






文章目录
线程
1. 多线程-threading
- 使用threading模块
import threading
import time
def saySorry():
print("亲爱的,我错了")
time.sleep(1)
if __name__ == '__main__':
for i in range(10):
t = threading.Thread(target=saySorry)
t.start()
- 这个是一起执行的
- 创建好的线程,需要
start方法来启动
- 主线程会等待所有的子线程结束后才会结束
import threading
from time import sleep, ctime
def sing():
for i in range(3):
print("正在唱歌..%d" % i)
sleep(1)
def dance():
for i in range(3):
print("正在跳舞..%d" % i)
sleep(1)
if __name__ == '__main__':
print("--开始---%s" % ctime())
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
print("--结束--%s" % ctime()) # 执行完毕之后就卡在最后,等待子线程完成任务
- 查看线程数量
import threading
import os
from time import sleep, ctime
def sing():
for i in range(3):
print("正在唱歌..%d" % i)
print("1. pid=%s" % os.getpid())
sleep(1)
def dance():
for i in range(3):
print("正在跳舞..%d" % i)
print("2. pid=%s" % os.getpid())
sleep(1)
if __name__ == '__main__':
print("k开始 %s" % ctime())
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
print("3. pid=%s" % os.getpid())
while True:
length = len(threading.enumerate())
print("当前运行的线程数=%s" % length)
if length <= 1 :
break
sleep(0.5)
- 会打印出线程数目,另外都是同一进程
2. threading注意点
2.1 线程执行代码的封装
为了让每个线程的封装性更加完美,所以使用threading模块时,往往继承threading.Thread就可以了,然后重写初始化以及run方法
import threading
import time
class Mythread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm" + self.name + "@" + str(i) # self.name属性中保存的是当前线程的名字
print(msg)
if __name__ == '__main__':
for j in range(5):
t= Mythread()
t.start() # 线程运行顺序不固定,根据计算机调度算法
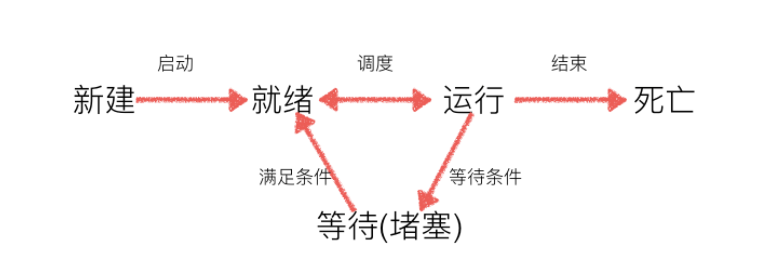
2.2 线程的执行顺序
- 多线程程序的执行顺序是不确定的,当执行到sleep语句时,线程将被堵塞,到sleep结束后,线程进入就绪状态,等待调度
- 而线程调度会自动选择一个线程执行
- 因此线程的启动顺序,
run函数中每次循环的执行顺序都不能确定
3. 多线程共享全局变量
3.1 修改共享全局变量顺序会乱
from threading import Thread
g_num = 100
def work1():
global g_num
for i in range(100000000):
g_num += 1
print("in work1,g_num = %d" % g_num)
def work2():
global g_num
print("in work2,g_num = %d" % g_num)
print("线程创建之前g_num = %d" % g_num)
t1 = Thread(target=work1)
t1.start()
# t1.join() # 注意这里等或者不等,终端中打印出来的值会不同
t2 = Thread(target=work2)
t2.start()
# 不等待,打印出来的值会乱
3.2列表可以当做实参传递到线程中
from threading import Thread
import time
def work1(nums):
nums.append(44)
print("in work1,nums=%s" % nums)
def work2(nums):
# 延时一会保证t1线程中的事情做完
time.sleep(1)
print("in work2,nums=%s" % nums)
if __name__ == '__main__':
g_nums = [11, 22, 33]
t1 = Thread(target=work1, args=(g_nums,))
t1.start()
t2 = Thread(target=work2, args=(g_nums,))
t2.start()
3.3 总结
- 一个进程中的所有线程共享全局变量,能够再不适用其他方式的前提下完成多线程之间的通信
- 缺点是线程对全局变量随意修改,可能造成多线程之间对全局变量的混乱(即线程非安全)
4. 进程与线程对比
4.1 定义不同
- 进程是系统进行资源分配和调度的一个独立单元
- 线程是进程的一个实体,是CPU调度和分配的基本单元
- 它是比进程更小的能独立运行的基本单位
- 线程自己基本不拥有系统资源,只拥有一点再运行中必不可少的资源(程序计数器,一组寄存器和栈)
- 但是它可与同属于一个进程的其他的线程共享进程所有用的全部资源
4.2 区别
- 一个程序至少有一个进程,一个进程至少有一个线程
- 线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性更高
- 进程再执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
- 线程不能独立执行,必须依存在线程中
4.3 优缺点
线程和进程再使用上各有优缺点:
- 线程执行开销小,但不利于资源的管理和保护
- 进程恰好相反
5. 同步
5.1 线程不安全
假设两个线程t1和t2都要多 num=0 进行增1运算,t1和t2都各对 num 修改10次, num 的最终的结果应该为20,但多线程访问,有可能出现下面的情况
- 在num=0时候,t1取得num=0.
