




问题描述:
使用Spark SQL采用overwrite写法写入Hive(非分区表,),全量覆盖,因为人为原因脚本定时设置重复,SparkSql计算任务被短时间内调起两次,结果发现任务正常运行,造成写入表中数据结果存在同一张表有重复的行,数据翻倍。

从hdfs上可以看到也存在重复的的数据文件,会。有两组文件,每组大小是一样的。
hdfs dfs -ls /user/hive/warehouse/xxx.db/xxx_table问题思考:
如果存在多个任务同时往一张Hive表overwrite,因为资源等因素,也会有时间差,基本不可能两个任务同时同秒执行结束,执行的写入sql都是insert overwrite,因此数据也理论上是正常写入数据之前要删除旧的数据,覆盖才合理。猜想是可能Hive本身会有延迟,在短时间内上一个任务还未insert overwrite结束,另外一个任务也紧跟着运行insert overwrite结束,导致重复插入数据没有被覆盖。
经过查资料发现:
Spark SQL在执行SQL的overwrite的时候并没有删除旧的的数据文件(Spark SQL生成的数据文件),Spark SQL写入Hive的流程如下:
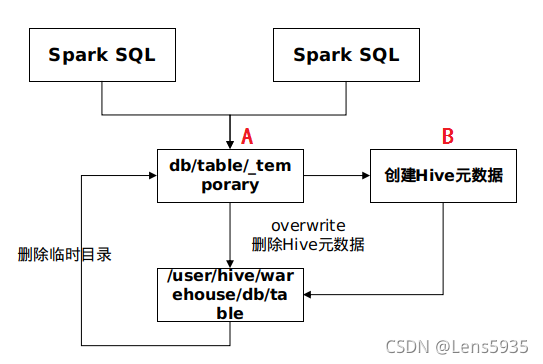
(1)Spark写入Hive会先生成一个临时的_temporary目录用于存储生成的数据文件,全部生成完毕后全部移动到输出目录,然后删除_temporary目录,最后创建H
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









