







函数和模块
先来研究一道数学的排列组合题目
计算C_7^3 = 35,计算代码如下
"""
输入M和N计算C(M,N)
Version: 0.1
date : 2022.3.28
"""
m = int(input('m = '))
n = int(input('n = '))
#计算m的阶乘
fm = 1
for num in range(1,m+1):
fm *= num
#计算n的阶乘
fn = 1
for num in range(1,n+1):
fn *= num
#计算m-n的阶乘
fk = 1
for num in range(1,m-n+1):
fk *=num
#计算C(M,N)的值
print(fm // fn // fk)
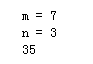
1.函数的作用
不知大家是否注意到,上面的代码中我们做了三次求阶乘,虽然m、n、m - n的值各不相同,但是三段代码并没有实质性的区别,属于重复代码。世界级的编程大师Martin Fowler先生曾经说过:“代码有很多种坏味道,重复是最坏的一种!”。要写出高质量的代码首先要解决的就是重复代码的问题。对于上面的代码来说,我们可以将计算阶乘的功能封装到一个称为“函数”的代码块中,在需要计算阶乘的地方,我们只需要“调用函数”就可以了.
定义函数
python中每个函数都有自己的名字、自变量和因变量。我们通常把Python中函数的自变量称为函数的参数,而因变量称为函数的返回值。
在Python中可以使用def关键字来定义函数,和变量一样每个函数也应该有一个漂亮的名字,命名规则跟变量的命名规则是一致的。在函数名后面的圆括号中可以放置传递给函数的参数,就是我们刚才说到的函数的自变量,而函数执行完成后我们会通过return关键字来返回函数的执行结果,就是我们刚才说的函数的因变量。一个函数要执行的代码块(要做的事情)也是通过缩进的方式来表示的,跟之前分支和循环结构的代码块是一样的。大家不要忘了def那一行的最后面还有一个:,之前提醒过大家,那是在英文输入法状态下输入的冒号。
我们可以通过函数对上面的代码进行重构。**所谓重构,是在不影响代码执行结果的前提下对代码的结构进行调整。**重构之后的代码如下所示。
"""
输入M和N计算C(M,N),使用函数
Version: 0.1
date : 2022.3.28
"""
#定义函数。def是定义函数的关键字,comb是函数名,num是参数(自变量)
def comb(num):
result = 1
for n in range(1,num + 1):
result *= n
return result #注意缩进,这里的return 一定是和for最外层循环对齐的
m = int(input ('m = '))
n = int(input ('n = '))
#计算阶乘直接调用函数comb()括号里是参数
print(comb(m) // comb(n) // comb(m - n))
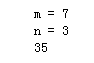
说明:事实上,Python标准库的math模块中有一个名为factorial的函数已经实现了求阶乘的功能,我们可以直接使用该函数来计算阶乘。将来我们使用的函数,要么是自定义的函数,要么是Python标准库或者三方库中提供的函数。
2.函数的参数
2.1参数的默认值
如果函数中没有return语句,那么函数默认返回代表空值的None。另外,在定义函数时,函数也可以没有自变量,但是函数名后面的圆括号是必须有的。Python中还允许函数的参数拥有默认值,我们可以把之前讲过的一个例子“CRAPS赌博游戏”中摇色子获得点数的功能封装成函数,代码如下所示。
"""
参数的默认值
Version: 0.1
date : 2022.3.28
"""
from random import randint
#定义摇色子的函数,n 表示色子的个数,默认值为2
def roll_dice(n = 2):
total = 0
for _ in range(n):
total += randint(1, 6)
return total
#如果没有指定参数,那么n使用默认值2,表示摇两颗色子
print(roll_dice())
#如果传入的参数是4,变量n被赋值为4,表示摇4颗色子获得的点数
print(roll_dice(4))

