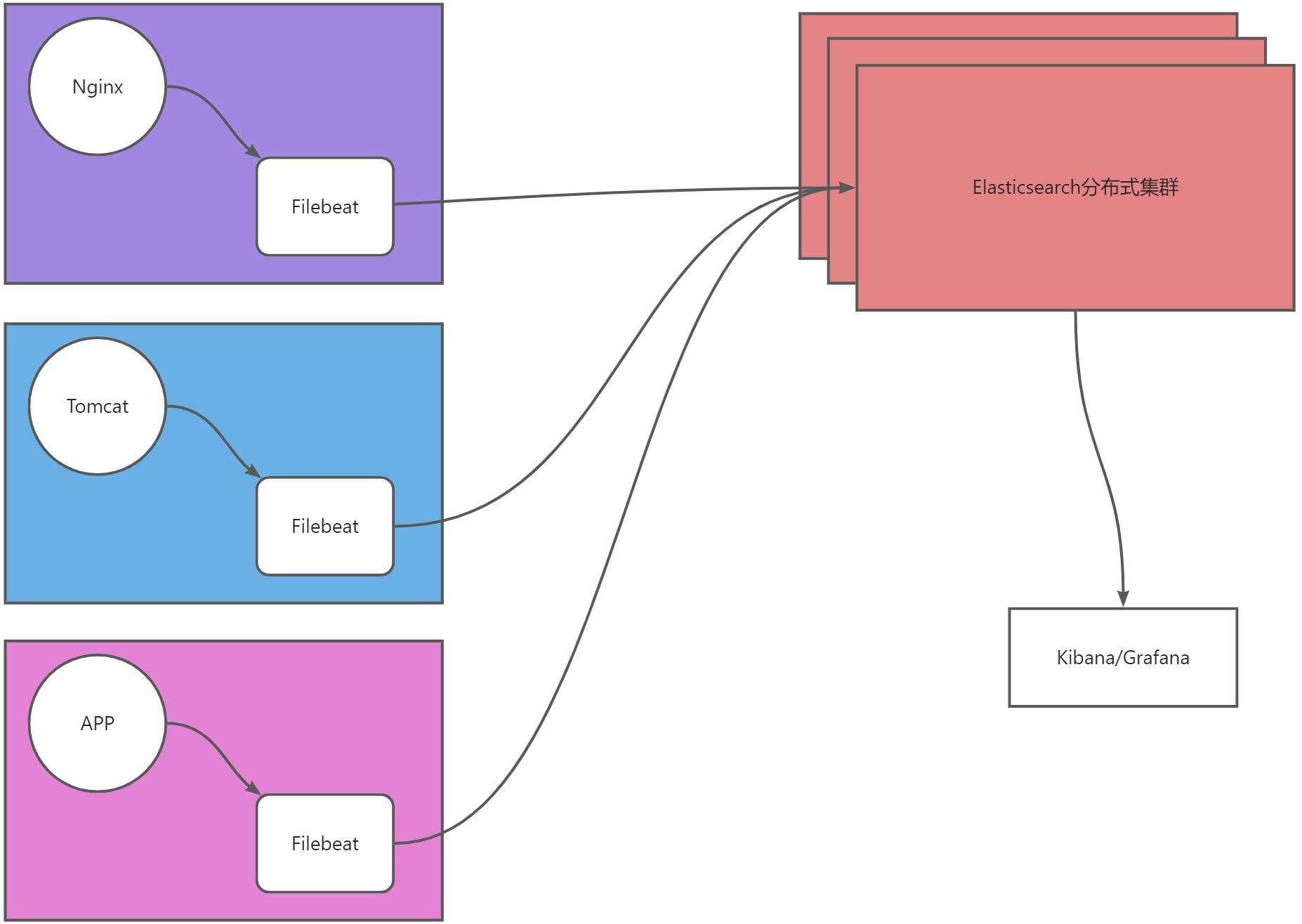
架构解释
- EFK架构即Elasticsearch、Filebeat、Kibana三组件组合,主要用于采集日志。
- Filebeat从数据层(Nginx、Tomcat、APP)采集日志,并将日志存储到Elasticsearch,然后交给Kibana或Grafana展示。
- 数据流向:源数据层(nginx、tomcat、app)–>数据采集层(Filebeat)–>数据存储层(Elasticsearch)
ELK架构
架构图示
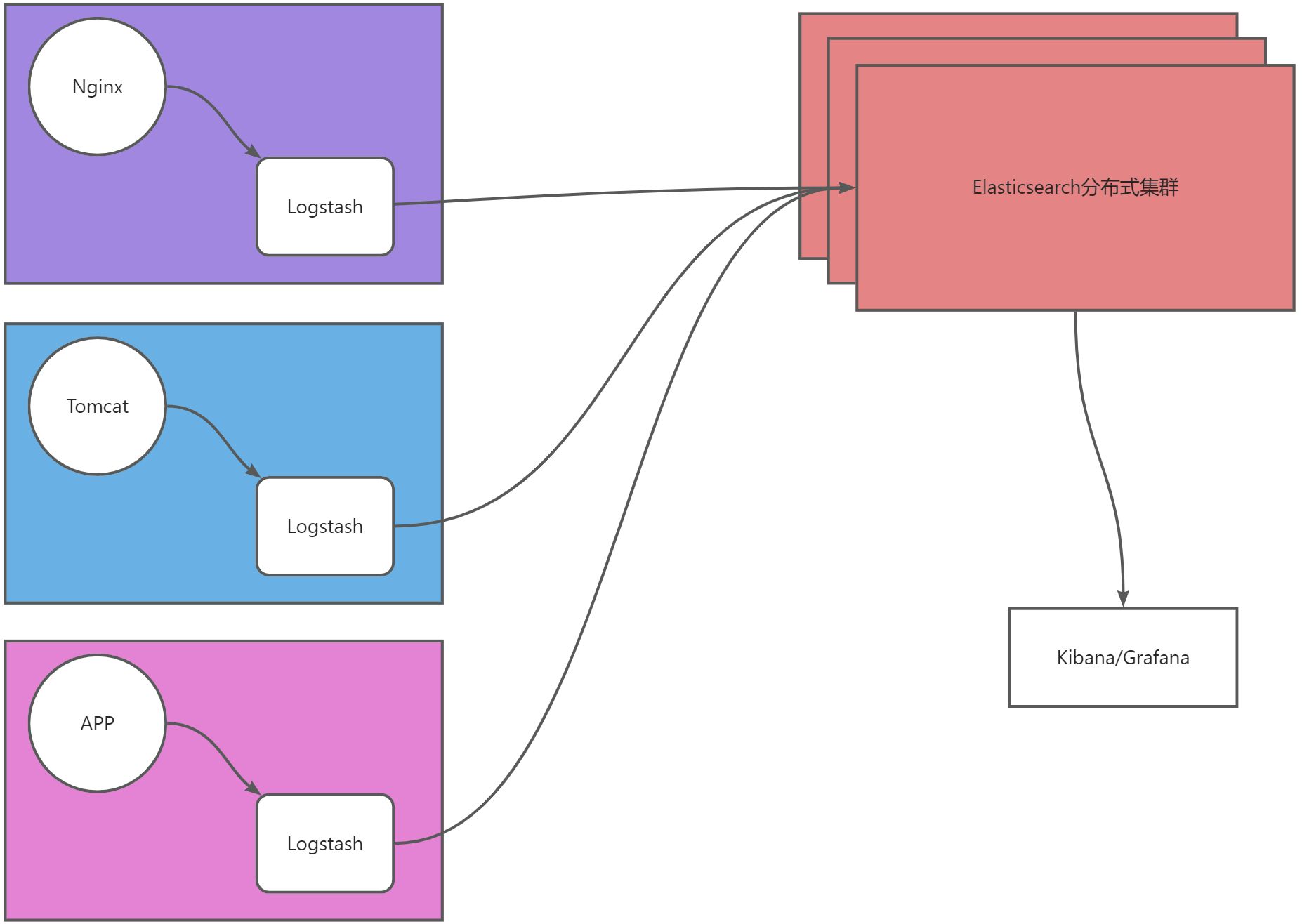
架构解释
- ELK架构即Elasticsearch、Logstash、Kibana三组件组合,主要用于数据采集处理。
- Logstash从数据层(Nginx、Tomcat、APP)采集数据进行简单处理后,将数据存储到Elasticsearch,然后交给Kibana或Grafana展示。
- 数据流向:源数据层(nginx、tomcat、app)–>数据采集/处理层(Logstash)–>数据存储层(Elasticsearch)
