






要深入理解大语言模型(LLM)的内部工作机制,不妨先从GPT-1模型开始。
我们主要从发展历程、意义、论文中的架构图来展开。
一、发展历程
2017年,Google推出了Transformer模型,这一架构因其在性能上的显著优势迅速吸引了OpenAI团队的注意。
《Attention Is All You Need》
https://arxiv.org/abs/1706.03762

OpenAI随后将研发重点转移到Transformer架构,并在2018年发布了GPT-1模型。
GPT(Generative Pre-training)生成式预训练模型,采用了仅有解码器的Transformer模型,专注于预测下一个Token。
GPT采用了transformer的Decoder作为框架,并采用了两阶段的训练方式。
- 首先,在大量的无标记数据集中,进行生成式训练(Generative Pre-training);
- 然后,在在特定任务进行微调(fine-tuning)。
https://openai.com/index/language-unsupervised/
二、GPT-1的意义
首次引入了基于 Transformer架构 的 生成预训练(Generative Pre-training) 模型。并证明了GPT这套工作机制是可用且有效的。
2.1、 Transformer 架构
当时问题:传统的循环神经网络(RNN)和长短期记忆网络(LSTM)在处理长序列数据时存在效率低下的问题,特别是在并行计算和长距离依赖处理方面。
Transformer 架构引入了基于注意力机制的完全并行计算方法,摒弃了循环结构,解决了以下问题:
并行计算
Transformer 架构允许在训练过程中并行处理序列数据,大大提高了训练速度。
长距离依赖
通过自注意力机制(Self-Attention),Transformer 能够有效捕捉序列中远距离的依赖关系,而不依赖于序列的顺序。
2.2、 生成预训练(Generative Pre-training)
面临问题:深度学习模型需要大量标注数据进行训练,而获取高质量的标注数据通常耗时费力且昂贵。
生成预训练(Generative Pre-training)利用大量无标注文本数据进行自监督学习,解决了以下问题:
数据稀缺
通过预训练,模型可以在大量无标注数据上学习丰富的语言表示,提高了对语言结构和语义的理解。
下游任务适应性
预训练模型可以通过微调(Fine-tuning)适应各种下游任务(如文本分类、问答系统等),显著减少了对标注数据的需求,并提升了任务性能。
2.3、 小结
通过将 Transformer 架构和生成预训练结合起来,GPT-1 实现了以下突破:
高效的训练:Transformer 架构大幅提高了训练速度和效率。
广泛的适应性:生成预训练使得模型能够在无标注数据上学习到丰富的语言知识,并且在少量标注数据的条件下,通过微调即可适应多种任务。
这些创新共同推动了自然语言处理领域的发展,使得 GPT-1 及其后续版本成为了强大的语言模型工具。
三、 GPT-1的架构
架构如下图,来自论文:
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
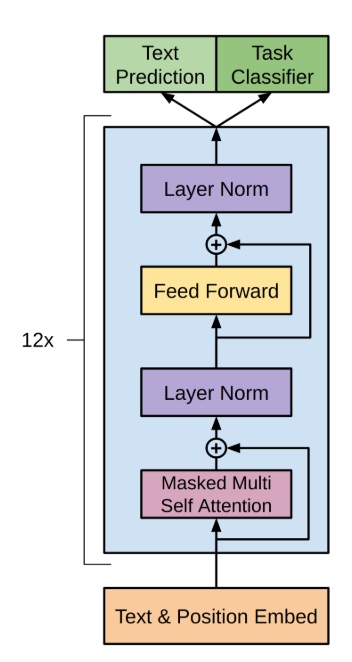
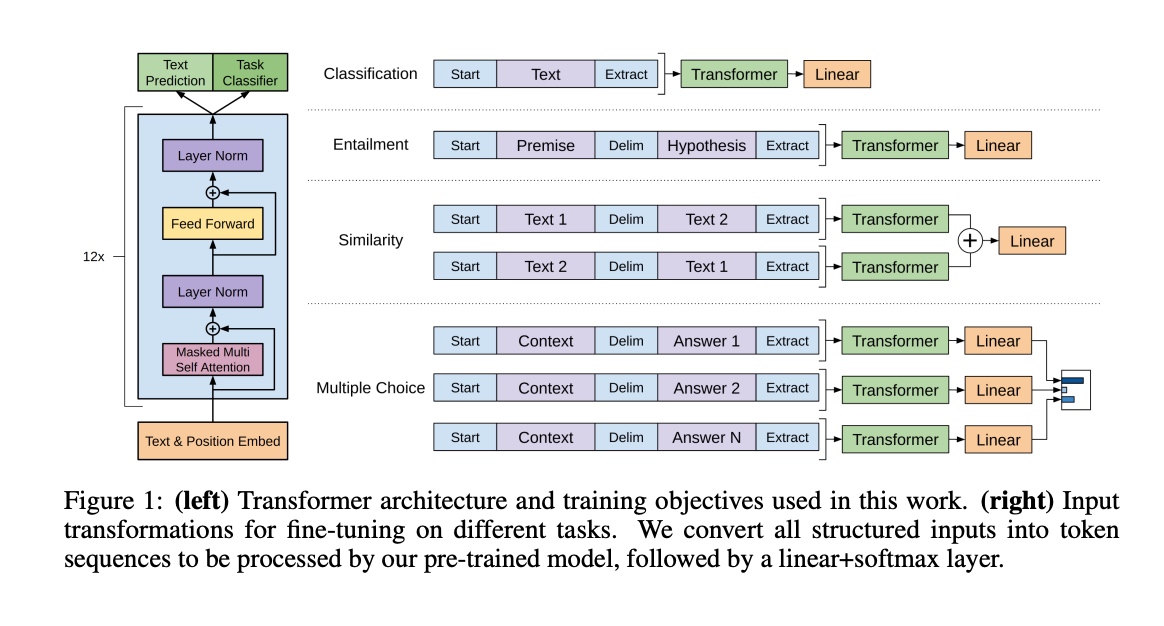
核心部分由12层Transformer堆叠组成,输入在下面,输出在上面。
读书时,你可能会反复读同一段话,以加深理解。模型有12层,每层都进行类似的处理过程,多层处理可以让模型更深刻地理解和生成语言。
3.1、 输入 Text & Position Embedding:
输入文本及其位置信息被嵌入成固定维度的向量,作为Transformer的输入。
预训练时,位置向量采用随机初始化,并在训练中进行更新;
3.2、 输出 Text Prediction和Task Classifier
最终输出用于文本预测(Text Prediction)和任务分类(Task Classifier)。
无监督训练完毕后,并不能直接用于下游任务,需要在具体任务的标注数据集上进行微调。
3.3、 Masked Multi-Head Self-Attention:
用于捕捉输入序列中各个位置之间的依赖关系,同时通过掩码机制确保模型只关注当前位置及其之前的位置。
想象你在读一段话时,会关注不同单词之间的关系。比如,你在读“猫追老鼠”时,你的大脑会把“猫”和“老鼠”联系起来。
自注意力机制就像是大脑在一瞬间关注所有单词,并找出它们之间的重要关系。
掩码机制确保模型只关注前面和当前的单词,不看后面的单词,类似于读到当前单词时不预知未来。
3.4、 Layer Norm:
层归一化,用于稳定和加速训练。
比喻
想象一下你正在一个小组讨论中,每个人都有机会发言,但有些人可能说得特别多,有些人可能说得特别少。如果你是小组的主持人,为了让讨论更加有序和高效,你会希望每个人的发言时间大致相同。
Layer Norm在神经网络中就像这个主持人,它确保每层神经网络中的所有输入信号在同一水平上,这样可以避免某些信号过强或过弱,导致网络训练不稳定。
具体功能
在神经网络中,输入数据经过不同层的处理后,数据的分布可能会发生很大变化。Layer Norm的功能就是在每一层之后,对数据进行重新规范化,使得数据的分布更加稳定。这种规范化主要通过以下步骤实现:
- 计算均值和方差:Layer Norm会计算每一层输入数据的均值和方差。
- 规范化数据:将每个输入数据减去均值,再除以方差,得到一个规范化的数据。这一步骤可以使得数据的分布更加集中,不会有过大的波动。
- 缩放和平移:最后,Layer Norm会对规范化后的数据进行线性变换(缩放和平移),以确保它们适应后续的网络层。
通俗来说,Layer Norm就像是一个“调节器”,确保每层网络的输入数据都在合理范围内,从而使得整个模型的训练过程更加平稳和高效。
3.5、 Feed Forward:
Feed Forward模块的主要作用是在Masked Multi-Head Self-Attention模块之后,对数据进行进一步的非线性变换和处理,以捕捉更复杂的特征和模式。具体来说:
进一步处理特征:
- 在自注意力机制之后,模型已经关注到了输入序列中的重要关系,但这些关系仍然是线性的,缺乏复杂的特征。