带默认值的参数必须放在不带默认值参数之后
def add(a=0, b=0, c=0):
"""三个数相加求和"""
return a + b + c
# 调用add函数,没有传入参数,那么a、b、c都使用默认值0
print(add()) # 0
# 调用add函数,传入一个参数,那么该参数赋值给变量a, 变量b和c使用默认值0
print(add(1)) # 1
# 调用add函数,传入两个参数,1和2分别赋值给变量a和b,变量c使用默认值0
print(add(1, 2)) # 3
# 调用add函数,传入三个参数,分别赋值给a、b、c三个变量
print(add(1, 2, 3)) # 6
# 传递参数时可以不按照设定的顺序进行传递,但是要用“参数名=参数值”的形式
print(add(c=50, a=100, b=200)) # 350
2.2 可变参数
接下来,我们还可以实现一个对任意多个数求和的add函数,因为Python语言中的函数可以通过星号表达式语法来支持可变参数。所谓可变参数指的是在调用函数时,可以向函数传入0个或任意多个参数。将来我们以团队协作的方式开发商业项目时,很有可能要设计函数给其他人使用,但有的时候我们并不知道函数的调用者会向该函数传入多少个参数,这个时候可变参数就可以派上用场。下面的代码演示了用可变参数实现对任意多个数求和的add函数。
"""
可变参数
Version: 0.1
date : 2022.3.28
"""
#用*号表示arges可以接收0个或任意多个参数
def add(*arges):
total = 0
#可变参数可以放在for循环中取出每个参数的值
for val in arges:
if type(val) in (int , float):
total += val
return total
#调用的时候可以传入0个或n个参数
print(add())
print(add(1))
print(add(1,3,6))

3.用模块管理函数
不管用什么样的编程语言来写代码,给变量、函数起名字都是一个让人头疼的问题,因为我们会遇到命名冲突这种尴尬的情况。最简单的场景就是在同一个.py文件中定义了两个同名的函数,如下所示。
def foo():
print('hello, world!')
def foo():
print('goodbye, world!')
foo() # 大家猜猜调用foo函数会输出什么

当然上面的这种情况我们很容易就能避免,但是如果项目是团队协作多人开发的时候,团队中可能有多个程序员都定义了名为foo的函数,这种情况下怎么解决命名冲突呢?答案其实很简单,Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块再使用完全限定名的调用方式就可以区分到底要使用的是哪个模块中的foo函数,代码如下所示。
module1.py
def foo():
print('hello, world!')
module2.py
def foo():
print('goodbye, world!')
test.py
import module1
import module2
# 用“模块名.函数名”的方式(完全限定名)调用函数,
module1.foo() # hello, world!
module2.foo() # goodbye, world!
在导入模块时,还可以使用as关键字对模块进行别名,这样我们可以使用更为简短的完全限定名。
test.py
import module1 as m1
import module2 as m2
m1.foo() # hello, world!
m2.foo() # goodbye, world!
上面的代码我们导入了定义函数的模块,我们也可以使用from…import…语法从模块中直接导入需要使用的函数,代码如下所示。
test.py
from module1 import foo
foo() # hello, world!
from module2 import foo
foo() # goodbye, world!
但是,如果我们如果从两个不同的模块中导入了同名的函数,后导入的函数会覆盖掉先前的导入,就像下面的代码中,调用foo会输出hello, world!,因为我们先导入了module2的foo,后导入了module1的foo 。如果两个from…import…反过来写,就是另外一番光景了。
test.py
from module2 import foo
from module1 import foo
foo() # hello, world!
如果想在上面的代码中同时使用来自两个模块中的foo函数也是有办法的,大家可能已经猜到了,还是用as关键字对导入的函数进行别名,代码如下所示。
test.py
from module1 import foo as f1
from module2 import foo as f2
f1() # hello, world!
f2() # goodbye, world!
4.标准库中的模块和函数
Python标准库中提供了大量的模块和函数来简化我们的开发工作,我们之前用过的random模块就为我们提供了生成随机数和进行随机抽样的函数;而time模块则提供了和时间操作相关的函数;上面求阶乘的函数在Python标准库中的math模块中已经有了,实际开发中并不需要我们自己编写,而math模块中还包括了计算正弦、余弦、指数、对数等一系列的数学函数。随着我们进一步的学习Python编程知识,我们还会用到更多的模块和函数。
Python标准库中还有一类函数是不需要import就能够直接使用的,我们将其称之为内置函数,这些内置函数都是很有用也是最常用的,下面的表格列出了一部分的内置函数。