ELFK架构
架构图示
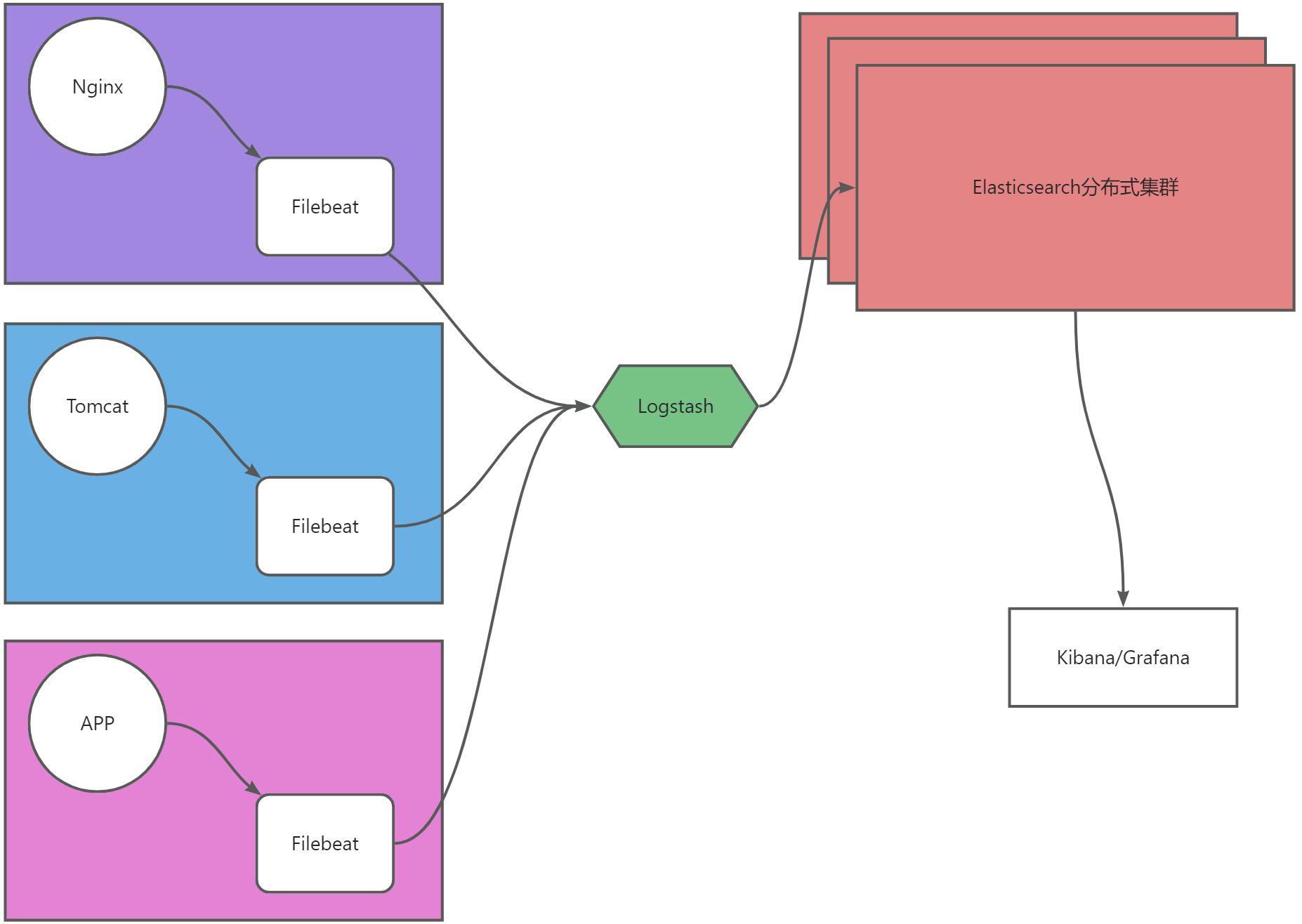
架构解释
- ELFK架构即Elasticsearch、Logstash、Filebeat、Kibana四个组件组合,主要用于数据收集、数据处理、数据存储。
- Filebeat从数据层(Nginx、Tomcat、APP)采集数据,然后将数据交给Logstash进行简单处理,然后将数据存储到Elasticsearch,然后交给Kibana或Grafana展示。
- 数据流向:源数据层(nginx、tomcat、app)–>数据采集层(Filebeat)–>数据处理层(Logstash)–>数据存储层(Elasticsearch)
ELFK+Kafka架构
架构图示
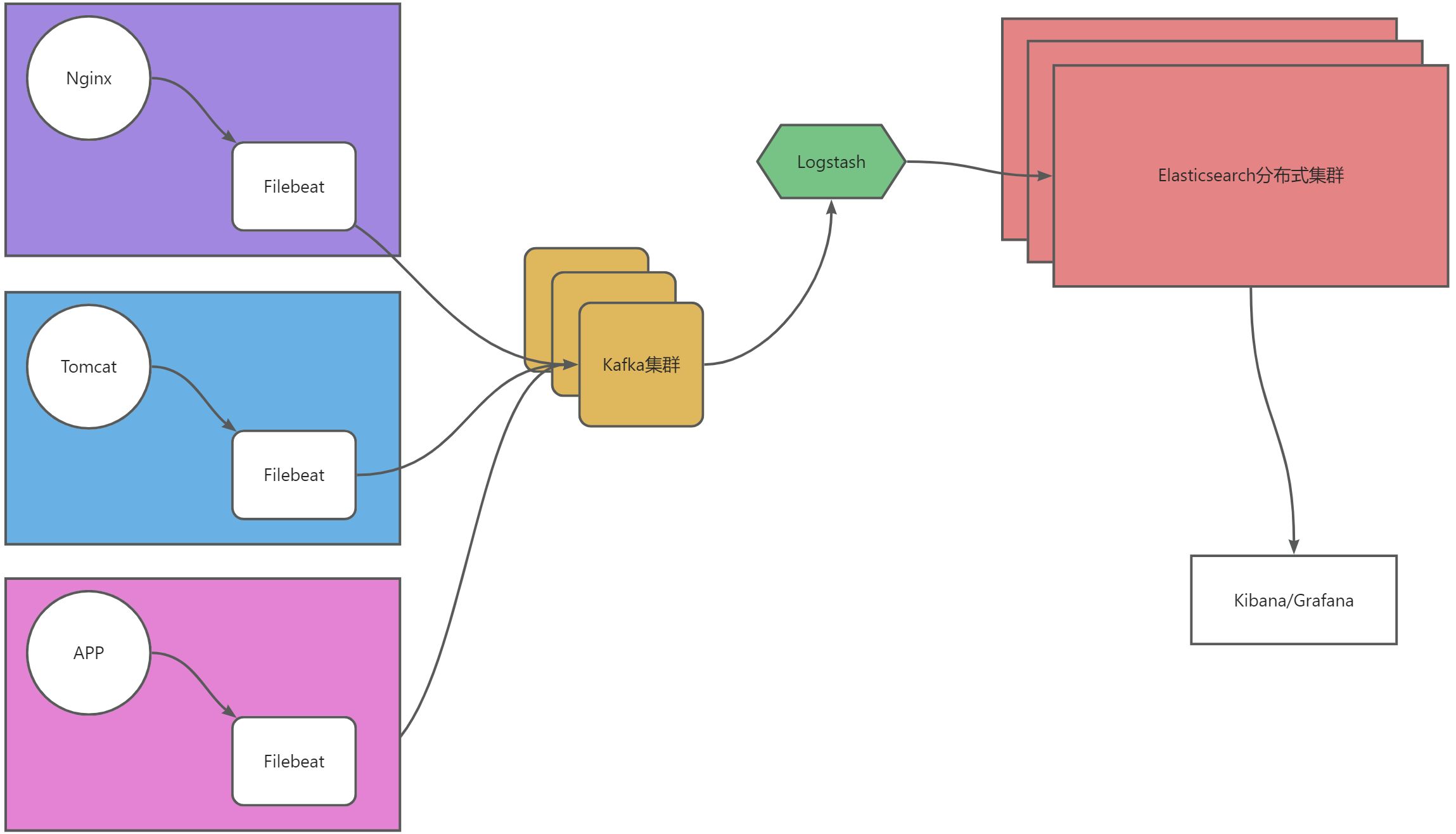
架构解释
- ELFK+Kafka架构即Elasticsearch、Logstash、Filebeat、Kibana、Kafka五个组件组合,主要用于大型
