






InternetReadFile 是 Windows API 中的一个函数,用于从一个已经打开的 Internet 连接中读取数据。这个函数通常用于从通过 HTTP、FTP 或其他协议获取的网络资源(如网页、文件等)中读取数据。当你建立了一个 Internet 连接并尝试从中读取数据时,可以将这个过程想象成一个正在流动的水流,而 InternetReadFile 则是用来从这个水流中装水的容器。
-
初始情况: 开始时,Internet 连接中的数据流可能是空的,或者只有很少的数据。如果你调用
InternetReadFile并没有数据可读,它会等待,直到有数据可供读取或者发生错误返回FALSE。 -
数据的积累: 当网络连接从服务器获取数据时,这些数据会被逐步填充到数据流中,就像水流中的水不断流动一样。这些数据会在连接中被积累,直到你通过
InternetReadFile来读取它们。 -
InternetReadFile的作用: 当你调用InternetReadFile函数来读取数据时,它就像是一个水杯,用来从数据流中舀水(数据)。这个函数会从数据流中读取指定数量的字节,然后将这些字节存储到你提供的缓冲区中。 -
数据流的大小大于读取量: 如果数据流中的数据量远大于你通过
InternetReadFile设置的一次读取的量,那么在第一次读取时,它会从数据流中读取部分数据,填满你提供的缓冲区。然后,你可以再次调用InternetReadFile来继续读取剩余的数据。
总的来说,Internet 连接中的数据流是一个不断变化的、积累数据的过程。InternetReadFile 则是用来从这个数据流中读取数据,但它并不会改变数据流本身,只是将数据从流中读取到你的缓冲区中。如果数据流中的数据量超过了一次读取的量,你需要多次调用 InternetReadFile 来完全读取这些数据。
需要注意的另一个问题是,InternetReadFile 函数本身并不知道读取到的数据的编码方式(UTF-8、UTF-16、UTF-32等)。它只负责将从网络连接中读取的原始字节数据存储到 lpBuffer 所指向的内存中,而不会对数据的编码进行解析或转换。对于不同的编码,你接下来需要使用不同的方法和库来进行解码,以正确地处理这些数据。
BOOL InternetReadFile(
HINTERNET hFile,
LPVOID lpBuffer,
DWORD dwNumberOfBytesToRead,
LPDWORD lpdwNumberOfBytesRead
);hFile:一个已经打开的 Internet 连接句柄。lpBuffer:指向接收数据的缓冲区的指针。dwNumberOfBytesToRead:要读取的字节数。lpdwNumberOfBytesRead:指向一个变量的指针,用于接收实际读取的字节数。
返回值:
- 如果函数成功读取数据,则返回
TRUE,并且通过lpdwNumberOfBytesRead返回实际读取的字节数。 - 如果函数读取失败或出错,则返回
FALSE。可以通过调用GetLastError获取更多错误信息。
InternetReadFile 的函数原型如上所示,接下来让我们用一个具体的实验来客观比较一下,不同的缓冲区大小在面对不同的返回数据量时的表现。
#define DATA_BUFFER_SIZE (128 + 1)
#define DATA_BUFFER_SIZE (512 + 1)
#define DATA_BUFFER_SIZE (2*1024 + 1)
void CURLObject::StartGet()
{
DWORD startTime = ::GetTickCount(); //记录开始读取之前的时间戳
EmptyData();
while (TRUE)
{
if (m_bCanceled) { break; }
if (IsTimeOut()) { break; }
CHAR chBuffer[DATA_BUFFER_SIZE] = {0};
DWORD dwBufLen = DATA_BUFFER_SIZE - 1;
DWORD dwRead = 0;
if (!InternetReadFile(m_hRequest, chBuffer, dwBufLen, &dwRead)) { break; }
if (0 == dwRead) { break; }
if (m_bCanceled) { break; }
if (IsTimeOut()) { break; }
chBuffer[dwRead] = 0;
if (m_dwDataLen - m_dwDownloadedLen > dwRead)
{
CopyMemory(m_pData + m_dwDownloadedLen, chBuffer, dwRead);
m_dwDownloadedLen += dwRead;
}
else
{
CHAR* pOld = m_pData;
m_pData = new CHAR[m_dwDataLen + DATA_BUFFER_SIZE * 4 + 1];
if (m_pData == NULL)
{
m_pData = pOld;
}
else
{
SecureZeroMemory(m_pData, m_dwDataLen + DATA_BUFFER_SIZE * 4 + 1);
m_dwDataLen = m_dwDataLen + DATA_BUFFER_SIZE * 4;
if (pOld != NULL)
{
CopyMemory(m_pData, pOld, m_dwDownloadedLen);
CopyMemory(m_pData + m_dwDownloadedLen, chBuffer, dwRead);
m_dwDownloadedLen += dwRead;
delete[] pOld;
pOld = NULL;
}
else
{
CopyMemory(m_pData, chBuffer, dwRead);
m_dwDownloadedLen = dwRead;
}
}
}
}
DWORD endTime = ::GetTickCount(); //记录读取完成之后的时间戳
DWORD elapsedTime = endTime - startTime;
char elapsedTimeStr[256];
char bufferSizeStr[32];
snprintf(elapsedTimeStr, sizeof(elapsedTimeStr), "Elapsed Time: %lu milliseconds", elapsedTime);
snprintf(bufferSizeStr, sizeof(bufferSizeStr), "Buff: %d Data: %d", DATA_BUFFER_SIZE, strlen(m_pData));
::MessageBoxA(NULL, elapsedTimeStr, bufferSizeStr, MB_OK);
}| 返回数据量 | BUFFER_SIZE=2048 | BUFFER_SIZE=512 | BUFFER_SIZE=128 |
|---|---|---|---|
| 936 |
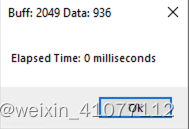
|