总结
函数是对功能相对独立且会重复使用的代码的封装。学会使用定义和使用函数,就能够写出更为优质的代码。当然,Python语言的标准库中已经为我们提供了大量的模块和常用的函数,用好这些模块和函数就能够用更少的代码做更多的事情;如果这些模块和函数不能满足我们的要求,我们就需要自定义函数,然后用模块的概念来管理这些自定义函数。
函数的应用
1.经典案例
1.1设计一个生成验证码的函数
说明:验证码由数字和英文大小写字母组成,长度可以由参数指定
import random
import string
ALL_CHARS = string.digits + string.ascii_letters
def generate_code(code_len = 4):
'''生成指定长度的验证码
para code_len :验证码长度(默认4个字符)
return : 由大小写英文字母和数字构成的随机验证码字符串
'''
return ''.join(random.choices(ALL_CHARS,k = code_len))
#生成10组随机验证码
for _ in range(10):
print(generate_code())

说明:random模块的sample和choices函数都可以实现随机抽样,sample实现无放回抽样,这意味着抽样取出的字符是不重复的;choices实现有放回抽样,这意味着可能会重复选中某些字符。这两个函数的第一个参数代表抽样的总体,而参数k代表抽样的数量。
1.2设计一个函数返回给定文件的后缀名。
说明:文件名通常是一个字符串,而文件的后缀名指的是文件名中最后一个.后面的部分,也称为文件的扩展名,它是某些操作系统用来标记文件类型的一种机制,例如在Windows系统上,后缀名exe表示这是一个可执行程序,而后缀名txt表示这是一个纯文本文件。需要注意的是,在Linux和macOS系统上,文件名可以以.开头,表示这是一个隐藏文件,像.gitignore这样的文件名,.后面并不是后缀名,这个文件没有后缀名或者说后缀名为''。
def get_suffix(filename, ignore_not = True):
"""获取文件名的后缀名
:param filename :文件名
:param ignore_dot: 是否忽略后缀名前面的点
:return :文件的后缀名
"""
#从字符串中逆向查找.出现的位置
pos = filename.rfind('.')
#通过切片操作从文件名中取出后缀名
if pos <= 0:
return ''
return filename[pos + 1:] if ignore_not else filename[pos:]
#测试
print(get_suffix('readme.txt')) # txt
print(get_suffix('readme.txt.md')) # md
print(get_suffix('.readme')) #
print(get_suffix('readme.')) #
print(get_suffix('readme')) #

