






云原生边缘计算前沿技术专题
边缘计算蓬勃发展,边缘计算技术研究和产业转化进程不断融合升级。本系列专题邀请到了学界领军专家和技术爱好者,共同洞察边缘计算先进技术及趋势,分享边缘计算在前沿领域的最佳实践。
本期主题:
边缘计算前沿专题 | 云边协同的分布式机器学习
作者简介:
张晓溪,中山大学计算机学院先进网络与计算系统研究所副教授,广东省青年拔尖人才。2013年于华中科技大学电子与信息工程系取得学士学位,2017年于香港大学计算机科学系取得博士学位,2017年至2020年于美国卡耐基梅隆大学电气与计算机工程系任博士后研究员,2020年10月加入中山大学任副教授。迄今在IEEE JSAC, IEEE/ACM Transactions on Networking (ToN), ACM SIGMETRICS, IEEE INFOCOM, IEEE Transactions on Mobile Computing (TMC), AAAI, WWW, ACM MobiSys, IEEE ICNP, AISTATS, IEEE ICDCS, IEEE Transactions on Cloud Computing (TCC) 等国际高水平期刊及会议上发表论文40余篇。

▍什么是边云协同分布式机器学习
谈及云边协同的分布式机器学习,首先我们关注的是“边云协同分布式机器学习是什么”。简单而言,就是考虑将分布式机器学习的任务,部署在一个从云到边缘服务器集群,再到终端设备的多层级系统,通常也可以认为是FOG DML。
为什么要将分布式机器学习从云数据中心搬到边云协同网络中?
首先机器学习任务将享受到距离数据源更近的计算资源,避免海量数据全部传输至云引起的过大延迟及利用边缘计算的基本优势。
其次,机器学习任务的分布式部署已成趋势,因此将云边缘服务器和终端的计算和通信协同调度,可以减少依赖云资源带来的开销。
最后,数据将留在本地并且由部署方控制节点之间的通信可以提升隐私保护,在隐私和性能之间做可控的权衡。
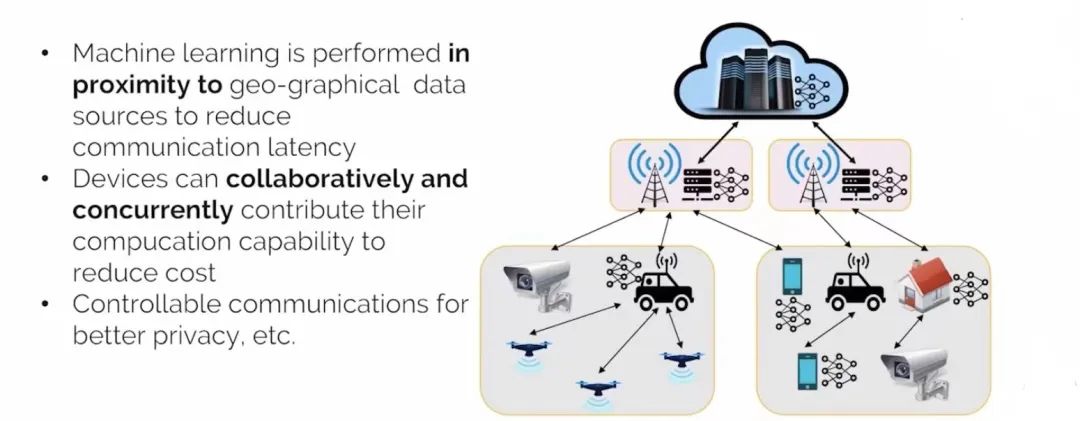
▲ 图1
然而,即使分布式机器学习受益于边云协同网络,大量挑战仍有待克服:
较传统分布式机器学习或联邦学习,边云协同网络带来更多维度的抑制性,比如分布式节点在任意时刻是否在线,资源种类和数目还有通信链路具有差异化,进而网络拓扑也可能发生变化;
边云协同记忆学习的控制变量多种多样,又因为上述的抑制性和实变性,我们的优化问题,建模和求解都非常的复杂;
最后由于机器学习的训练需要较多轮数的迭代,边云节点和通信链路多方面的性能都有可能成为训练的瓶颈,因此面临多标准的选择和优化——而这个多性能标准,将贯穿我下文介绍的全部工作。
▍DML训练的多标准性质