- Filebeat从数据层(Nginx、Tomcat、APP)采集数据,然后将数据交给Kafka集群缓存,Logstash从Kafka中消费数据进行简单处理,然后将数据存储到Elasticsearch,然后交给Kibana或Grafana展示。
- 数据流向:源数据层(nginx、tomcat、app)–>数据采集层(Filebeat)–>数据缓存层(Kafka)–>数据处理层(Logstash)–>数据存储层(Elasticsearch)
官网
ElasticStack
ElasticStack首页:https://www.elastic.co/
ElasticStack文档:https://www.elastic.co/docs
ElasticStack下载:https://www.elastic.co/downloads
ELKF文档
- Elasticsearch文档:
https://www.elastic.co/guide/en/elasticsearch/reference/8.14/elasticsearch-intro.html
- Logstash文档:
https://www.elastic.co/guide/en/logstash/8.14/introduction.html
- Kibana文档:
https://www.elastic.co/guide/en/kibana/8.14/introduction.html
- Filebeat文档:
https://www.elastic.co/guide/en/beats/filebeat/8.14/filebeat-overview.html
ELKF下载
- Elasticsearch下载:
https://www.elastic.co/downloads/elasticsearch
https://www.elastic.co/downloads/past-releases#elasticsearch
- Logstash下载:
https://www.elastic.co/downloads/logstash
https://www.elastic.co/downloads/past-releases#logstash
- Kibana下载:
https://www.elastic.co/downloads/kibana