1.3写一个判断给定的正整数是不是质数的函数。
def is_prime(num : int) -> bool:
"""判断一个正整数是不是质数
:param num :正整数
:return :如果是质数返回True,否则返回False
"""
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return num != 1
is_prime(200)
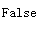
1.4写出计算两个正整数最大公约数和最小公倍数的函数。
def gcd_and_lcm(x: int, y: int) -> int:
"""求最大公倍数和最小公约数"""
a, b = x, y
while b % a != 0:
a , b = b % a, a
return a, x * y // a
gcd_and_lcm(4,6)
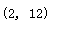
1.5写出计算一组样本数据描述性统计信息的函数。
import math
def ptp(data):
"""求极差(全距)"""
return max(data) - min(data)
def average(data):
"""求均值"""
return sum(data) / len(data)
def variance(data):
"""求方差"""
x_bar = average(data)
temp = [(num - x_bar) ** 2 for num in data]
return sum(temp) / (len(temp) - 1)
def standard_deviation(data):
"""求标准差"""
return math.sqrt(variance(data))
def median(data):
"""找中位数"""
temp, size = sorted(data), len(data)
if size % 2 != 0:
return temp[size // 2]
else:
return average(temp[size // 2 - 1:size // 2 + 1])
总结
在写代码尤其是开发商业项目的时候,一定要有意识的将相对独立且重复出现的功能封装成函数,这样不管是自己还是团队的其他成员都可以通过调用函数的方式来使用这些功能。
函数使用进阶
前面我们讲到了关于函数的知识,我们还讲到过Python中常用的数据类型,这些类型的变量都可以作为函数的参数或返回值,用好函数还可以让我们做更多的事情。
1.关键字参数
下面是一个判断传入的三条边长是否能够构成三角形的函数,在调用函数传入参数时,我们可以指定参数名,也可以不指定参数名
def is_triangle(a, b, c):
print(f'a = {a}, b = {b}, c = {c}')
return a + b > c and b + c > a and a + c > b
print(is_triangle(3,4,7))
# 调用函数传入参数不指定参数名按位置对号入座
print(is_triangle(1, 2, 3))
# 调用函数通过“参数名=参数值”的形式按顺序传入参数
print(is_triangle(a=1, b=2, c=3))
# 调用函数通过“参数名=参数值”的形式不按顺序传入参数
print(is_triangle(c=3, a=1, b=2))
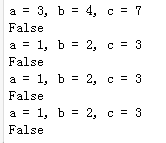
在没有特殊处理的情况下,函数的参数都是位置参数,也就意味着传入参数的时候对号入座即可,如上面代码的第7行所示,传入的参数值1、2、3会依次赋值给参数a、b、c。当然,也可以通过参数名=参数值的方式传入函数所需的参数,因为指定了参数名,传入参数的顺序可以进行调整,如上面代码的第9行和第11行所示。
调用函数时,如果希望函数的调用者必须以参数名=参数值的方式传参,可以用命名关键字参数(keyword-only argument)取代位置参数。所谓命名关键字参数,是在函数的参数列表中,写在*之后的参数,代码如下所示。
def is_triangle(*, a, b, c):
print(f'a = {a}, b = {b}, c = {c}')
return a + b > c and b + c > a and a + c > b
# TypeError: is_triangle() takes 0 positional arguments but 3 were given
# print(is_triangle(3, 4, 5))
# 传参时必须使用“参数名=参数值”的方式,位置不重要
print(is_triangle(a=3, b=4, c=5))
print(is_triangle(c=5, b=4, a=3))
上面的is_triangle函数,参数列表中的*是一个分隔符,前面的参数都是位置参数,而后面的参数就是命名关键字参数。
我们之前讲过在函数的参数列表中可以使用可变参数*args来接收任意数量的参数,但是我们需要看看,*args是否能够接收带参数名的参数
def calc(*args):
result = 0
for arg in args:
if type(arg) in (int, float):
result += arg
return result
print(calc(a=1, b=2, c=3))

执行上面的代码会引发TypeError错误,错误消息为calc() got an unexpected keyword argument ‘a’,由此可见,*args并不能处理带参数名的参数。我们在设计函数时,如果既不知道调用者会传入的参数个数,也不知道调用者会不会指定参数名,那么同时使用可变参数和关键字参数。关键字参数会将传入的带参数名的参数组装成一个字典,参数名就是字典中键值对的键,而参数值就是字典中键值对的值,代码如下所示。
def calc(*args, **kwargs):
result = 0
for arg in args:
if type(arg) in (int, float):
result += arg
for value in kwargs.values():
if type(value) in (int, float):
result += value
return result
print(calc()) # 0
print(calc(1, 2, 3)) # 6
print(calc(a=1, b=2, c=3)) # 6
print(calc(1, 2, c=3, d=4)) # 10
提示:不带参数名的参数(位置参数)必须出现在带参数名的参数(关键字参数)之前,否则将会引发异常。例如,执行calc(1, 2, c=3, d=4, 5)将会引发SyntaxError错误,错误消息为positional argument follows keyword argument,翻译成中文意思是“位置参数出现在关键字参数之后”。
2.高阶函数的用法
在前面几节课中,我们讲到了面向对象程序设计,在面向对象的世界中,一切皆为对象,所以类和函数也是对象。函数的参数和返回值可以是任意类型的对象,这就意味着函数本身也可以作为函数的参数或返回值,这就是所谓的高阶函数。
如果我们希望上面的calc函数不仅仅可以做多个参数求和,还可以做多个参数求乘积甚至更多的二元运算,我们就可以使用高阶函数的方式来改写上面的代码,将加法运算从函数中移除掉,具体的做法如下所示。
def calc(*args, init_value, op, **kwargs):
result = init_value
for arg in args:
if type(arg) in (int, float):
result = op(result, arg)
for value in kwargs.values():
if type(value) in (int, float):
result = op(result, value)
return result
def add(x, y):
return x + y
def mul(x, y):
return x * y
print(calc(1, 2, 3, init_value=0, op=add, x=4, y=5)) # 15
print(calc(1, 2, x=3, y=4, z=5, init_value=1, op=mul)) # 120