▲ 图2
对于模型训练,模型准确度可以说是被广泛认可的最重要的指标之一,大部分的分布式机器学习以及联邦学习,都以全局损失函数的最小化,作为面向模型准确度的优化目标,小部分的工作开始提出不同的模型准确度的目标函数,比如加不同种类的正则项,可以在最小化损失函数的基础上兼顾模型的可泛化性,可记忆性以及个性化,我们的一项工作是刻画了测试数据与训练数据之间的差异。
第二个正在逐渐被关注的性能指标是训练开销,而开销源于一种或多种的组合,比如租用云平台,第三方提供的训练资源,尤其是计算资源;第二部分则是分布式机器学习的部署方,如果要招募训练节点,提供数据,或者预处理本地计算和通信,需要花费的开销。第三部分是除了租用资源,付给第三方的开销以外,部署其他的节点,尤其是资源高度受限的边云节点,很可能需要承受能源消耗,比如电量的消耗带来的开销等等。上述的几种不一定同时存在。
第三个性能指标是训练的总体时间,积极学习的训练通常比较耗时,在迭代式的训练以及节点的模型同步中,不同节点会因为计算资源及数据集的大小,带宽通信状况,设备电量容错性等差异,而产生不同的训练速度或者模型更新时间,并可能引发落伍者的问题,而边云协同网络中的分布式机器学习,还可能接收到线上来的流数据,比如视频分析的线上训练,因此训练完成的总时间,其实需要更精细的建模和量化。
我们的工作基本是同时考虑了上述三大性能指标。
▲ 图3
▍Controlling the set of clients
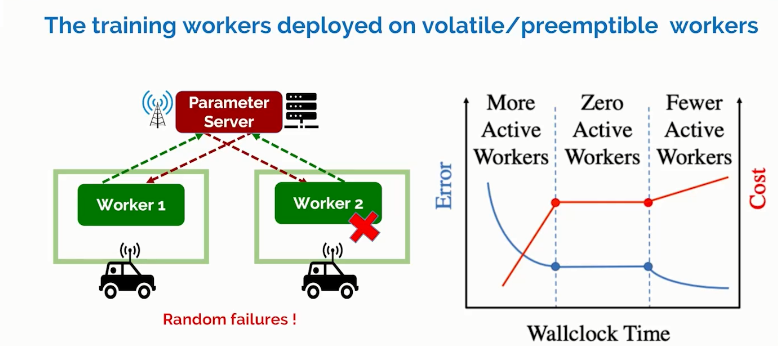
下文介绍的第一项工作,已发表在IEEE Infocom2020及IEEE/ACM ToN 2022中,是该领域内第一个面向节点训练有不确定性的中断,并给出分布式机器学习精度的量化函数,以及最小训练开销的优化方案。
我们考虑参数服务器架构的分布式机器学习训练框架,训练节点可能是租用的云服务器,比如AWS的sport instance,还有Google的可抢占式的云虚拟机等,这些workers也可能是边云节点,比如UAV或者是手机。我们定量刻画了在计算节点有随机中断的情况下,三大性能指标的函数,图3右图简化展示了模型损失和训练开销随着训练时间的变化。
在定量分析的基础上,我们提出训练损失于时间具有上限的最小化训练开销的优化问题,同时我们还考虑了3种不同的同步随机梯度下降的算法:

▲ 图4
Fully Synchronous SGD 指的是每轮所有在线的节点要全部训练完后才进行模型聚合
N-Synchronous SGD 指的是每一轮只接受最快的n个节点训练完后进行模型聚合
N- Batch Synchrounous SGD 指的是每一轮只等待最先更新好的m份的模型梯度,无论这N个batch是来自于哪些节点。