https://www.elastic.co/downloads/past-releases#kibana
- Filebeat下载:
https://www.elastic.co/downloads/beats/filebeat
https://www.elastic.co/downloads/past-releases#filebeat
端口
Elasticsearch端口
Elasticsearch部署后启动了两个端口,分别是9300和9200
- 9200:主要用于集群外部提供通讯服务的端口,提供http协议,用作数据交互。
- 9300:主要用于集群内部提供通讯服务的端口
Logstash端口
Logstash部署后启动了端口,5044、9600
- 9600:主要用于接收stdin数据使用的默认端口
- 5044:主要用于接收beats数据使用的默认端口
Kibana端口
Kibana部署后启动了一个端口,5601
- 5601:主要用于提供用户访问服务的端口
Filebeat端口
Filebeat默认端口开启一个,5044
- 5044:主要用于接收数据和配置信息的端口
原理
Elasticsearch工作原理
Elasticsearch组成
在Elasticsearch由4部分完成工作
- 节点(Node):表示运行的Elasticsearch服务
- 索引(Index):
- 分片(Shard):
- 副本分片(Replica Shard):分片(Shard)的备份数据
Elasticsearch图示
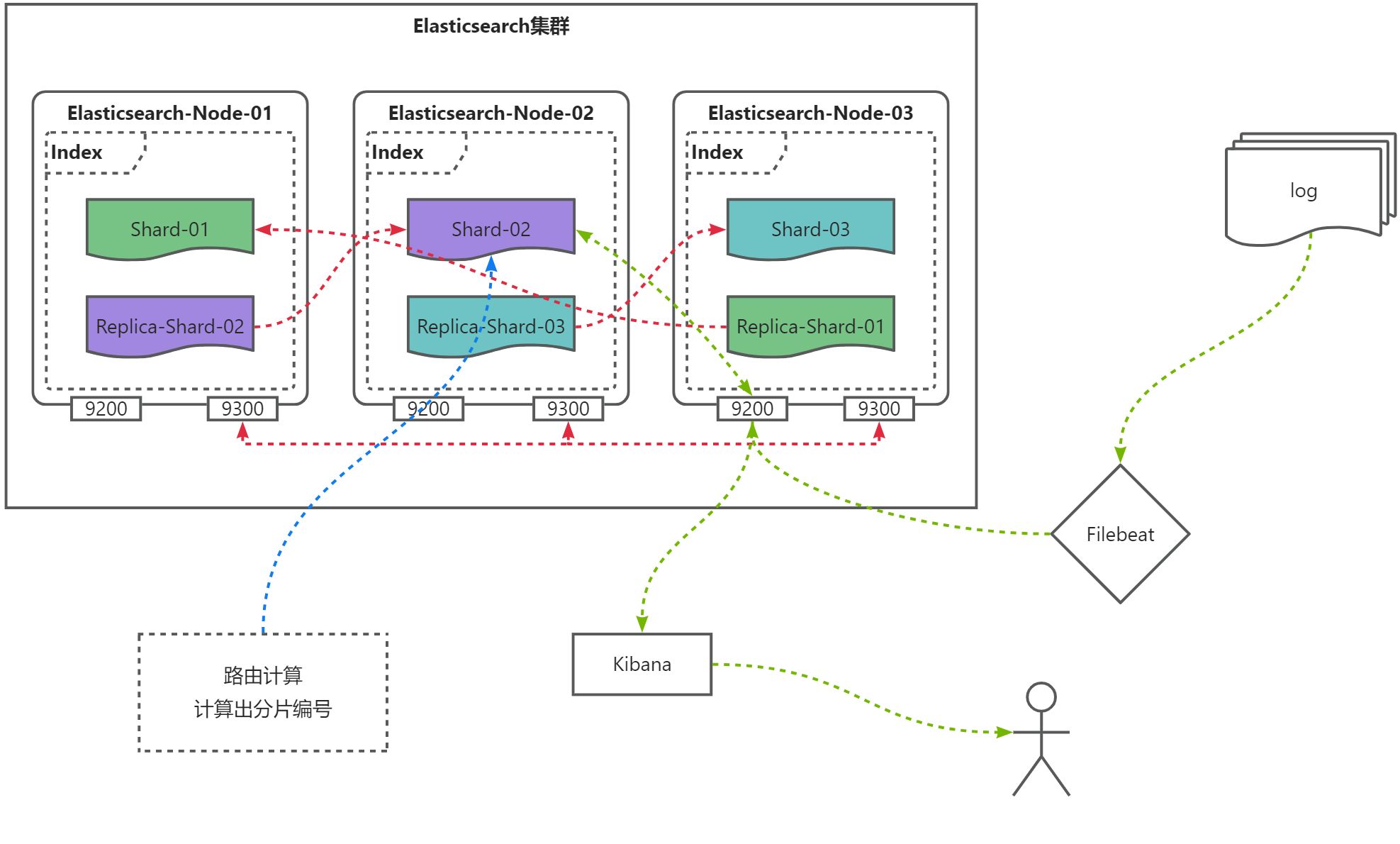
Elasticsearch原理
- Filebeat采集的数据通过9200端口发送到Elasticsearch中;
- Kibana再通过9200端口展示Elasticsearch中的数据;
- Elasticsearch内部通过9300端口通讯,
Elasticsearch集群中的分片数量分配后无法再修改,而副本分片数量可以再次修改。
Logstash工作原理
Logstash组成
Logstash有三大核心组成
- input:数据源,告诉Filebeat采集哪里的数据
- filter:过滤数据,将数据根据自定义过滤条件进行过滤
- output:目的端,告诉Filebeat数据发送给谁