通过对高阶函数的运用,calc函数不再和加法运算耦合,所以灵活性和通用性会变强,这是一种解耦合的编程技巧,但是最初学者来说可能会稍微有点难以理解。需要注意的是,将函数作为参数和调用函数是有显著的区别的,调用函数需要在函数名后面跟上圆括号,而把函数作为参数时只需要函数名即可。上面的代码也可以不用定义add和mul函数,因为Python标准库中的operator模块提供了代表加法运算的add和代表乘法运算的mul函数,我们直接使用即可,代码如下所示。
import operator
print(calc(1, 2, 3, init_value=0, op=operator.add, x=4, y=5)) # 15
print(calc(1, 2, x=3, y=4, z=5, init_value=1, op=operator.mul)) # 120
Python内置函数中有不少高阶函数,我们前面提到过的filter和map函数就是高阶函数,前者可以实现对序列中元素的过滤,后者可以实现对序列中元素的映射,例如我们要去掉一个整数列表中的奇数,并对所有的偶数求平方得到一个新的列表,就可以直接使用这两个函数来做到,具体的做法是如下所示。
def is_ewen(num):
return num % 2 == 0
def square(num):
return num ** 2
numbers1 = [20,11,2,5,8]
numbers2 = list(map(square,filter(is_ewen,numbers1)))
print(numbers2)
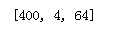
当然,要完成上面代码的功能,也可以使用列表生成式,列表生成式的做法更为简单优雅。
numbers1 = [20, 11, 2, 5, 8]
numbers2 = [num ** 2 for num in numbers1 if num % 2 == 0]
print(numbers2)

3.Lambda 函数
在使用高阶函数的时候,如果作为参数或者返回值的函数本身非常简单,一行代码就能够完成,那么我们可以使用Lambda函数来表示。Python中的Lambda函数是没有的名字函数,所以很多人也把它叫做匿名函数,匿名函数只能有一行代码,代码中的表达式产生的运算结果就是这个匿名函数的返回值。上面代码中的is_even和square函数都只有一行代码,我们可以用Lambda函数来替换掉它们,代码如下所示。
numbers1 = [20, 11, 2, 5, 8]
numbers2 = list(map(lambda x: x ** 2,filter(lambda x: x % 2 == 0,numbers1 )))
print(numbers2)
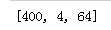
通过上面的代码可以看出,定义Lambda函数的关键字是lambda,后面跟函数的参数,如果有多个参数用逗号进行分隔;冒号后面的部分就是函数的执行体,通常是一个表达式,表达式的运算结果就是Lambda函数的返回值,不需要写return 关键字。
如果需要使用加减乘除这种简单的二元函数,也可以用Lambda函数来书写,例如调用上面的calc函数时,可以通过传入Lambda函数来作为op参数的参数值。当然,op参数也可以有默认值,例如我们可以用一个代表加法运算的Lambda函数来作为op参数的默认值。
def calc(*args, init_value = 0,op = lambda x,y:x+y, ** kwargs):
result = init_value
for arg in args:
if type(arg) in (int, float):
result = op(result, arg)
for value in kwargs.values():
if type(value) in (int, float):
result = op(result, value)
return result
# 调用calc函数,使用init_value和op的默认值
print(calc(1, 2, 3, x=4, y=5)) # 15
# 调用calc函数,通过lambda函数给op参数赋值
print(calc(1, 2, 3, x=4, y=5, init_value=1, op=lambda x, y: x * y))
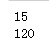
提示:注意上面的代码中的calc函数,它同时使用了可变参数、关键字参数、命名关键字参数,其中命名关键字参数要放在可变参数和关键字参数之间,传参时先传入可变参数,关键字参数和命名关键字参数的先后顺序并不重要。
有很多函数在Python中用一行代码就能实现,我们可以用Lambda函数来定义这些函数,调用Lambda函数就跟调用普通函数一样,代码如下所示。
import operator, functools
# 一行代码定义求阶乘的函数
fac = lambda num: functools.reduce(operator.mul, range(1, num + 1), 1)
# 一行代码定义判断素数的函数
is_prime = lambda x: x > 1 and all(map(lambda f: x % f, range(2, int(x ** 0.5) + 1)))
# 调用Lambda函数
print(fac(10)) # 3628800
print(is_prime(9)) # False
提示1:上面使用的reduce函数是Python标准库functools模块中的函数,它可以实现对数据的归约操作,通常情况下,过滤(filter)、映射(map)和归约(reduce)是处理数据中非常关键的三个步骤,而Python的标准库也提供了对这三个操作的支持。
提示2:上面使用的all函数是Python内置函数,如果传入的序列中所有布尔值都是True,all函数就返回True,否则all函数就返回False。
总结
Python中的函数可以使用可变参数*args和关键字参数**kwargs来接收任意数量的参数,而且传入参数时可以带上参数名也可以没有参数名,可变参数会被处理成一个元组,而关键字参数会被处理成一个字典。Python中的函数是一等函数,可以赋值给变量,也可以作为函数的参数和返回值,这也就意味着我们可以在Python中使用高阶函数。如果我们要定义的函数非常简单,只有一行代码且不需要函数名,可以使用Lambda函数(匿名函数)。
函数的高级应用
1.装饰器
装饰器是Python中用一个函数装饰另外一个函数或类并为其提供额外功能的语法现象。装饰器本身是一个函数,它的参数是被装饰的函数或类,它的返回值是一个带有装饰功能的函数。很显然,装饰器是一个高阶函数,它的参数和返回值都是函数。下面我们先通过一个简单的例子来说明装饰器的写法和作用,假设已经有名为downlaod和upload的两个函数,分别用于文件的上传和下载,下面的代码用休眠一段随机时间的方式模拟了下载和上传需要花费的时间,并没有联网做上传下载。
import random
import time
def download(filename):
print(f'开始下载{filename}.')
time.sleep(random.randint(2, 6))
print(f'{filename}下载完成')
def upload(filename):
print(f'开始上传{filename}.')
time.sleep(random.randint(4, 8))
print(f'{filename}上传完成.')
start = time.time()
download('MATLAB从删库到跑路.avi')
end = time.time()
print(f'花费时间:{end - start:.3f}秒')
start = time.time()
upload('C++从入门到住院.pdf')
end = time.time()
print(f'花费时间:{end - start:.3f}秒')