我们的目标是同时优化需要部署的节点数目和训练迭代轮数,因此首先针对节点可受到随机中断,我们先量化了训练的精度收敛性,以场景最为复杂的fully sync为主要目标。
另一个发表在AISTATS上的工作,我们给出了更为复杂也更贴近边缘计算网络场景的联邦学习收敛性,包括面向节点动态的加入和离开,局部模型训练轮数有差异化等场景,只是没有考虑除了精度以外的其他性能,因此在这里就不做详细的介绍,如果大家有兴趣的话可以去查阅这篇论文(Towards Flexible Device Participation in Federated Learning for NonIID Data)。
IEEE/ACM ToN这个应对节点可宕机或者中断的工作,我们的主要贡献还包括与云边协同最相关的第二个主要贡献是给出了要部署的节点数目与训练迭代轮数的协同优化最优解。第三个则是提出了从训练开始,可以指数式增长节点的数目,直到自定义的一个节点数目上限,这种策略可以大幅降低训练时间并且降低开销。

▲ 图5
我们从实验和理论两方面验证了在该策略中,使用恒定的一个学习率反而会超越经典的随轮数衰减的学习率。
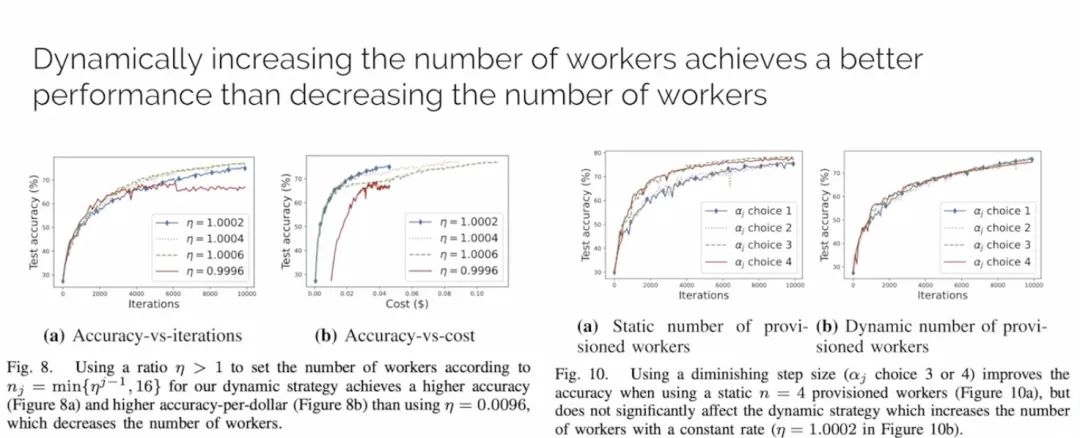
▲ 图6
如何更进一步的在抑制数据源的节点中选择出最优的节点集合,而不仅仅是节点的个数,从而实现测试精度的最优,在我们的另一项工作中,是考虑联邦学习的训练终端选择问题。
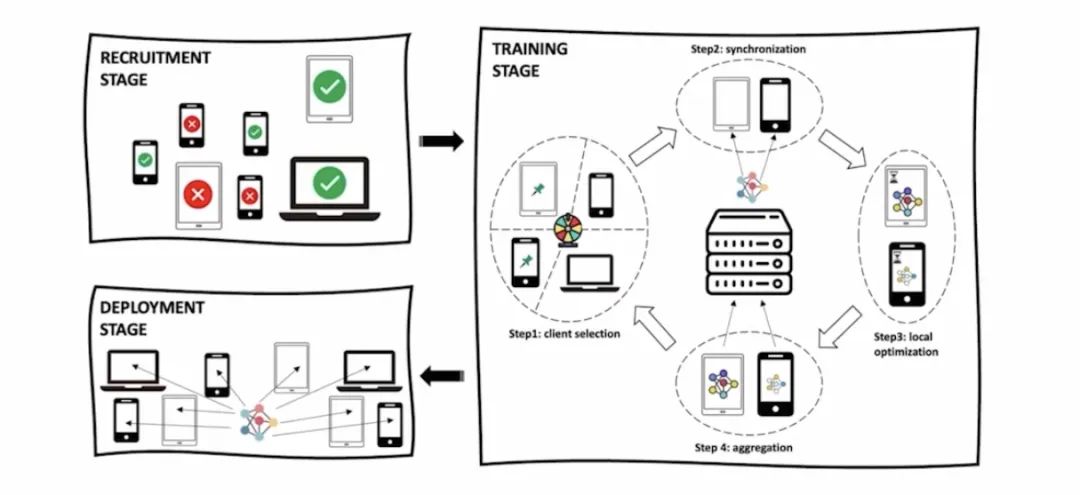
▲ 图7
首先我们要面对的是节点的数量和质量的权衡。比如更多数据的节点,是否一定带来更高的训练精度?答案是否定的,比如节点1有30个数据点,而节点2有200个数据样本,似乎是更优的。但是节点1的数据分布与节点1、2的数据集合的分布相比更为接近,如何考虑选择这个节点?另一方面我们还需要考虑不同的节点还存在差异化的计算资源,以及不确定的被中断的现象。因此,训练精度还需要与训练时间和开销共同权衡。

▲ 图8
为了降低该问题的复杂性,我们首先提出了与最小化全局训练损失函数不同的精度指标,即我们最小化的是数据的训练损失,泛化损失以及表真损失的加权和,泛化损失可以理解为每个节点的局部训练数据集与测试数据集之间的差异,表针损失可以理解为被选的参与节点训练的数据与所有可以选的,或者说所有存在的数据源之间的差异,进一步我们假设了马尔可夫节点的中断和恢复,建立了一个有约束的最小化问题,该优化问题可以被证明是NP-hard。为了给出一个精确算法,我们利用了一个中间的相关问题及三维的背包问题,在此基础上,我们最终设计了一个基于动态规划的算法,并且证明了多项式的时间复杂度。
▍Co-optimizing the hyper-parameters
