






1. 背景知识
相关知识点的细节论述在网络上汗牛充栋,不再赘述,笔者尽量用最简明概括的文字带大家快速复习一下。
1.1 数据的序列化和反序列化:
1.1.1
序列化(Serialization): 将数据结构转换为线性格式(如字节流、字符串)的过程,以便在存储或传输时使用。序列化后的数据可以被写入文件、传输到其他系统,或者在稍后的时间点进行反序列化以还原成原始数据结构。反序列化(Deserialization): 将序列化后的线性格式数据转换回原始的数据结构的过程。反序列化将线性格式数据解析并恢复为原始数据的层次结构,使其可以在程序中进一步处理和操作。常见的对数据的序列化和反序列化操作主要有 JSON Encode/Decode,XML Encode/Decode,Message Pack Encode/Decode 等等。
1.1.2
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于前端和后端之间的数据传输以及数据存储。JSON Encode 是将数据结构(通常是对象或数组)转换为 JSON 格式的字符串,以便在网络传输或存储中使用。JSON Decode 是将 JSON 格式的字符串解析为数据结构,通常是对象或数组,在程序中进行处理和操作。
1.1.3
XML(eXtensible Markup Language)是一种标记语言,用于描述和存储数据以及传输数据。XML Encode 是将数据转换为 XML 格式的字符串,通过定义标签和结构来表示数据的层次结构。XML Decode 是将 XML 格式的字符串解析为数据,恢复数据的层次结构和内容。
1.2 数据的加解密:
数据加密是将原始数据转换为密文,以保护数据的隐私和安全。解密是将密文转换回原始数据。这可以被视为编码(加密)和解码(解密)的过程,将数据从可读的形式转换为不可读的形式(密文),然后再从密文还原为原始可读的形式。在加解密过程中,算法和密钥是关键的组成部分。
1.3 数据的压缩和解压:
数据压缩是通过消除数据中的冗余信息,减小数据的大小,以节省存储空间或提高传输效率。解压是将压缩后的数据恢复到原始大小和形式。这也可以被视为编码(压缩)和解码(解压)的过程,将数据从较大的形式转换为较小的形式,然后再从较小的形式还原为原始较大的形式。在数据压缩中,常见的方法包括无损压缩(如gzip、zlib)和有损压缩(如JPEG、MP3)。
1.4 数据的 Encode 和 Decode:
以上对数据的序列化和反序列化操作,以及对数据的加解密,压缩和解压,本质上都属于数据的编码(encode)和解码(decode)的过程。尽管加解密、压缩和解压通常涉及更多复杂的数学和算法,但从概念上来说,它们可以被视为广义上数据的编码和解码过程,即从一种形式转换为另一种形式,以达到数据保护、存储优化或传输效率的目的。狭义上涉及网络编程时常说的编码(encode)和解码(decode)主要包括:
1.4.1
