







问题:配置好Hbase后启动Hmaster,jps一下,发现启动起来了,再jps就Hmaster就又挂了。

定位:大概率是hbase-site.xml配置问题,配置正确一般是可以正常启动的
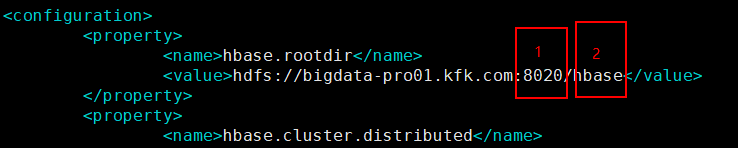
解决:
①端口号要写对,查看一下是否和主节点端口号一致
②是不是忘了写/base这个后缀了 ·······(尴尬!)
然后就能启动了:
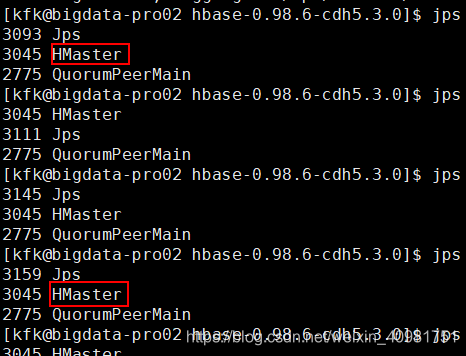
问题:配置好Hbase后启动Hmaster,jps一下,发现启动起来了,再jps就Hmaster就又挂了。
定位:大概率是hbase-site.xml配置问题,配置正确一般是可以正常启动的
解决:
①端口号要写对,查看一下是否和主节点端口号一致
②是不是忘了写/base这个后缀了 ·······(尴尬!)
然后就能启动了:











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


















 557
557