通过上面的代码,我们可以得到下载和上传花费的时间,但不知道大家是否注意到,上面记录时间、计算和显示执行时间的代码都是重复代码。有编程经验的人都知道,重复的代码是万恶之源,那么有没有办法在不写重复代码的前提下,用一种简单优雅的方式记录下函数的执行时间呢?在Python中,装饰器就是解决这类问题的最佳选择。我们可以把记录函数执行时间的功能封装到一个装饰器中,在有需要的地方直接使用这个装饰器就可以了,代码如下所示。
import time
import random
# 定义装饰器函数,它的参数是被装饰的函数或类
def record_time(func):
# 定义一个带装饰功能(记录被装饰函数的执行时间)的函数
# 因为不知道被装饰的函数有怎样的参数所以使用*args和**kwargs接收所有参数
# 在Python中函数可以嵌套的定义(函数中可以再定义函数)
def wrapper(*args, **kwargs):
# 在执行被装饰的函数之前记录开始时间
start = time.time()
# 执行被装饰的函数并获取返回值
result = func(*args, **kwargs)
# 在执行被装饰的函数之后记录结束时间
end = time.time()
# 计算和显示被装饰函数的执行时间
print(f'{func.__name__}执行时间: {end - start:.3f}秒')
# 返回被装饰函数的返回值(装饰器通常不会改变被装饰函数的执行结果)
return result
# 返回带装饰功能的wrapper函数
return wrapper
def download(filename):
print(f'开始下载{filename}.')
time.sleep(random.randint(2, 6))
print(f'{filename}下载完成')
def upload(filename):
print(f'开始上传{filename}.')
time.sleep(random.randint(4, 8))
print(f'{filename}上传完成.')
download = record_time(download)
upload = record_time(upload)
download('MySQL从删库到跑路.avi')
upload('Python从入门到住院.pdf')