- 此时系统把t1调度设置为“sleeping”状态,把t2转换为“running状态”
- t2也获得num=0,然后t2对得到的值进行+1并赋值给num,使得num=1
- 然后系统又把t2调度为“sleeping”,把t1转为“running”
- 线程1又把它得到的0加1就赋值给num
这样,明明t1和t2都完成了1次加1的工作,但结果仍然是t1=1
from threading import Thread
import time
g_num = 0
def add1():
global g_num
for i in range(1000000):
g_num += 1
print("add1=%s" % g_num)
def add2():
global g_num
for i in range(1000000):
g_num += 1
print("add2=%s" % g_num)
if __name__ == '__main__':
p1 = Thread(target=add1)
p1.start()
# p1.join() # 如果不等待的话,这个加法就会出问题
p2 = Thread(target=add2)
p2.start()
# p2.join()
print("最终累加的结果=%.2f" % g_num)
输出结果
最终累加的结果=258083.00
add1=1238866
add2=1418797
- 没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预测,这种现象称为“线程不安全”
5.2 什么是同步
- 同步是协同步调的概念,不是一起动作。
- 例如线程、进程同步,可以理解为进程A/B一块配合
- A执行到一定成都时要依靠B的某个结果
- 于是停下来,示意B运行
- B依次执行,再将结果给A
- A继续执行
5.3 解决同步思路
- 系统调用t1,然后获取到num的值为0,此时上一把锁,即不允许其他线程操作num
- 对num的值+1
- 解锁,此时num=1,其他线程就可以使用num了
- 同理其他线程在对num进行修改时,都要先上锁,处理完之后再解锁
- 在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性
6. 互斥锁
当多个线程几乎同时修改某个共享数据的时候,需要进行同步控制
- 线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制就是引入互斥锁
threading模块中定义了Lock类,可以方便地处理锁定:
# 创建锁
mutex = threading.Lock()
# 锁定
mutex.acquire([blocking])
# 释放
mutex.release
- 锁定方法
acquire有一个blocking参数- 如果设置
blocking=True,则当前线程堵塞,直到获取这个锁为止(默认) - 如果设置
blocking=False,则当前线程不会堵塞
- 如果设置
from threading import Thread, Lock
import time
g_num = 0
def add1():
global g_num
for i in range(1000000):
# True代表堵塞,即如果这个锁再上锁之前已经被上锁了,那么这个线程会在这里一直等待到解锁为止
# False代表非堵塞,即不管本次能否成功上锁,都不会卡再这,而是继续执行下面的代码
mutexFlag = mutex.acquire(True)
if mutexFlag:
g_num += 1
mutex.release()
print("add1,g_num=%s" % g_num)
def add2():
global g_num
for i in range(1000000):
# True代表堵塞,即如果这个锁再上锁之前已经被上锁了,那么这个线程会在这里一直等待到解锁为止
# False代表非堵塞,即不管本次能否成功上锁,都不会卡再这,而是继续执行下面的代码
mutexFlag = mutex.acquire(False) # add1对g_num是锁定状态,这里上锁是非堵塞方式,那么它将跳过下面的代码
if mutexFlag: # 这里需要判断是否上锁,如果选择非堵塞方式,那么可能出现没有锁可以释放
g_num += 1
mutex.release()
print("add2,g_num=%s" % g_num)
if __name__ == '__main__':
# 创建一把互斥锁,这把锁默认是未上锁状态
mutex = Lock()
p1 = Thread(target=add1)
p1.start()
p2 = Thread(target=add2)
p2.start()
print("g_num=%d" % g_num)
总结
- 好处
- 确保某段关键代码只能由一个线程从头到尾完整地执行
- 坏处
- 阻止了多线程并发的执行,降低了效率
- 由于可以存在多个锁,不同线程持有不同锁的,并师徒获得对方持有的锁,可能会造成死锁
7. 多线程-非共享数据
import threading
import time
class MyThead(threading.Thread):
def __init__(self, num, sleepTime):
super().__init__()
self.num = num
self.sleepTime = sleepTime
def run(self):
self.num += 1
time.sleep(self.sleepTime)
print("线程%s,num=%d" % (self.name, self.num))
if __name__ == '__main__':
mutex = threading.Lock()
t1 = MyThead(100, 5)
t1.start()
t2 = MyThead(200, 1)
t2.start()
