







相比较之前的几个加解密实例,这一版使用 AES对称加解密实例所介绍的方法更具有实用性和参考价值,很适合保存客户本机的私密数据,不但用 Base64 Encode了自定义格式的密钥和密文合并字符串,增加了黑客解析出独立的密钥和密文的难度;而且还只能在执行加密操作的同一台机器上解密密文,实现了密钥隔离的策略;另外对其它的一些安全细节也做了增强处理。
新版 AES对称加解密实例直观感受:
这一版实例的直观感受如下。如果本地你有一段文字需要加密,执行加密后会将密钥,密文和一些参数的长度信息按照自定义的格式合并为一个字符串,最后将字符串进行 Base64 Encode并保存在指定注册表路径下。【图-2】中可以看到当前机器的IP地址为【10.224.70.204】,PID为【18536】。
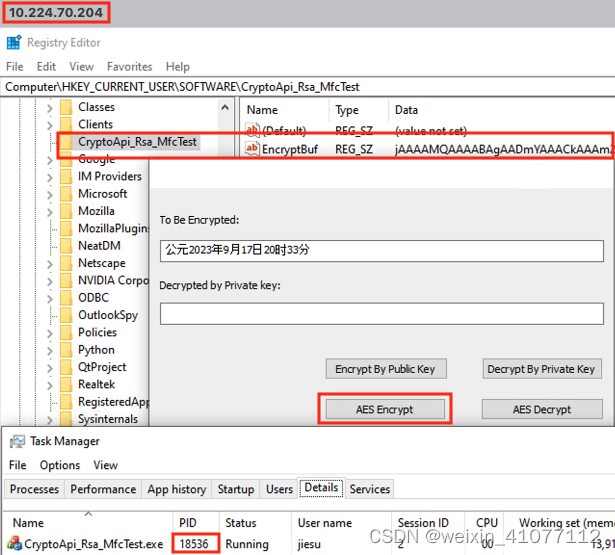
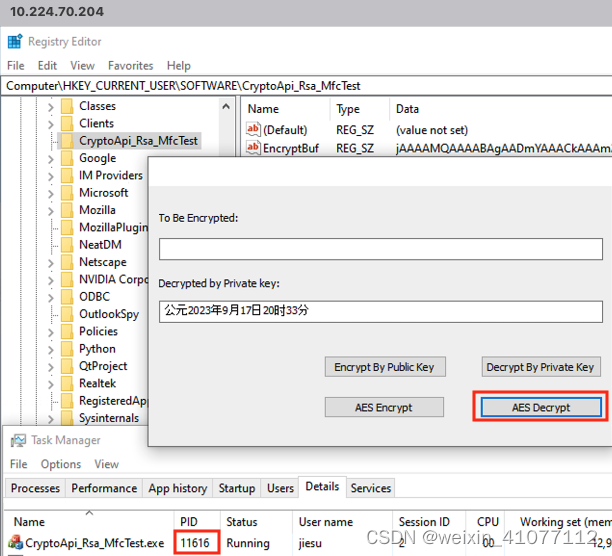
在【图-3】中可以观察到,同一台机器下,新进程的 PID为【11616】,在执行解密操作后很顺利地将明文再次输出。
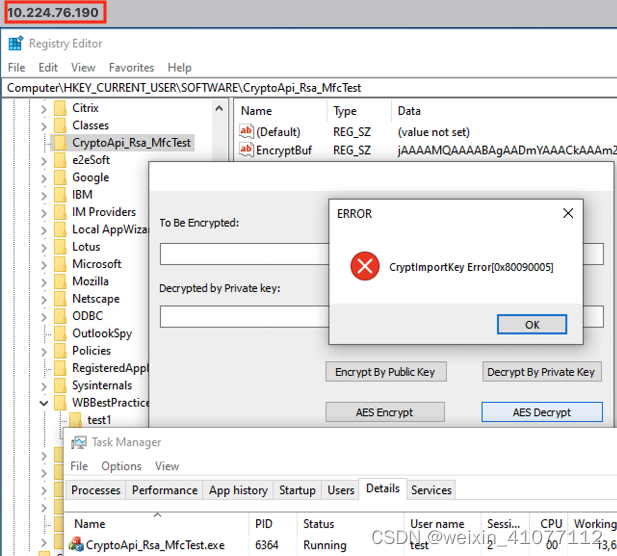
如果有人偷偷把加密保存的内容和测试程序统统拷贝到另一台机器上执行解密操作,会发现如【图-4】所示,程序会提示导入密钥失败,这也就印证了本文开头所说的密钥隔离的策略。
改进后的源码分析(加密部分):
// Create customized CSP container with current user SID and defined container name
// To reduce the risk of missing local container file and enhance the security, acquire CSP with customized name
// If CryptAcquireContext failure first time, delete keyset and try to create a new one
if (true == GetProcessSID(strSID))
{
strContainer = s_pszEnContainer;
strContainer += _T("_");
strContainer += strSID;
}
do
{
if (!CryptAcquireContext(&hCryptProv, strContainer.c_str(), MS_ENH_RSA_AES_PROV, PROV_RSA_AES, dwFlags))
{
ShowError("CryptAcquireContext");
if (!CryptAcquireContext(&hCryptProv, strContainer.c_str(), MS_ENH_RSA_AES_PROV, PROV_RSA_AES, CRYPT_DELETEKEYSET | dwFlags))
{
ShowError("CryptAcquireContext with CRYPT_DELETEKEYSET");
}
if (!CryptAcquireContext(&hCryptProv, strContainer.c_str(), MS_ENH_RSA_AES_PROV, PROV_RSA_AES, CRYPT_NEWKEYSET | dwFlags))
{
ShowError("CryptAcquireContext with CRYPT_DELETEKEYSET");
return;
}
}
