







Dissecting BERT Part 1: The EncoderTokenization
Introduction
BERT 中使用的编码器是一种基于注意力机制的自然语言处理(NLP)架构,它是在论文《Attention Is All You Need》中引入的。该论文介绍了一种称为 Transformer 的架构,它由两个部分组成:编码器(Encoder)和解码器(Decoder)。本文只介绍编码器部分。
自从发布 ULMFiT 以来,迁移学习迅速成为实现自然语言处理(NLP)最新成果的标准。随后,研究人员通过将 Transformer 与迁移学习相结合,取得了显著的进展。这一结合的两个标志性例子是 OpenAI 的 GPT 和 Google AI 的 BERT。
本文旨在:
- 提供对 Transformer 和 BERT 底层架构的直观理解。
- 解释 BERT 在自然语言处理任务中取得成功的基本原理 。
为了讲解这一架构,我们将采用从总体到具体的方法。我们首先将看看架构中的信息流,并深入研究论文中介绍的编码器的输入和输出。接下来,我们将研究每个编码器块,并了解如何使用多头注意力。
Information Flow
数据在架构中的流动如下:
- 嵌入层:模型将每个 token 表示为一个大小为 emb_dim 的向量。对于每个输入 token 都有一个嵌入向量,因此对于一个特定的输入序列,我们有一个维度为 (input_length)*(emb_dim) 的矩阵。
- 位置编码:然后添加位置信息(位置编码)。这个步骤返回的矩阵维度与上一步相同,为 (input_length)*(emb_dim)。
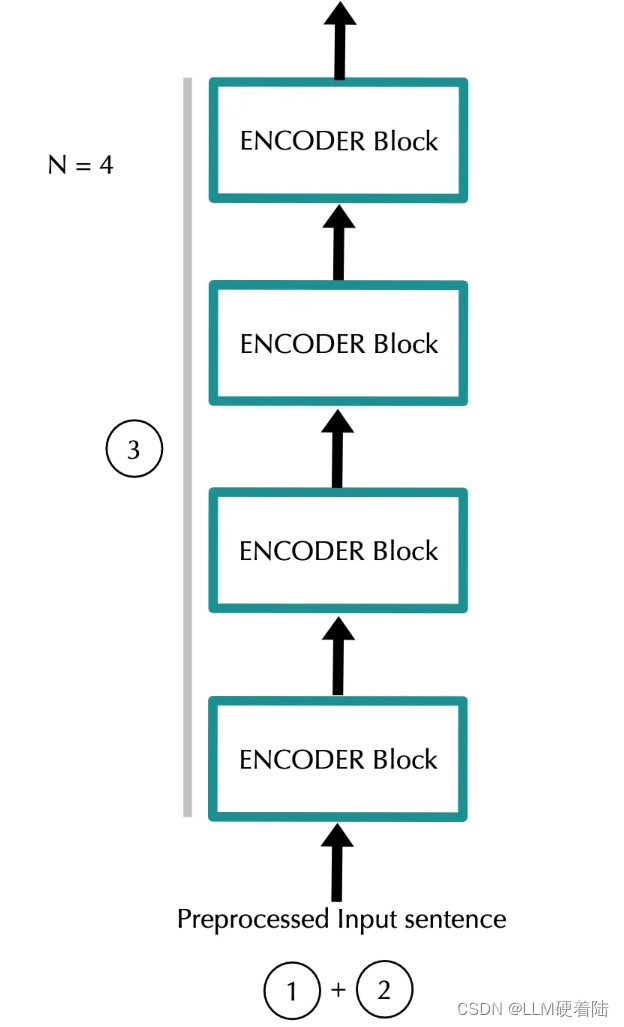
- 编码器块:数据经过 N 个编码器块。经过这些编码器块后,我们得到的矩阵维度仍然是 (input_length)*(emb_dim)。
这个过程确保输入序列中的每个 token 在经过多层处理后都包含丰富的上下文信息。
From words to vectors
Tokenization,numericalization and word embeddings
例:对于以下句子:
- “ Hello, how are you?”
step1:tokenize将语句拆分为n个单词片段
- “ Hello, how are you?” → [“Hello”, “,” , “how”, “are”, “you”, “?”]
step2:numericalization 将每个字符映射到词汇表中的唯一整数注意:为了保持输入向量长度一致,使用<pad> token做填充
- [“<pad>”, “<pad>”, “<pad>”, “Hello”, “, “, “how”, “are”, “you”, “?”] →[5, 5, 5, 34, 90, 15, 684, 55, 193]
step3:embedding 获取序列中每个单词的词嵌入,序列中的每个词被映射到一个 emb_dim 维的向量,该向量将在训练过程中由模型学习。可以将其视为对每个 token 进行向量查找。这些向量的元素被视为模型参数,并像其他权重一样通过反向传播进行优化。因此,对于每个token,找到对应的向量:

step4: Stacking 堆叠所有向量,得到(input_len)*(emb_dim)维的矩阵Z:

Positional Encoding
此时,我们已经有了序列的矩阵表示。然而,这些表示并没有编码单词出现在不同位置的信息。直观上,我们希望能够根据特定单词的位置修改其表示的含义。我们不想完全改变单词的表示,但希望对其进行一些修改以编码其位置。
论文中选择的方法是使用预定的(非学习的)正弦函数,在 token 嵌入中添加介于 [-1,1] 之间的数值。注意到,现在对于编码器的其余部分,单词的表示将根据其所在的位置略有不同(即使是相同的单词)。
此外,我们希望编码器能够利用一些单词在给定位置的信息,同时在同一序列中,其他单词在其他特定位置的信息。也就是说,我们希望网络能够理解相对位置,而不仅仅是绝对位置。作者选择的正弦函数使得位置可以表示为彼此的线性组合,从而允许网络学习 token 位置之间的相对关系。
这样,通过引入位置编码,我们不仅保留了每个单词的语义信息,还结合了位置信息,使得模型能够更好地理解输入序列的整体结构。
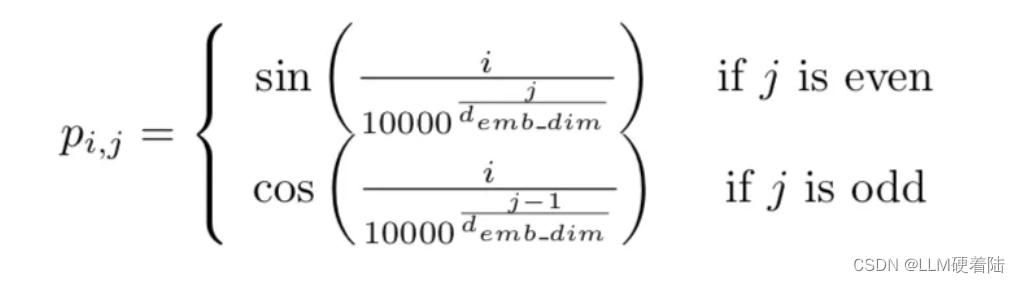
因此,对于给定句子P的,位置编码信息如下:
![]()
这种方法相对于学习位置表示具有一些特定的优势:
- 输入长度可以无限增加,因为函数可以计算任意位置的位置编码。
- 需要学习的参数更少,模型训练速度更快。
得到最终矩阵:
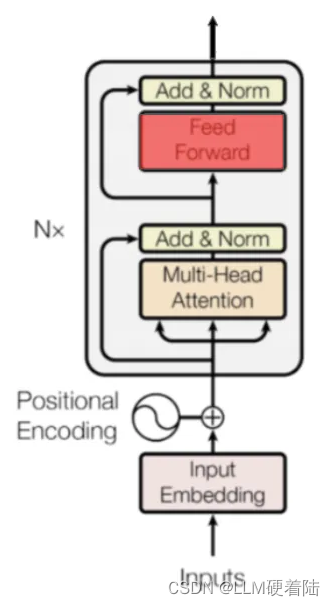
Encoder block
通过N层编码器迭代,将有助于神经网络捕获输入序列中单词之间更复杂的关系。可以将其视为迭代地构建整个输入序列的含义。
在每个编码器块中,模型都会对输入序列进行一系列操作,其中包括自注意力机制和前馈神经网络。这些操作使得模型能够在每个块中逐步提取输入序列的特征,并在整个编码器中对序列进行建模。这样,模型在经过多个编码器块后就能够捕捉到输入序列中单词之间更加复杂的关系,从而更好地理解整个序列的含义。
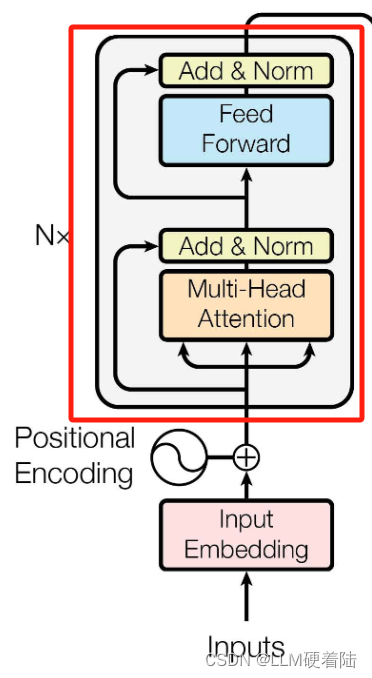
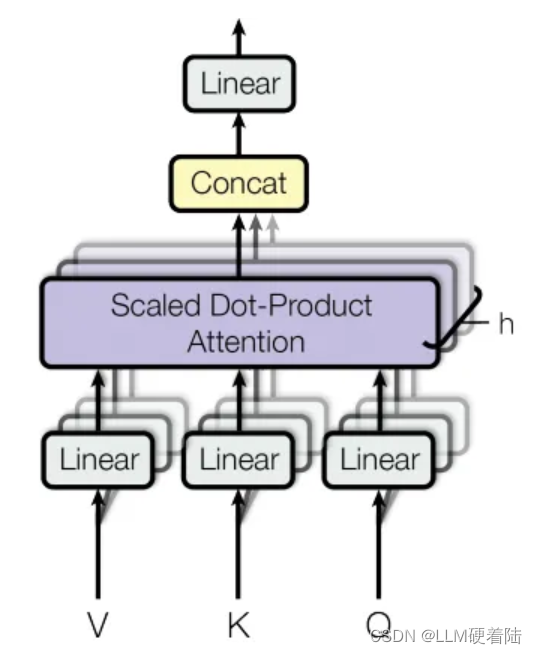
Multi-Head Attention
为了注意到不同子空间的信息,捕捉到更加丰富的特征信息。引入多头注意力机制,模型会将输入序列的查询Q、键K和值V分别投影到不同的线性子空间中,然后进行独立的注意力计算。因此Transformer使用不同的权重矩阵计算不同序列之间的注意力,然后将计算结果连接在一起。得到一个(input_len)*(h*d_v)的矩阵,其中h为注意力头数,然后乘维度为(h*d_v)*(emb_dim)的权重矩阵W⁰,得到最终维度为(input_length) * (emb_dim)的输出。
数学表示为:

在多头注意力机制中,Q(查询)、K(键)和V(值)是不同的输入矩阵的占位符。特别是在这种情况下,Q、K 和 V 将被前一步骤的输出矩阵 X 替换。
这意味着每个注意力头都会使用相同的输入序列 X 作为查询、键和值来进行注意力计算。这样可以确保每个注意力头都关注相同的输入信息,但通过不同的权重矩阵来进行计算,从而使得模型能够从不同的角度学习到输入序列的表示。
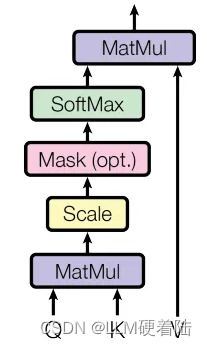
Scaled Dot-Product Attention
对于每个注意力头,都会有三个不同的投影(矩阵乘法),由以下三个矩阵给出:
为了计算每个头(head)的输出,采用输入矩阵X分别投影到上述矩阵得到:
其中,可以计算注意力权重:
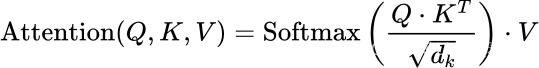
如图:
Going Deeper
关于:
和
是token在
维的空间中的不同投影,可以将这些投影的点积看作投影之间相似性的度量,对于通过
投影的每个向量,与通过
投影的向量的点积衡量了这些向量之间的相似性。如果我们将第 i个 token 和第 j个 token 分别通过
和
的投影记为
和
,它们的点积可表示为:
将与
做点乘后,将矩阵元素除以
,实现矩阵元素缩放。
下一步则是将结果进行softmax运算,得到结果:
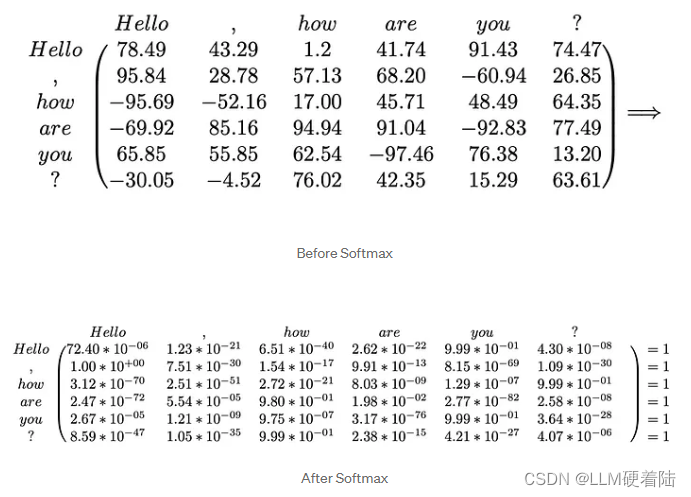
最后将结果乘得到head的输出。
Example 1
为了便于理解,假设第一行结果是[0,0,0,0,1,0],则结果如下:

在这种情况下,是通过
投影的 token 表示。
Example 2
现在假设的例子1在更一般的场景中,每行不只有一个1,而是有一个和为1的十进制正数:

结果乘得到:

因此使用不同的head捕获输入token之间的特定关系。如果这样做 h 次(总共 h 头)每个编码器块捕获 h 输入token之间不同的关系。
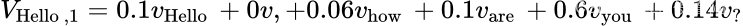
多头注意层结果的第一行,即“ Hello”在这一点上的表示,将是:
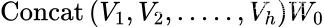
它是一个长度为的向量,给定矩阵
有维数
。在其余的行/token表示中应用相同的逻辑,得到一个维度为
的矩阵。
Position-wise Feed-Forward Network
这一步骤由以下几层组成:

从数学上讲,对于上一层输出中的每一行:
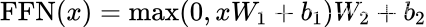
其中,
分别为
和
维的矩阵
这一层的输出为
Dropout, Add & Norm

实际上就是让每层的输入结果和输出结果相加,然后经过 LayerNorm 模块,表达如下:
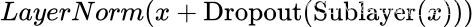

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