- 多线程开发中,全局变量是多个线程都共享的数据,而局部变量等是各自线程的,非共享
8. 死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且等待对方的资源,就会造成死锁
import threading
import time
class MyThead1(threading.Thread):
def run(self):
if mutexA.acquire(): # 0对A进行上锁
print(self.name + "---do1---up----")
time.sleep(1)
if mutexB.acquire(): # 1这里想对B进行上锁,但是B在MyThead2中已经被锁上了,被堵塞了
print(self.name + "---do1---down----")
mutexB.release()
mutexA.release()
class MyThead2(threading.Thread):
def run(self):
if mutexB.acquire(): # 0对B进行上锁
print(self.name + "---do2---up----")
time.sleep(1)
if mutexA.acquire(): # 1这里想对A上锁,但是A在MyThead1中已经被锁上了,被堵塞
print(self.name + "---do2---down----")
mutexA.release()
mutexB.release()
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == '__main__':
t1 = MyThead1()
t2 = MyThead2()
t1.start()
# t1.join()
t2.start()
- 程序设计要尽量避免死锁
- 添加超时时间等
9. 同步应用
from threading import Thread, Lock
from time import sleep
class Task1(Thread):
def run(self):
# while True:
if lock1.acquire(): # 对lock1上锁
print("Task1")
sleep(0.5)
lock2.release() # 释放lock2
class Task2(Thread):
def run(self):
# while True:
if lock2.acquire(): # 对lock2上锁
print("Task2")
sleep(0.5)
lock3.release()
class Task3(Thread):
def run(self):
# while True:
if lock3.acquire():
print("Task3")
sleep(0.5)
lock1.release()
if __name__ == '__main__':
lock1 = Lock()
# 创建另外一把锁,并且锁上
lock2 = Lock()
lock2.acquire()
# 创建另外一把锁,并且锁上
lock3 = Lock()
lock3.acquire()
t1 = Task1()
t2 = Task2()
t3 = Task3()
t1.start()
t2.start()
t3.start()
# 只有 Task1 可以先运行
# 因此先运行Task1,释放Lock2后可以运行Lock2,依次类推
# 当while True时候可以持续不断地123运行
10. 生产者与消费者模式
10.1 队列
先进先出
10.2 栈
先进后出

Python的Queue模块提供了同步的、线程安全的队列类,包括:
- FIFO(先入先出)队列Queue
- LIFO(后入先出)队列LifoQueue
- 优先级队列PriorityQueue
这些队列都实现了锁物语(即要么不做,要么做完),能够在多线程中直接使用
-
用FIFO队列实现上述生产者与消费者问题的代码如下:
import threading import time from queue import Queue class Producer(threading.Thread): def run(self): global queue count = 0 while True: # 持续不断运行 if queue.qsize() < 1000: # 如果队列中少于1000,则生产数据 for i in range(100): # 一个线程一次生产100个 count = count + 1 msg = self.name + "生成产品" + str(count) queue.put(msg) print(msg) time.sleep(0.5) class Consumer(threading.Thread): def run(self): global queue while True: # 持续不断地运行 if queue.qsize() > 100: # 如果队列中大于100,则消费数据 for i in range(3): # 一个线程一次消费3个 msg = self.name + '消费了' + queue.get() print(msg) time.sleep(1) if __name__ == '__main__': queue = Queue() for i in range(500): queue.put("初始产品" + str(i)) # 0先生成初始产品500个 for i in range(2): p = Producer() p.start() # 这里会多出一个执行箭头,不需要等待那个箭头执行完 for i in range(5): c = Consumer() c.start()10.3 Queue的说明
- 添加数据到多列中用
put() - 从多列中取数据,使用
get() - 判断队列中是否有数据,使用
qsize()方法
10.4 生产者消费者模式说明
-
为什么使用生产者与消费者模式
