









常用的四个排序BY
- ORDER BY
- SORT BY
- DISTRIBUTE BY
- CLUSTER BY
此文只是结合官方文档和案例做一下说明下功能
数据集描述
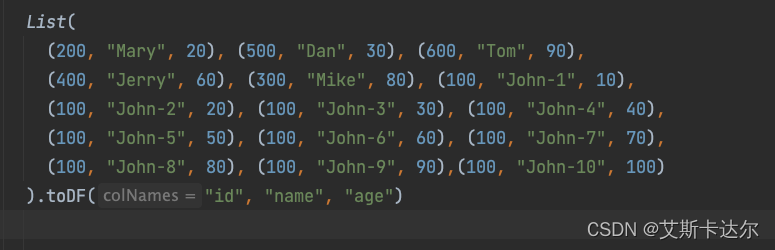
数据如上所示,并手动将分区数设定在2个,默认以 id 字段作为分区依据
原始数据分布
情况如下

相同id的数据都分到了同一个分区内
ORDER BY子句
官网说明: ORDER BY Clause - Spark 3.3.1 Documentation
简述: order by保证了输出的全局有序,通常用于返回结果数据时使用
在使用 [ ORDER BY id ] 的情况下的分布情况

可以看到数据分区数不变,并且整体以id来做升序处理的
SORT BY子句
官网说明: SORT BY Clause - Spark 3.3.1 Documentation
简述: sort by是用于在每个分区内部做排序
在使用 [ sort by age ] 的情况下的分布情况
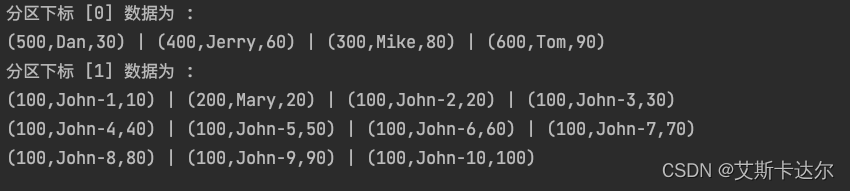
可见它与原始数据相比,并不影响分区之间的分配情况,仅仅在是每个分区内对每行进行了针对 age字段的升序处理
DISTRIBUTE BY子句
官网说明: DISTRIBUTE BY Clause - Spark 3.3.1 Documentation
简述: 通常用于根据输入的表达式来对数据进行重分区,分区内不会进行重排序
在使用 [ distribute by age ] 下的分布情况
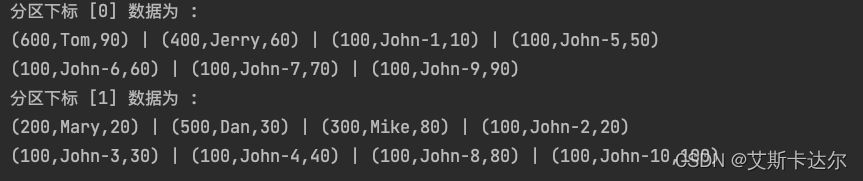
很明显的看出,相比原数据集, distribute之后的数据在分布上有了很大的不同,相同age的数据被shuffle到了一个分区内
这个子句也通常可以用于解决分区间数据倾斜的情况
比如使用 distribute by round(rand(100))
就可以让数据随机进入不同的分区来让数据分布均衡
CLUSTER BY子句
官网说明: CLUSTER BY Clause - Spark 3.3.1 Documentation
简述: 有两个操作,首先对数据进行重分区,然后对每个分区内的数据进行排序
语义上等同于 先进行 DISTRIBUTE BY 再进行 SORT BY同一个排序表达式
在使用 [ cluster by age ] 下的数据分布情况

明显看出数据针对 age字段的值进行了重分区,并且分区内都按age的升序序列来排序















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