上面的代码中已经没有重复代码了,虽然写装饰器会花费一些心思,但是这是一个一劳永逸的骚操作,如果还有其他的函数也需要记录执行时间,按照上面的代码如法炮制即可。
2.递归调用
Python中允许函数嵌套定义,也允许函数之间相互调用,而且一个函数还可以直接或间接的调用自身。函数自己调用自己称为递归调用,那么递归调用有什么用处呢?现实中,有很多问题的定义本身就是一个递归定义,例如我们之前讲到的阶乘,非负整数N的阶乘是N乘以N-1的阶乘,即$ N! = N \times (N-1)! $,定义的左边和右边都出现了阶乘的概念,所以这是一个递归定义。既然如此,我们可以使用递归调用的方式来写一个求阶乘的函数,代码如下所示。
def fac(num):
if num in (0, 1):
return 1
return num * fac(num - 1)
上面的代码中,fac函数中又调用了fac函数,这就是所谓的递归调用。代码第2行的if条件叫做递归的收敛条件,简单的说就是什么时候要结束函数的递归调用,在计算阶乘时,如果计算到0或1的阶乘,就停止递归调用,直接返回1;代码第4行的num * fac(num - 1)是递归公式,也就是阶乘的递归定义。下面,我们简单的分析下,如果用fac(5)计算5的阶乘,整个过程会是怎样的。
# 递归调用函数入栈
# 5 * fac(4)
# 5 * (4 * fac(3))
# 5 * (4 * (3 * fac(2)))
# 5 * (4 * (3 * (2 * fac(1))))
# 停止递归函数出栈
# 5 * (4 * (3 * (2 * 1)))
# 5 * (4 * (3 * 2))
# 5 * (4 * 6)
# 5 * 24
# 120
print(fac(5)) # 120
注意,函数调用会通过内存中称为“栈”(stack)的数据结构来保存当前代码的执行现场,函数调用结束后会通过这个栈结构恢复之前的执行现场。栈是一种先进后出的数据结构,这也就意味着最早入栈的函数最后才会返回,而最后入栈的函数会最先返回。例如调用一个名为a的函数,函数a的执行体中又调用了函数b,函数b的执行体中又调用了函数c,那么最先入栈的函数是a,最先出栈的函数是c。每进入一个函数调用,栈就会增加一层栈帧(stack frame),栈帧就是我们刚才提到的保存当前代码执行现场的结构;每当函数调用结束后,栈就会减少一层栈帧。通常,内存中的栈空间很小,因此递归调用的次数如果太多,会导致栈溢出(stack overflow),所以递归调用一定要确保能够快速收敛。我们可以尝试执行fac(5000),看看是不是会提示RecursionError错误,错误消息为:maximum recursion depth exceeded in comparison(超出最大递归深度),其实就是发生了栈溢出。
我们使用的Python官方解释器,默认将函数调用的栈结构最大深度设置为1000层。如果超出这个深度,就会发生上面说的RecursionError。当然,我们可以使用sys模块的setrecursionlimit函数来改变递归调用的最大深度,例如:sys.setrecursionlimit(10000),这样就可以让上面的fac(5000)顺利执行出结果,但是我们不建议这样做,因为让递归快速收敛才是我们应该做的事情,否则就应该考虑使用循环递推而不是递归。
再举一个之前讲过的生成斐波那契数列的例子,因为斐波那契数列前两个数都是1,从第3个数开始,每个数是前两个数相加的和,可以记为f(n) = f(n - 1) + f(n - 2),很显然这又是一个递归的定义,所以我们可以用下面的递归调用函数来计算第n个斐波那契数。
def fib(n):
if n in (1, 2):
return 1
return fib(n - 1) + fib(n - 2)
# 打印前20个斐波那契数
for i in range(1, 21):
print(fib(i))

需要提醒大家,上面计算斐波那契数的代码虽然看起来非常简单明了,但执行性能是比较糟糕的,原因大家可以自己思考一下,更好的做法还是之前讲过的使用循环递推的方式,代码如下所示。
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a
总结
装饰器是Python中的特色语法,可以通过装饰器来增强现有的函数,这是一种非常有用的编程技巧。一些复杂的问题用函数递归调用的方式写起来真的很简单,但是函数的递归调用一定要注意收敛条件和递归公式,找到递归公式才有机会使用递归调用,而收敛条件确定了递归什么时候停下来。函数调用通过内存中的栈空间来保存现场和恢复现场,栈空间通常都很小,所以递归如果不能迅速收敛,很可能会引发栈溢出错误,从而导致程序的崩溃。















 3260
3260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