以上工作皆为针对边云协同分布式机器学习的节点选择的策略,那接下来,我还将简单介绍一下我们另一个工作,发表于 IEEE/ACM IWQoS 2023中,主要内容是针对边缘计算和联邦学习的超参数优化。
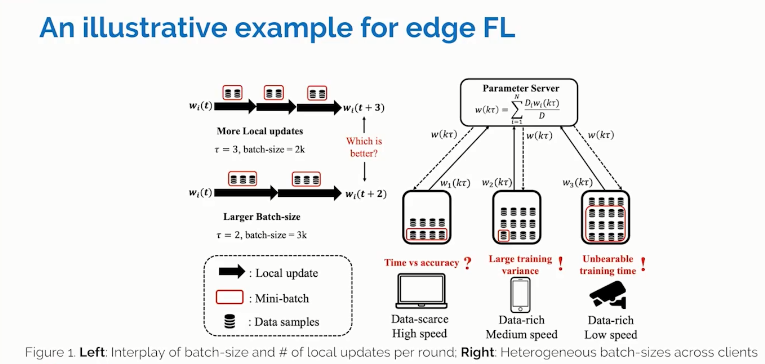
▲ 图9
我们首先给出了在联邦学习领域还鲜有讨论的一个问题,即差异化节点的p数据集大小与模型聚合的频率之间有什么具体的关系。我们看图9的左边wi(t)至wi(t+3)之间的更新为两次模型聚合之间一轮的本地模型更新,如果我们用2k的批数据集大小Batch size,每一轮本地更新中又有3次的梯度下降,那该轮处理的是6K的数据样本,但如果我们选用的是3K的批数据集大小,每轮本地更新两次,或者说做两次梯度下降,那同样处理6K的数据点。
但是两种方案是否实现相同的精度呢?答案是不确定的。我们知道全局聚合频率越低,可能全局模型偏移就越大,而批数以及大小往往控制的是局部方差,此外增大批数据集大小和本地更新的次数,都有可能增大训练时间和开销。
我们再看图9右侧,考虑不同节点的样本数与算例分配不均的情况,比如节点1训练样本少但算力大,若分配批数据集的大小按照这个计算速度来划分,可能导致样本数多但训练速度慢的节点2产生较大的方差,然而数据量大的智能摄像头若分配较大的批数据集又会加剧落伍者的问题。因此考虑多性能指标的必要性与节点的数据质量、系统能力的差异性复杂地交错在一起,这就要求我们需要对批数据集大小和聚合频率进行联合优化,而不能草率选择。

▲ 图10
为了解决上述联合优化问题,我们首先进行了数学建模,并且定量分析了面向训练节点抑制的批数据集以及模型聚合频率的精度收敛性的分析,这是我们主要贡献之一。接下来,基于该精度函数,我们设计了一个精确算法并证明了多项式时间复杂度和算法的最优性。除此之外,我们还将这个算法进行了线上的优化,最后我们搭建了一个分布式,即联邦学习的一个系统框架,具有100个节点的计算资源,通信资源以及本地数据集的分布和数量都是相互有差异的,我们测试了我们的算法AdaCoOpt,与其他多种联邦学习的超参数优化方案的比较,最终验证了这一算法的优越性。
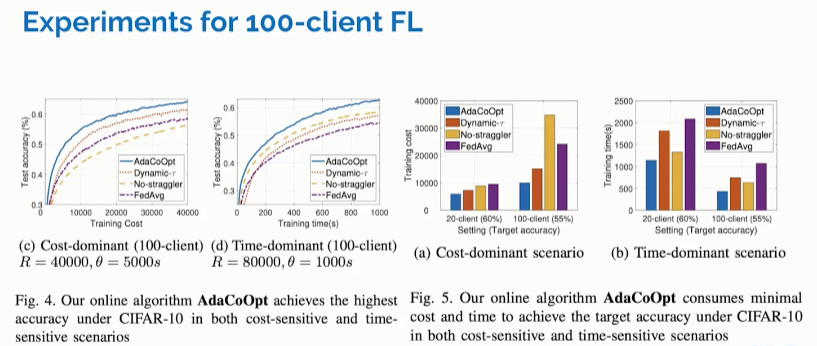
▲ 图11
比如图11左图中我们可以看到,当计算开销成为瓶颈,也就是Cost-dominant这一场景中,消除落伍者的算法叫做No-struggler,它是反而无法发挥优势的。因为当这个计算开销,比如能耗成为瓶颈的时候,No-struggler只在这个时间维度上优化资源的利用率,因此无法发挥作用;而当训练时间成为瓶颈的时候,No-struggler的算法与我们的算法,只优化聚合频率性能,也就是Dynamic-T 比起来是有相近的训练精度、测试精度。然而联合优化批数据集语义和频率,也就是我们的AdaCoOpt算法仍然具有较大的优势。