Base64 Encode/Decode: 将二进制数据编码为 Base64 格式的文本,以便在文本环境中传输,然后可以解码回二进制形式。Base64 编码后的数据长度通常比原始数据要长,因为每 3 个字节的数据编码为 4 个字符。但它的优点是可以在文本环境中传输二进制数据,同时避免了可能引起解析问题的特殊字符。
例如 <"hello // world"> 经过 Base64 Encode 之后就变为了 PCJoZWxsbyAvLyB3b3JsZCI+
1.4.2
URL Encode/Decode: 将特殊字符和非安全字符转换为 URL 安全格式,以便在 URL 中传输,然后可以解码回原始格式。URL 编码和解码保证了数据在 URL 中的传输和解析的准确性,但也会导致 URL 变得更长。在 Web 开发中,URL 编码和解码是非常常见的操作。
例如 https://www.test.com/p.php?username=你好&password=!@#$%^&*()
在 URL Encode 之后就变为了
https%3A%2F%2Fwww.test.com%2Fp.php%3Fusername%3D%E4%BD%A0%E5%A5%BD%26password%3D!%40%23$%25%5E%26*()
1.4.3
HTML Entity Encode/Decode: 将特殊字符和符号编码为 HTML 实体,以避免在 HTML 文档中引起解析问题,然后可以解码回原始字符。HTML 实体编码和解码是确保在 HTML 文档中显示特殊字符和保留字符正确的一种方法。在 Web 开发中,它对于保证文档正确性和安全性非常重要。例如,小于号:< 编码为 < 大于号:> 编码为 > 引号:" 编码为 " 空格:空格 编码为
1.4.4
Unicode Encode/Decode: 将字符编码为 Unicode 编码的十六进制表示形式,然后可以解码回字符。Unicode 目前主要有以下几种主流的编码方案:
1.4.4.1
UTF-8(Unicode Transformation Format - 8-bit): UTF-8 是一种变长的编码方案,最初设计用于在互联网上传输数据。它在 ASCII 字符上保持了兼容性,每个 ASCII 字符使用 1 个字节,非 ASCII 字符使用多个字节。UTF-8 是广泛使用的编码方案,因为它在存储和传输时既具有高效性又能够处理多语言字符。
1.4.4.2
UTF-16(Unicode Transformation Format - 16-bit): UTF-16 采用 16 位(2 字节)的编码单元来表示字符,用于表示 Unicode 中的字符。它适合表示 BMP(Basic Multilingual Plane,基本多文种平面)中的字符,但在处理非 BMP 区域的字符(如一些辅助平面字符)时,需要使用两个 16 位编码单元。UTF-16 在一些系统和编程语言中被广泛使用。
1.4.4.3
UTF-32(Unicode Transformation Format - 32-bit): UTF-32 使用 32 位(4 字节)的编码单元表示每个字符,无论其在 BMP 还是辅助平面。UTF-32 简单明了,每个字符的编码长度固定,但也因此可能会造成存储空间的浪费。