Logstash图示
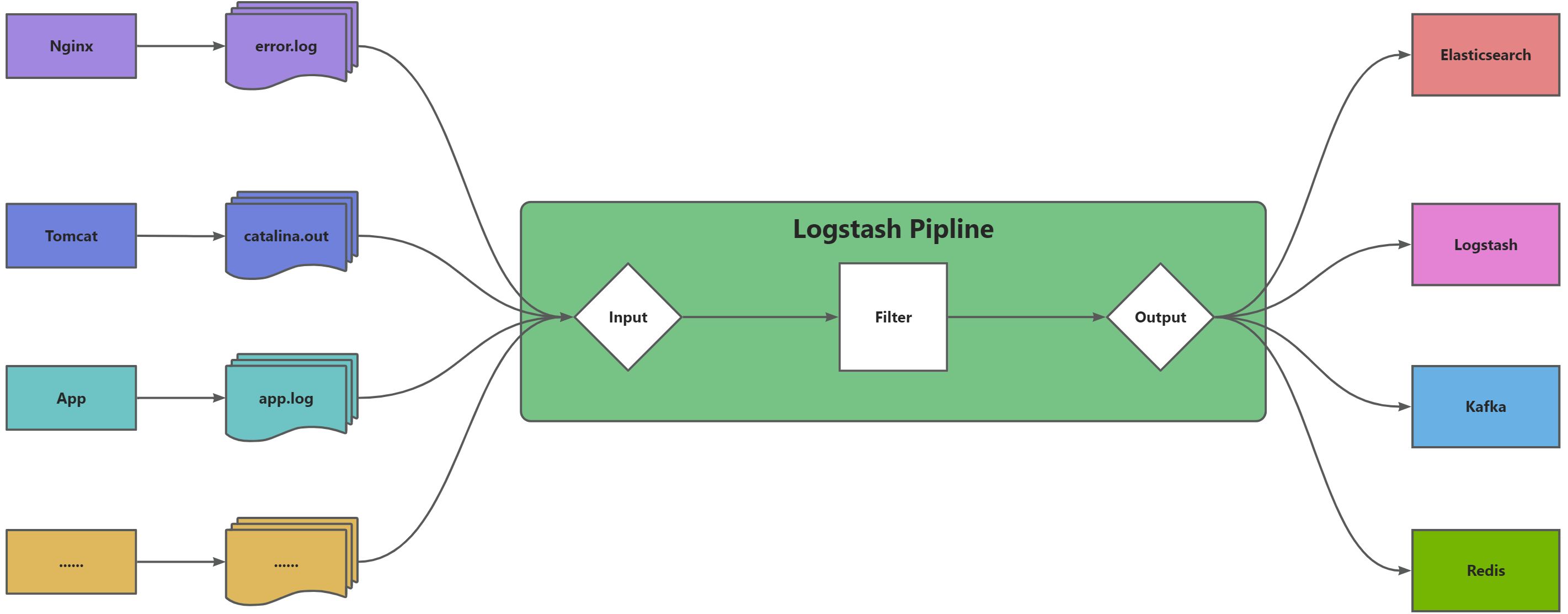
Logstash原理
- 通过Input指定要收集的日志,数据等信息所在位置;
- 通过Filter将采集的数据进行过滤;
- 通过Output指定收集的日志,数据等发送给哪个应用使用;
- 注意Logstash数据收集默认按行读取,即每一行为一个条数据;
Filebeat工作原理
Filebeat组成
Filebeat有两大核心组成
- input:数据源,告诉Filebeat采集哪里的数据
- output:目的端,告诉Filebeat数据发送给谁
Filebeat图示

Filebeat原理
- 通过Input指定要收集的日志,数据等信息所在位置;
- 通过Output指定收集的日志,数据等发送给哪个应用使用;
- 注意Filebeat数据收集默认按行读取,即每一行为一个条数据;
















 2669
2669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