▍edge-cloud DML 未来研究方向
以上是我们在边云协同分布式机器学习方向的已有工作,下面介绍几个有意思的未来的研究方向。
首先是将节点集合的选择与分布式机器学习网络的拓扑的联合优化。为了简化该优化问题,我们可以构造一个多层级的DML的训练系统,多层级的节点组成模型训练和聚合梯队,在每一层我们可以动态优化这个数据源的节点,或者计算服务器的选择。此外,还需要优化每一个层级的差异化的超参数,实现资源和数据质量的一个最优平衡。
另一个方向是个性化联邦学习,我们更感兴趣的是模型更新方式和聚合方式的算法优化。
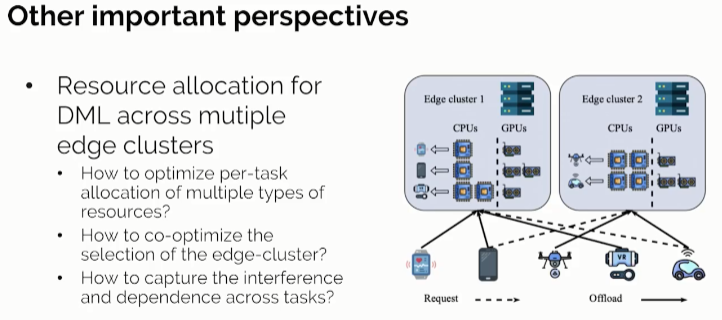
▲ 图12
最后,我们简单介绍一个发表在IEEE INFOCOM 2023的工作,资源调度器TapFinger。主要目标是面向机器学习任务实现边缘服务器集群的高效资源管理。我们实现了一个以最小化任务完成时间为优化目标的动态资源弹性配置和任务调度系统。由于机器学习任务,包括训练和推理任务,以及不同的模型,不同的应用,具有高度差异化的资源敏感度,比如GPU、CPU、存储带宽等等多种不同的资源,因此在分割这些有限的边云资源时,有效的资源分配和调度策略将从系统层面为边云机器学习带来一个性能的提升。为解决这样的问题,我们采用的是图神经网络与强化学习的结合,并且设计了新型的多智能体强化学习的训练网络,从而实现了实时的CPU和GPU等多种资源弹性分配和任务调度,较state-of-the-art调度器可大幅减少混合机器学习任务的完成时间总和。
论文索引
X. Mo and J. Xu, “Energy-efficient federated edge learning with joint communication and computation design,” Journal of Communications and Information Networks, vol. 6, no. 2,pp. 110–124, 2021.
Q. Zeng, Y. Du, K. Huang, and K. K. Leung, “Energy-efficient resource management for federated edge learning with cpu-gpu heterogeneous computing,” IEEE Transactions on Wireless Communications, vol. 20, no. 12, pp. 7947–7962, 2021.