1.4.4.4
BMP(Basic Multilingual Plane,基本多文种平面)是 Unicode 编码空间中的第一个平面,包含了大部分常用的字符,涵盖了许多语言的字母、数字、符号以及一些特殊字符。以下是一些 BMP 区域的字符例子:
-
拉丁字母:
- 英文字母 A、B、C 等。
- 德语中的 umlaut 字母如 Ä、Ö、Ü。
- 法语中的字母如 é、ç。
-
数字和标点符号:
- 数字 0 到 9。
- 常见的标点符号如 .、,、!、?。
-
常见符号:
- @、#、$、%、&、* 等常见符号。
- ¥、€、£ 等货币符号。
-
常用汉字:
- 中文汉字 "一"、"二"、"三" 等。
- 常见的汉字如 "人"、"好"、"大" 等。
-
其他字符:
- 符号如 +、-、= 等。
- 控制字符如换行、制表符等。
这些字符覆盖了许多语言和领域,是常见文本处理中使用的字符。BMP 以外的字符位于 Unicode 编码空间的辅助平面(Supplementary Planes),用于表示一些特殊的字符、表情符号、历史文化遗产和其他符号。以下是一些 BMP 以外的字符例子:
-
表情符号:各种表情符号:

-
辅助语言字符:一些不常见的语言中的字符,如某些非拉丁文字、象形文字等。
-
数学符号和专用符号:数学公式、特殊符号和数学记号,如 ∞、∑、∫。
-
历史和文化符号:古代文字、象形文字、神话和历史人物等的符号。
-
技术符号:电脑符号、科学符号、技术图标等。
-
其他特殊符号:如音符、箭头、几何图形、特殊符号等。
这些字符通常不在 BMP 内,因为 BMP 被用来表示常见的字符和基本多文种字符,而辅助平面用于扩展字符集,以满足更多特定领域的需求。辅助平面的字符通常需要更多的字节来表示,因为它们不适合在 BMP 内进行编码。
1.4.4.5
以上三种UTF-X编码方式各有特点。UTF-32最大的特点就是简单明了,每个字符的编码长度固定,但因此造成存储空间的浪费也是其最大的缺点。另外经常被讨论的问题是,为什么要同时设计出 UTF-8 和 UTF-16 这两种看似都能涵盖世界上所有字符的编码方式。UTF-8 是最早产生的一种 Unicode 编码方案。随后又设计出 UTF-16 的主要原因之一是为了解决 UTF-8 在处理 BMP 以外的字符时可能存在的编码长度问题。虽然 UTF-8 在存储和传输方面具有一定的优势,但在处理 BMP 以外的字符时,UTF-8 可能会需要使用多个字节表示一个字符,导致编码长度的不确定性。UTF-16 作为一种定长编码,可以更方便地处理 BMP 以外的字符。UTF-16 的使用在一些特定的应用和平台上具有优势,但在其他情况下可能会导致编码过度浪费空间。因此,UTF-16 并不适用于所有场景。UTF-8 作为一种变长编码,可以在大多数情况下同时提供高效的存储和传输效率,因此它在互联网和许多存储和通信应用中得到广泛应用。选择使用哪种编码方式取决于应用需求和特定情况的考虑。再啰嗦一下——UTF-8采用的是变长码的方式,大量 Unicode 表示的英文字母,数字,符号等被有效地转换为单字节,其余的根据需要转换为双字节或者三字节。总之就是为了减少大量“0”的传输!