- Feed Forward模块通过非线性激活函数(如ReLU),引入非线性变换,能够捕捉和表示更复杂的特征。
提高模型表达能力:
- 前馈神经网络可以看作是一个小型的MLP(多层感知器),它能在局部范围内对数据进行复杂的处理。
- 这种处理可以增强模型的表达能力,使得模型不仅能够理解简单的关系,还能处理复杂的模式。
Feed Forward模块是在Masked Multi-Head Self-Attention模块之后的一个关键步骤。它基于自注意力机制发现的重点信息,通过进一步的非线性变换和处理,帮助模型捕捉更复杂的特征和模式,从而提高整体模型的表达能力和性能。
3.6、 整个过程
可以用一个通俗的类比来理解整个过程。
收集信息(Masked Multi-Head Self-Attention):
想象你在阅读一本书,你会根据上下文来理解每个单词的意义,就像注意力机制关注每个单词在整个句子中的关系。
整理信息(Layer Norm):
你将这些信息归纳整理,使其逻辑清晰有序,就像层归一化确保数据分布稳定。
深入分析(Feed Forward):
在理解了每个单词的关系和逻辑后,你进一步对这些信息进行深度思考和分析,得出更深层次的见解。这就是前馈神经网络的作用,它在已有的关系基础上,进行更深层次的处理和变换。
四、微调架构
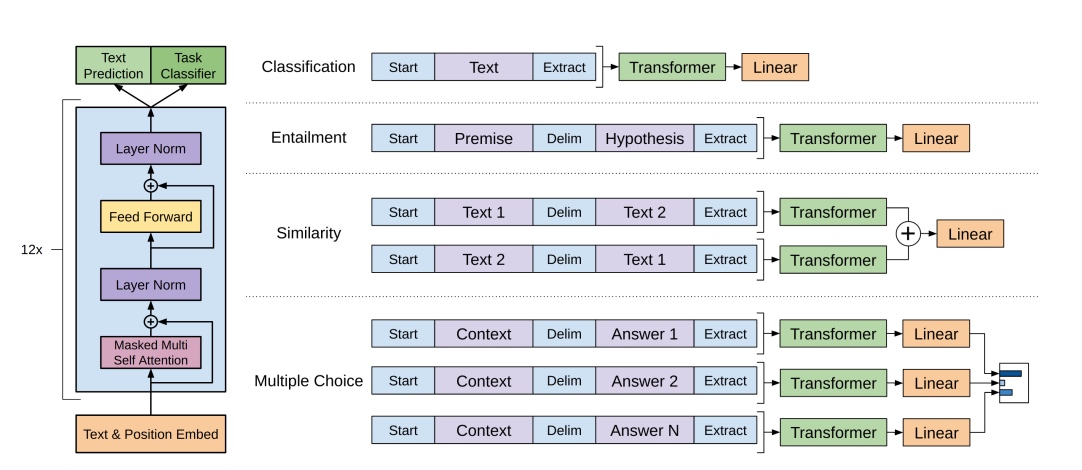
上图右侧展示了模型如何处理四种不同类型的任务(微调):分类(Classification)、蕴含关系(Entailment)、相似性(Similarity)和多项选择(Multiple Choice)。
4.1、分类任务(Classification)
可以看到,有两个特殊符号(Start和Extract)通过Transformer后,添加了一个线性层。
4.2、蕴含关系任务(Entailment)
蕴含理解:给一段话,提出一个假设,看看假设是否成立。
将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开
两端加上起始和终止token
再依次通过Transformer和全连接得到预测结果;
4.3、相似性任务(Similarity)
断两段文字是不是相似。相似是一个对称关系,A和B相似,那么B和A也是相似的
所以有两种输入方式:即有Text1+分隔符+Text2,也有Text2+分隔符+Text1;
两个序列分别经过Transformer后,各自得到输出的向量;
我们把它按元素加到一起,然后送给一个线性层。这也是一个二分类问题。
4.4、多项选择任务(Multiple Choice)
多个序列,每个序列都由相同的问题Context和不同的Answer构成。
如果有N个答案,就构造N个序列;
每个QA序列都各自经过Transformers和线性层,对每个答案都计算出一个标量;
最后经过softmax生成一个各个答案的概率密度分布。这是一个N分类问题。
4.5、Transformer
预训练和微调阶段的Transformer流程在结构上是相同的,但它们的目的、输入数据和具体任务有所不同。
不同之处
训练数据:
