







 本文通过实例展示了如何使用Python的requests库,模拟浏览器访问,成功爬取亚马逊商品页面。首先复制商品URL,然后利用requests.get()方法获取页面信息。在遇到访问限制时,通过设置User-Agent为常见浏览器标识,成功绕过限制并获取到页面内容。
本文通过实例展示了如何使用Python的requests库,模拟浏览器访问,成功爬取亚马逊商品页面。首先复制商品URL,然后利用requests.get()方法获取页面信息。在遇到访问限制时,通过设置User-Agent为常见浏览器标识,成功绕过限制并获取到页面内容。
1.打开亚马逊官网,随机浏览一商品详细页,复制URL。
2.用requests.get()方法获取网页相关信息
import requests
r = requests.get("https://www.amazon.cn/dp/B07TLJS1HH/ref=s9_acsd_hps_bw_c2_x_0_i?pf_rd_m=A1U5RCOVU0NYF2&pf_rd_s=merchandised-search-2&pf_rd_r=F0G8E7GQ2HTW6CHPF25Z&pf_rd_t=101&pf_rd_p=90054d28-bb64-4490-8abc-8f710c113be9&pf_rd_i=116169071")
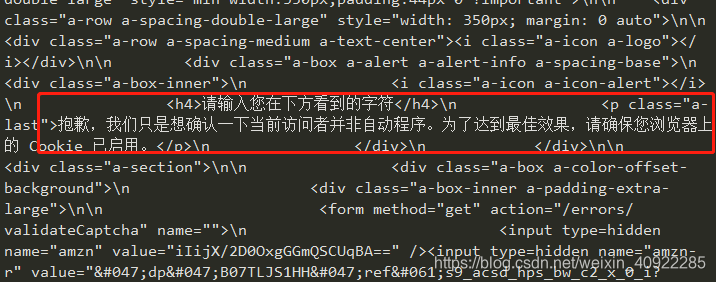
r.status_code #打印结果为:503,说明访问出现错误。
r.encoding #查看它的编码,打印结果:ISO-8859-1,
r.encoding = r.apparent_encoding #把编码改成它可执行的编码
r.text #查看返回的文本打印文本结果显示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