1.5 数据的字符集转换:
敲重点!之所以把这一节放到最后,是因为字符集转换不同于数据的 Encode/Decode 概念。通常它是把经过某种 Encode 类型后的字符串转换为另一种 Encode 类型的字符串,用于接下来的计算、传输或者存储。在Windows C++编程中,常见的字符集转换类型包括:
-
UTF-8 到 UTF-16/UTF-32 的转换: 将 UTF-8 编码的字符串转换为 UTF-16 或 UTF-32 编码的字符串,或者反之。
-
本地字符集到 Unicode 的转换: 将系统本地字符集(如 ANSI、GBK、Shift-JIS 等)编码的字符串转换为 Unicode 编码的字符串,或者反之。
-
不同 Unicode 编码之间的转换: 将 UTF-16 编码的字符串转换为 UTF-8 编码的字符串,或者反之。
-
HTML 实体编码的转换: 将 HTML 实体编码的字符(如 &、< 等)转换为对应的 Unicode 字符,或者反之。
-
URL 编码的转换: 将 URL 编码的字符串(如 %20、%3D 等)转换为对应的 Unicode 字符,或者反之。
常用的用来处理字符集转换的 Windows API 和 C++ 库包括:
-
stringapiset.h头文件中的函数主要用于字符集转换和字符串处理,在 Windows 环境中用于处理宽字符和多字节字符之间的转换,以及不同字符集之间的转换。例如 WideCharToMultiByte 和 WideCharToMultiByte。 -
C++ 标准库:
std::wstring_convert:C++11 引入的标准库类,用于在不同的字符集之间进行转换。 -
Boost 库:Boost 提供了
boost::locale::conv命名空间中的函数,用于字符集转换,例如utf_to_utf、from_utf等。 -
ICU(International Components for Unicode)库:ICU 是一个强大的国际化和 Unicode 处理库,提供了丰富的字符集转换和文本处理功能。
-
Qt 文本编码类: Qt 框架提供了用于处理字符集转换的类,例如
QTextCodec,用于在不同的字符集之间进行转换。
2. 实战分析:
CHAR* m_pData;
{
// m_pData 接收到一个 UTF-8 字符串;
}
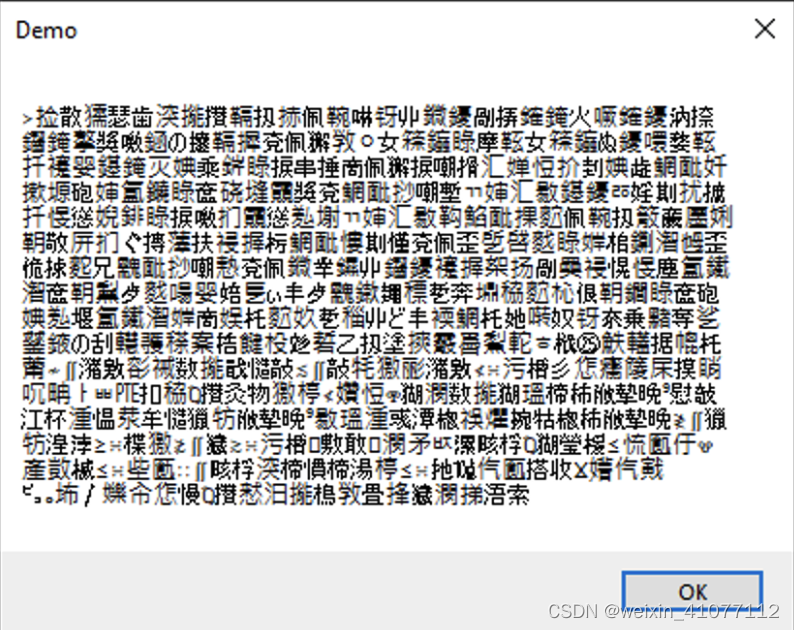
::MessageBox(NULL, (LPCWSTR)m_pData, _T("Demo"), MB_OK);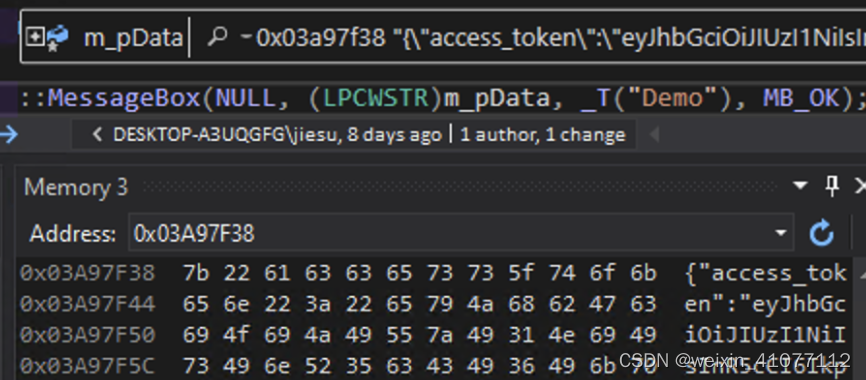
CHAR* m_pData;
{
// m_pData 接收到一个 UTF-8 字符串;
}