Xiaoxi Zhang, Jianyu Wang, Li-Feng Lee, Tom Yang, Akansha Kalra,Gauri Joshi, Carlee Joe-Wong, “Machine Learning on Volatile Instances:Convergence, Runtime, and Cost Trade-offs”, IEEE/ACM Transactions on Networking, 30(1):215—228, 2022
Yichen Ruan, Xiaoxi Zhang, Shu-Che Liang,Carlee Joe-Wong, "Towards Flexible Device Participation in Federated Learning for Non-IID Data", International Conference on Artificial Intelligence and Statistics(AISTATS), 2021
Yichen Ruan, Xiaoxi Zhang, Carlee Joe-Wong, “How Valuable Is Your Data? Optimizing Device Recruitment in Federated Learning”, submitted to ToN,prelimianary results are published in WiOpt 2021
KubeEdge社区
KubeEdge是业界首个云原生边缘计算框架、云原生计算基金会内部唯一孵化级边缘计算开源项目,社区已完成业界最大规模云原生边云协同高速公路项目(统一管理10万边缘节点/50万边缘应用)、业界首个云原生星地协同卫星、业界首个云原生车云协同汽车、业界首个云原生油田项目,开源业界首个分布式协同AI框架Sedna及业界首个边云协同终身学习范式,并在持续开拓创新中。
KubeEdge网站 : https://kubeedge.io
GitHub : https://github.com/kubeedge/kubeedge
Slack : https://kubeedge.slack.com
邮件列表 : https://groups.google.com/forum/#!forum/kubeedge
每周社区例会 : https://zoom.us/j/4167237304
Twitter : https://twitter.com/KubeEdge
文档地址 : https://docs.kubeedge.io/en/latest/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