- 预训练阶段使用大量未标注的文本数据。
- 微调阶段使用特定任务的标注数据。
训练目标:
- 预训练阶段的目标是学习通用语言表示,通常使用自监督学习任务(如语言建模)。
- 微调阶段的目标是优化特定任务的表现,使用有监督学习任务(如分类、蕴含关系等)
输出层:
- 预训练阶段的输出层是一个通用的语言模型输出层,预测下一个词。
- 微调阶段的输出层根据具体任务有所不同,如分类任务的线性层和softmax层。
预训练阶段关注学习通用的语言表示,而微调阶段则关注在特定任务上的优化。
4.6 Linear层
什么是Linear层?
Linear层(线性层),也叫全连接层(Fully Connected Layer),是神经网络中的基本组成部分。
它将输入向量通过一个线性变换,输出一个新的向量。这个变换可以看作是对输入进行加权求和并加上一个偏置(Bias)。
可以把Linear层想象成一个过滤器,它根据预先设定的规则(权重和偏置)对输入数据进行处理,输出符合规则的新数据。例如:
你有一篮子水果(输入向量),你通过一个筛子(Linear层)来过滤,只留下特定大小和形状的水果(输出向量)。
任务特定的输出转换
- 分类任务(Classification):Linear层将Transformer的输出转化为类别的概率分布。例如,输入一句话后,Linear层输出该句子属于各个类别的概率。
- 蕴含关系任务(Entailment):Linear层将前提和假设的关系转化为是否能推导出的概率。
- 相似性任务(Similarity):Linear层将两个文本的特征转化为相似性得分。
- 多项选择任务(Multiple Choice):Linear层将上下文和各个答案选项的关系转化为选择正确答案的概率。
Linear层在预训练阶段隐含存在,主要用于生成下一个词的概率分布。在具体任务的微调阶段,Linear层的作用才更加明显,因为它负责将Transformer的输出特征向量转化为任务特定的结果。
架构小结
- 预训练阶段:使用大量未标注文本,通过Transformer架构进行语言建模。
- 微调阶段:在特定任务的标注数据上进行训练,通过不同的输入格式和Linear层适应特定任务。
- 统一架构:尽管任务不同,但都通过相同的Transformer架构处理,实现了高效和灵活的自然语言处理。
五、总结
GPT-1的意义在于首次引入了基于Transformer架构的生成预训练(Generative Pre-training)模型,并证明了这套工作机制的可用性和有效性。
首先,Transformer架构解决了传统模型在处理长序列数据和高效训练上的难题,通过并行计算和自注意力机制,显著提高了训练速度和捕捉长距离依赖关系的能力。
其次,生成预训练策略利用大量无标注数据进行自监督学习,极大地提升了模型对语言结构和语义的理解能力。经过微调,GPT-1能够适应各种下游任务,减少对标注数据的需求并提升任务性能。
这些创新不仅推动了自然语言处理技术的发展,也为后续版本的改进奠定了坚实基础。















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