CComBSTR bstrData = UNI_UTF2W(m_pData);
::MessageBox(NULL, bstrData.m_str, _T("Demo"), MB_OK);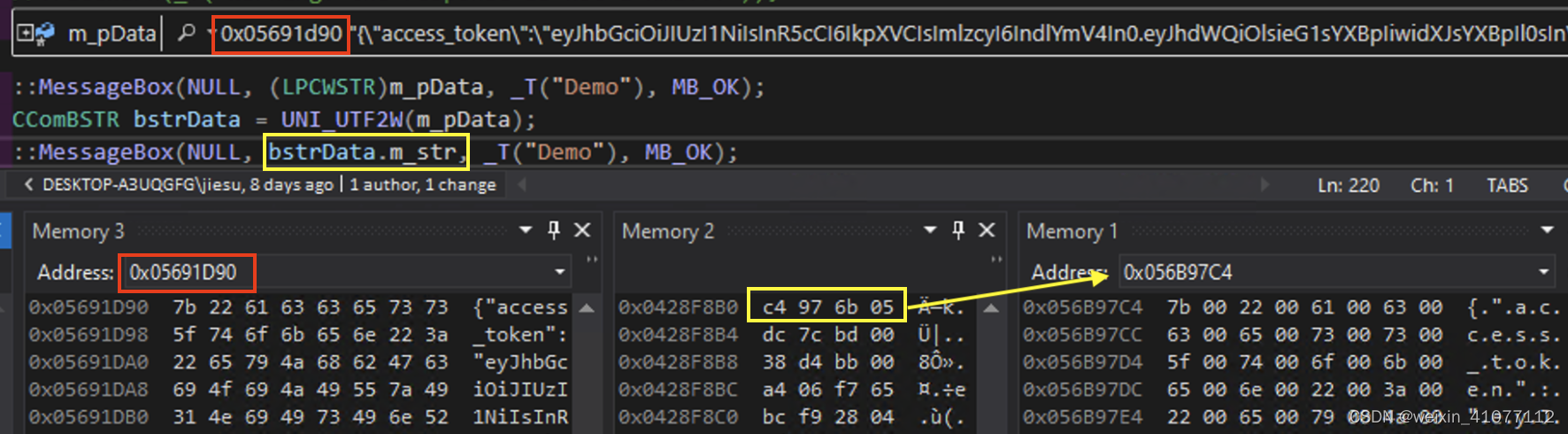

比较两段代码的执行结果,可以很直观的看出来如果传入的字符串格式和接收方默认的格式不兼容的话,就会导致程序处理出错。所以在第一段程序中,即使强制转换了 m_pData 的指针类型为 LPCWSTR 使得最终编译通过,但其实并没有改变所指向字符串的格式。
此外需要说明一下的是CComBSTR 构造函数会检测 char* 字符串的编码,如果检测到是多字节字符集(如 UTF-8),会自动将这些字符转换为宽字符(UTF-16)格式。转换为宽字符后,CComBSTR 会分配足够的内存以容纳宽字符格式的字符串,并将转换后的字符串复制到该内存中。也就是说第二段代码里即使没有将 m_pData 所指向的 UTF-8 字符串显式地转换成宽字符,CComBSTR 自己也会隐式地去做这件事。
3. 总结:
可见在真实的应用场景中,看似简单的一小段发送方的文字在最终到达接收方之前,需要经历不断发生的各种 “Encode/Decode”、“字符集转换”、“数据的序列化和反序列化”、“数据的加解密”等等各种针对原始数据的操作,一旦某个环节处理不当,最后就可能导致在终端显示成通常所谓的“乱码”。
根据笔者的实际经验,以上针对数据的各种操作类型当中,字符集转换是最容易产生 Bug 的类型。其主要原因是因为其他操作类型一般都是在单个模块内部成对出现,而且都会比较“显眼”地出现,在实际研发过程当中往往是一个程序员独立完成的工作量,所以不容易疏漏相关操作。但是数据的字符集转换却往往出现在各模块之间,并喜欢“隐藏”在代码的字里行间。例如,前端在把数据发给网络层之前可能会忘记转换成UTF8、某个模块在接收到第三方传来的数据之后没有及时转换成Unicode就直接进行下一步操作。
那么针对这些原因,Coding 阶段有效审查和避免,以及测试阶段设计出有针对性的测试Case 就显得非常重要,这里给出笔者的一些建议。
写代码时要时刻提醒自己,有没有弄清楚上游模块传递给你的参数是什么字符集的,你本地代码正常处理的是什么字符集,有没有对所有待处理字符串都执行了必要的转换,你的下游模块和你约定的输出字符集是什么,你有没有在所有出口处都正确的执行了,等等。
要厘清被测试对象所涉及到的所有接口调用。包括但不限于比如网络 API 接口,各个子模块,子系统之间暴露的对外接口,这些接口所有可以带入参数的地方,多试试非 ASCII 码字符输入,总之对于 BMP 和 BMP 以外的字符,只要输入的时候没有被禁止,然后就可以跟踪这个输入的内容最终在系统的其它地方能不能被正确显示。比如某应用注册账号的时候昵称里包含了☺和😁,并注册成功,那么在不同浏览器的网页上,iOS 和 Android 系统的手机App上,Windows 和 Mac 的桌面应用端,甚至于关联到其它第三方硬件设备的时候是不是都可以正常显示昵称呢?
