







最近使用 select count(id) from temp_orders; 查询很慢。表中数据有5000万+条。
使用 EXPLAIN SELECT COUNT(id) FROM temp_orders;结果如下

通过上图可以看出 该查询语句使用了索引,但是并不是按主键查询的,而是使用的自定义的索引FK_order_parking_lot_id。
先不说这个自定义的索引有没问题,这个索引也不是我定义的,不可能去动,万一影响到其他同事在用,就gg了。
在网上看到有人在 **主键上添加UNIQUE索引**
alter table temp_orders add unique (id);
此时查询走主键了,查询也快了很多。

但是 主键本来就是特殊的唯一键。 主键= unique + not null
在主键再加一个唯一键 unique 索引,这不是浪费空间吗?
网上继续爬,得到最后结果,在查询的时候可以指定查询使用哪个索引。
EXPLAIN SELECT COUNT(id) FROM temp_orders force index (PRIMARY);
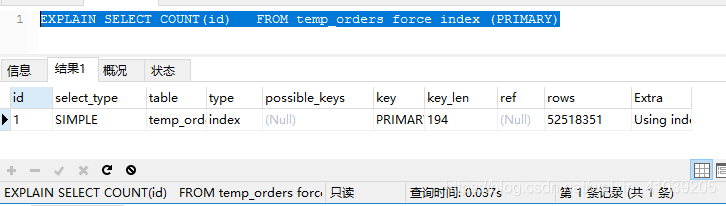
结果棒棒哒! 5000+万的数据 37毫秒搞定!!














 2162
2162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