- 在线程世界中,生产者就是生产数据的线程
- 消费者就是消费数据的线程
在多线程开发中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者必须等待消费者处理完,才能继续生产数据;
若消费者的处理能力大于生产者,那么消费者就必须等待生产者
-
什么是生产者与消费者模式
- 生产者与消费者模式通过一个容器来解决生产者和消费者的强耦合问题
- 生产者与消费者彼此之间不直接通讯,而通过堵塞队列进行通讯
所以生产者生产完数据之后,不用等待消费者处理,直接扔给阻塞队列;
消费者不找生产者要数据,而是直接从阻塞队列里取
阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力
这个阻塞队列就是用来给生产者和消费者解耦的,大多数设计模式都会找一个第三者出来进行解耦
- 添加数据到多列中用
11. ThreadLocal
11.1 使用函数传参的方法
使用局部变量时候,在函数调用的时候,传递起来很麻烦
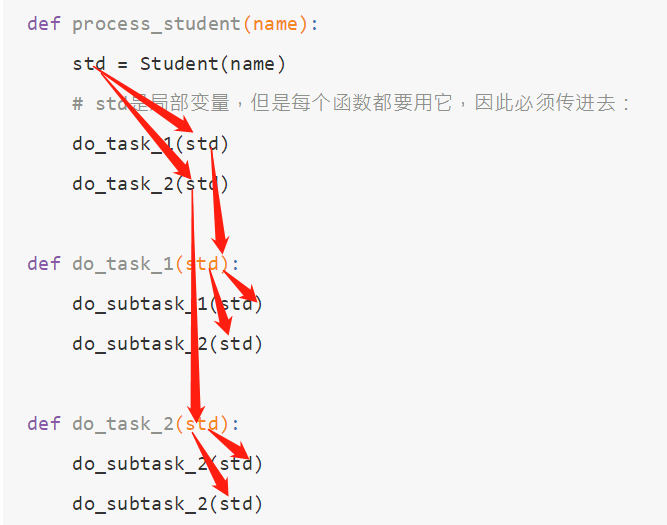
- 每个函数一层一层调用这么传参,比较麻烦
- 用全局变量也不行,因为每个线程处理不同的Student对象,不能共享
11.2 使用全局字典的方法
如果用一个全局dict存放所有的Student对象,然后以thread自身作为key获得线程对应的Student对象:
import threading
global_dict = {}
def std_thread(name):
std = Student(name)
# 把std放到全局变量global_dict中
global_dict[threading.current_thread()] = std
do_task_1()
do_task_2()
def do_task_1():
# 不传入std,而是根据当前线程查找
std = global_dict[threading.current_thread()]
...
def do_task_2():
std = global_dict[threading.current_thread()]
...
上述方式消除了std对象再每层函数中的传递问题,但是每个函数获取std的方式比较LOW
11.3 使用ThreadLocak方法
import threading
# 创建全局ThreadLocal对象
local_school = threading.local()
def process_thread(name):
# 绑定ThreadLocal的student
local_school.student = name # 这个全局变量比较特殊,根据线程来设置对应的属性
process_student()
def process_student():
std = local_school.student # 这个全局变量比较特殊,会根据线程来获取对应的属性
print("Hello, %s(in%s)" % (std, threading.current_thread().name))
if __name__ == '__main__':
t1 = threading.Thread(target=process_thread, args=("小王",), name="Thead-A")
t2 = threading.Thread(target=process_thread, args=("老王",), name="Thead-B")
t1.start()
t2.start()
t1.join()
t2.join()
- 可以理解为全局变量
local_school是一个公共存储柜,不同的线程根据自己的名字各自取自己的东西而互不影响. - 而公共存储柜可以分区存储不同的属性
12 异步
from multiprocessing import Pool
import time
import os
def test():
print("---进程中的进程--pid=%s,ppid=%d" % (os.getpid(), os.getppid()))
for i in range(3):
print("---%d---" % i)
time.sleep(1)
return 'hahaha'
def test2(args):
print("回调函数执行线程pid=%s" % os.getpid())
print("回调函数参数args=%s" % args)
pool = Pool(3)
pool.apply_async(func=test, callback=test2)
while True:
time.sleep(1)
print("主线程-pid=%d" % os.getpid())
结果
---进程中的进程--pid=31017,ppid=31016
---0---
主线程-pid=31016
---1---
主线程-pid=31016
---2---
主线程-pid=31016
回调函数执行线程pid=31016
回调函数参数args=hahaha
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程-pid=31016
主线程正干着自己的事情,不知道什么时候执行完,当子线程test1执行完毕之后,主线程被调去执行test2,然后再回来做自己的事情这叫做异步
- 异步就是我要把书放到书架上,不确定什么时候还书,我不会一直等着别人还书(什么也不做,同步),我继续做自己的事情,等别人敲门通知我一下,停下现在任务,我取到书,然后放上去.放完接着干自己的事情
- 僵尸进程 - 子进程结束而父进程没有结束
- 孤儿进程 - 父进程结束而子进程没有结束
13 GIL
- 使用C语言解决线程GIL问题
- 使用进程来解决GIL问题,但是通信费劲














 2322
2322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