本篇主要介绍原始数据在应用层的分析,其实小小的一段数据在整个传输过程中所经历的转换远远不止这些方面。例如从OSI7层模型和TCP/IP5层模型的角度,基于不同的网络协议又可以写出一篇关于数据从文本数据到二进制之间各种转换和传输过程的长文,当然此内容就不是本篇所介绍的范围了。
4. 附赠彩蛋:
再次提问一些容易混淆的概念和有意思的问题!看看你有没有头大,考察你掌握的究竟如何,有没有去多找些相关资料来学习😁。比如,什么是宽字符集?什么是窄字符集?什么是变长字符集?什么是多字节字符集?什么是ANSI?它们和 Unicode 又是什么关系?UTF-8 是窄字符集吗?计算机在解析 UTF-8 这样的变长编码的时候什么怎么识别接下来的内容是占用1个字节,2个字节,3个字节或者更多字节的呢?
-
Windows 操作系统中确实存在窄字符(Narrow Characters)的概念,这是与宽字符(Wide Characters)相对的概念。在 Windows 中,宽字符通常是以 UTF-16 编码的,每个字符占用 2 个字节。宽字符用于支持 Unicode 字符集,并在许多 Windows API 中广泛使用。而窄字符通常指的是多字节字符(Multibyte Characters),也称为 ANSI 字符,它们使用变长编码方案,可以是各种字符集编码(如 Windows-1252、GBK 等)。
-
ANSI(American National Standards Institute,美国国家标准学会)也可以是一种变长编码格式,具体取决于使用的字符集。ANSI 并不是一个具体的字符集,而是一个标准化的组织。在 Windows 系统中,"ANSI" 通常指的是 Windows-1252 字符集,它是一个单字节编码,包含了许多西欧语言中使用的字符。
- UTF-8 是一种变长字符编码方案,它以字节为单位存储字符,根据字符的不同范围,使用不同数量的字节。
- Unicode 为每个字符分配唯一的标识码,包括汉字。汉字的 Unicode 编码通常使用 4 个十六进制数字来表示,例如 "中" 的 Unicode 编码是 U+4E2D。这个编码占用了 2 个字节(16 位)。
- UTF-8 是一种变长字符编码,它根据字符的不同范围使用不同数量的字节。在 UTF-8 中,汉字通常占用 3 个字节。例如,"中" 的 UTF-8 编码是
E4 B8 AD,使用了 3 个字节。部分较少使用的汉字可能会占用更多的字节。 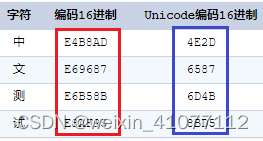

- UTF-8 编码是一种变长编码,它的设计使得在存储拉丁字母、数字和基本符号等常见字符时,占用的字节与 ASCII 编码相同(即 1 个字节),而对于较少使用的字符,如汉字,会占用更多的字节。这就是在网络传输和存储的时候更多的使用 UTF-8 格式的原因。
- 汉字的 Unicode 编码通常占用 2 个字节,而在 UTF-8 编码中,汉字的编码通常占用 3 个字节。但请注意,这只是一般情况,实际编码可能因具体的字符而有所不同。
-
Windows-1252 字符集不包含中文字符。Windows-1252 字符集是一种单字节编码,主要用于表示西欧语言中的字符。中文字符需要使用多字节编码,如 GBK、GB2312、UTF-8 或 UTF-16。
-
UTF-8 使用不同的位模式来表示不同字节数的字符:
- 对于占用 1 个字节的字符,UTF-8 使用 0xxxxxxx 的位模式,其中 x 表示字符的实际数据。
- 对于占用 2 个字节的字符,UTF-8 使用 110xxxxx 10xxxxxx 的位模式,其中 x 表示字符的实际数据。
- 对于占用 3 个字节的字符,UTF-8 使用 1110xxxx 10xxxxxx 10xxxxxx 的位模式,其中 x 表示字符的实际数据。
- 对于占用 4 个字节的字符,UTF-8 使用 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 的位模式,其中 x 表示字符的实际数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