|

|
| 140,465 |

|

|

|
| 1,996,838 |
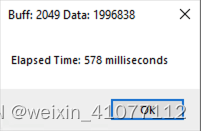
|

|
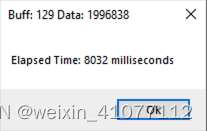
|
| 29,591,284 |

|
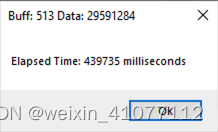
|

|

从实验中我们可以得到以下几个明显的结论:
- 在相同的网络速度、数据处理和内存使用情形下,接收数据的缓冲区设置的越小,越降低读取效率。可见读取数据时选用一个合适大小的“容器”就显得非常重要,否则大量的时间就耗费在不断舀水倒水的切换动作上,而不是舀水这个核心任务上了;
- A1\A2\A3、B1\B2\B3、C1\C2\C3三组数据横向比较(除后取整)。肉眼可见,实验中缓冲区大小设置为4倍呈阶梯减小(2048、512和128字节),对应的所耗费时间刚好大约为4倍呈阶梯增加;
- A1\B1\C1、A2\B2\C2、A3\B3\C3三组数据纵向比较(除后取整):
- 29591284/1996838=14;1996838/140465=14;
- 121812/578=210;578/1=578
- 439735/2250=195;2250/16=140
- 1774125/8032=220;8032/63=127
- 得到的客观结论可以归纳为:返回数据量十几倍的差距,却由于缓冲区大小设置不当,造成几百倍的差距;
- 对于 D1/D2/D3以及C1 这些数据客观说明了,当返回数据量在正常网络请求的几百字节到几千字节的时候,或者说缓冲区的设置不怎么影响“舀水倒水的切换次数”时,差别可以忽略不计。
所以是否可以在程序设计中尽可能地增大缓冲区的设置呢?其实也不尽然,缓冲区的设置参数的合适值取决于多个因素,包括网络连接速度、数据传输速率、内存使用和数据处理能力等。没有一个固定的经验值适用于所有情况,但可以根据以下考虑来选择合适的值:
-
网络速度: 如果网络速度较慢,可以考虑设置较小的
dwNumberOfBytesToRead值,以便更快地获取数据。如果网络速度较快,可以适当增加这个值,以减少读取次数。 -
数据处理: 如果读取的数据需要进行解码、分析、处理等操作,你需要根据处理数据所需的时间来选择合适的值。如果处理时间较长,可能需要适当减少一次读取的数据量。
-
内存使用: 一次性读取过多的数据量可能会占用大量内存。根据可用内存和应用的内存限制,选择适当的
dwNumberOfBytesToRead值。 -
数据流大小: 如果你知道从网络上读取的数据流通常的大小,可以根据这个估计来设置
dwNumberOfBytesToRead。
一般来说,dwNumberOfBytesToRead 可以设置为几百字节到几千字节,根据实际情况进行调整。你可以进行性能测试,在不同的场景下尝试不同的值,找到一个合适的平衡点,以满足数据获取的需求并保持合理的性能。















 9635
9635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









