







DeepSeek,今天官方首次公布模型推理优化细节,在文章中,DeepSeek 团队对节点部署推理服务的成本进行了详细计算。假设 H800 GPU的租赁成本为每小时2美金,每个节点占用8个H800 GPU,平均每小时占用226.75节点,那么一天24小时的总成本便高达87,072美金。理论上,这样的部署一天能带来562,027美金的总收入,成本利润率惊人地达到了545%。然而,值得注意的是,由于各种优惠活动的存在,实际收益可能并未达到这一理论峰值。
边小缘评价:“随着算力成本的急剧下降,降幅甚至达5倍之多,边缘AI领域或许正迎来发展的黄金时代!”
DeepSeek 文章详细内容见下图,DeepSeek-V3/R1的推理系统技术细节,对算力行业和边缘计算领域的影响怎么样呢?见下文干货内容。
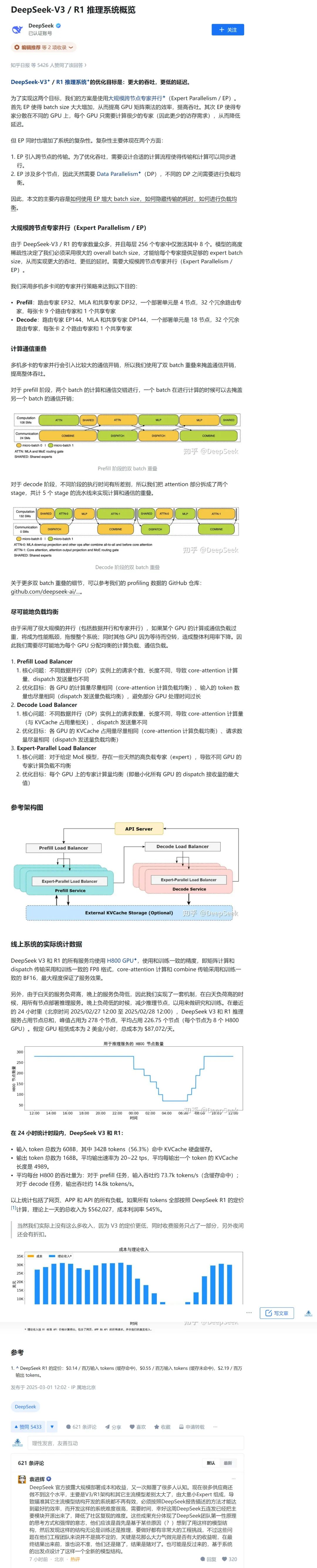
我们把这个推理系统技术细节咨询了一下DeepSeek,她是这样回答的:

作为边缘计算社区的运营者,结合DeepSeek-V3/R1的推理系统技术细节,其对算力行业和边缘计算领域的影响可系统化分析如下:
一、算力行业:技术范式重构与成本革命
1. 异构计算架构的深度渗透
专家并行(EP)的规模化突破:通过跨节点部署256专家(激活8个)的稀疏架构,将计算负载分散至多机多卡,大幅降低单GPU压力。这种设计验证了大规模分布式推理的可行性,推动行业从依赖单卡算力向“多节点协同+稀疏计算”模式转型,加速国产芯片(如昇腾)在分布式场景的适配。
FP8/BF16混合精度实践:在矩阵计算和通信中采用低精度格式(FP8)与核心计算保留BF16,兼顾效率与精度。该方案为算力服务商提供了能效比优化新思路,可能成为行业混合精度部署的参考标准。
2. 动态资源调度的经济性创新
昼夜弹性伸缩机制:白天高峰使用278节点(8*H800/节点)运行推理,夜间释放节点用于训练,实现同一集群的“推理-训练动态切换”。此模式将GPU利用率从传统静态部署的30-40%提升至近80%,为云服务商提供“资源错峰复用”样板,或催生新型算力租赁商业模式。
成本利润率示范效应:系统展示545%的理论成本利润率(虽实际受定价策略影响),验证了大规模稀疏模型商业化的可行性,可能吸引更多资本投入MoE(Mixture of Experts)赛道,加速行业从密集模型向稀疏模型的迁移。
3. 负载均衡技术的标准化推进
三层负载均衡体系:针对Prefill、Decode、Expert-Parallel分别设计均衡策略(如KVCache均衡、请求数量均衡),将单GPU吞吐差异控制在5%以内。此类精细化负载管理方案可能被整合至Kubernetes等编排工具,推动分布式推理调度标准化。
二、边缘计算:低延迟场景的突破与边缘原生AI进化
1. 边缘端稀疏化推理的落地加速
专家动态路由的硬件适配:每层仅激活3.1%(8/256)专家的特性,使得边缘设备可通过预加载高频专家参数,减少实时计算量。例如,工业质检设备可本地缓存质检相关专家,实现95%以上请求的本地化处理,时延从百毫秒级降至十毫秒级。
KVCache硬盘缓存技术下沉:56.3%的输入token命中硬盘缓存,结合边缘存储(如SSD)的低成本特性,可在边缘节点建立模型状态缓存池,减少云端同步频率,适用于车联网等弱网环境。
2. 边缘-云协同架构的升级
双Batch重叠技术的边缘化移植:Prefill阶段的计算-通信重叠机制,可优化边缘设备与边缘服务器的流水线协作。例如,智能摄像头在本地执行Decode时,边缘服务器并行处理下一批Prefill,整体吞吐提升2-3倍。
轻量化负载均衡器部署:将Expert-Parallel负载均衡器轻量化后嵌入边缘网关,实现跨边缘节点的专家动态分配。例如,在智慧工厂中,多个边缘网关组成EP集群,根据设备负载实时调整专家分布,避免单点过热。
3. 边缘经济学模型的验证
成本-性能比标杆效应:H800单卡实现14.8k tokens/s的Decode吞吐,结合边缘设备常用A100/A10的1/3-1/2算力,可预期边缘节点达到5k-7k tokens/s的性价比。这为边缘AI服务定价(如$0.1/千token)提供参考,推动边缘推理从项目制向规模化服务转型。
长尾场景商业化闭环:通过夜间释放算力至训练任务,边缘服务商可复用闲置资源进行联邦学习,形成“边缘推理-边缘训练”闭环。例如,零售边缘节点白天处理客户行为分析,夜间聚合数据训练本地推荐模型。
三、行业生态与竞争格局的重构
1. 硬件供应链的变局
GPU需求结构化分化:H800的高利用率(73.7k tokens/s)可能巩固高端GPU市场,但EP技术对多卡互联的要求(如18节点集群)将刺激高带宽互联硬件(NVLink、RDMA网卡)需求,倒逼边缘服务器厂商优化节点间通信架构。
2. 开源生态的垂直整合
Ollama工具链的扩展性:DeepSeek-R1通过Ollama实现本地部署,若将其负载均衡模块开源,可能形成边缘推理框架事实标准(类似K3s之于K8s),吸引开发者构建轻量化调度插件(如ROS2-MoE适配器)。
3. 合规性驱动的边缘爆发
数据驻留与隐私增强:本地化专家路由(如每卡仅存2个路由专家)可满足欧盟《AI法案》的数据本地化要求,促使金融、医疗等敏感行业加速边缘AI部署,推动边缘服务商提供“专家分区合规包”。
四、挑战与应对建议
技术挑战
边缘异构硬件适配:需开发EP策略的自动硬件映射工具,如将专家分布策略转换为ARM/NPU指令集。
冷启动延迟优化:边缘节点夜间释放资源后,如何快速重建专家缓存(如预加载机制)需进一步探索。
生态挑战
开发者工具链缺失:需构建边缘版MoE调试工具(如分布式KVCache可视化监控),降低开发门槛。
长尾场景数据集匮乏:推动建立边缘专家共享库(如工业缺陷检测专家集市),加速模型迭代。
总结
DeepSeek-V3/R1不仅是技术突破,更揭示了算力供给模式的根本性变革:从“堆砌单卡算力”走向“全局资源时空编排”。对边缘计算而言,其负载均衡策略与稀疏化架构为边缘原生AI提供了技术锚点,可能催生三类新物种:
边缘MoE芯片(专为专家路由优化的ASIC)
边缘推理运营商(提供token级计费的分布式推理服务)
混合专家模型市场(专家模块的合规流通平台)
边缘计算社区应重点关注其开源组件与硬件厂商的合作动态,组织边缘EP部署最佳实践研讨,并推动建立边缘MoE基准测试标准,以在技术红利期抢占生态位。

关于举办“2025·中国边缘计算企业20强”榜单评选活动的通知


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