// Cenerate exportable random session key
DWORD dwFlag = CRYPT_EXPORTABLE;
ALG_ID idAlg = CALG_AES_128;
if (!CryptGenKey(hCryptProv, idAlg, dwFlag, &hSessionKey))
{
ShowError("CryptGenKey");
return;
}
// Use CryptExportKey with CryptGetUserKey to export key that associated with specific users and computers
if (!CryptGetUserKey(hCryptProv, AT_KEYEXCHANGE, &hXchgKey))
{
ShowError("CryptGetUserKey");
if (!CryptGenKey(hCryptProv, AT_KEYEXCHANGE, 0, &hXchgKey))
{
ShowError("CryptGenKey with AT_KEYEXCHANGE");
return;
}
}
DWORD dwKeyBlobLen = 0;
if (!CryptExportKey(hSessionKey, hXchgKey, SIMPLEBLOB, 0, NULL, &dwKeyBlobLen))
{
ShowError("CryptExportKey to get key blob length");
return;
}
lpPubKey = new BYTE[dwKeyBlobLen];
if (!CryptExportKey(hSessionKey, hXchgKey, SIMPLEBLOB, 0, lpPubKey, &dwKeyBlobLen))
{
ShowError("CryptExportKey to get key");
break;
}与之前几个例程最大的不同之一在于,调用 CryptAcquireContext 接口时,指定了“pszContainer”(密钥容器的名称)和 “pszProvider”(密码学服务提供程序的名称)。这使得本例程不再使用默认容器和默认提供程序,而是使用自定义的名称创建属于自己的密钥文件。并且还增加了遇到密钥文件丢失意外时的冗余处理,即会尝试再次创建新的自定义密钥文件。其中自定义的密钥容器名称包括“自定义的容器名字”和“本机当前用户的 SID”两部分,增加了唯一性和安全性。如【图-5】所示:
还记得在之前的文章中曾经介绍过有客户的 VDI虚拟机由于配置原因而导致默认密钥文件丢失的问题吧?如果你的程序采用了自定义的密钥文件,并且增加了对密钥文件的冗余处理,那么在一定程度上会增加你程序的健壮性【图-6】。这也是产品级软件在研发阶段需要注意的问题,毕竟客户花银子买了你的软件,理应为客户提供更流畅的服务,而不是动辄就弹个提示框告诉客户,这也不行,那也不行。

实现密钥隔离策略的手段在于使用了 CryptGenKey 和 CryptGetUserKey 接口。CryptGetUserKey 函数与 AT_KEYEXCHANGE 参数一起使用的主要目的是获取用户的用于加密和解密操作的非对称密钥。通过 CryptGetUserKey 获取的密钥通常与特定的用户帐户和计算机相关联,因此无法在不同的计算机上使用相同的密钥。这是因为密钥的生成和存储通常受到操作系统和硬件安全性的保护,而且密钥的使用需要用户的身份验证。
CryptExportKey 函数用于导出密钥,以便将其存储在外部介质中。通常使用 SIMPLEBLOB 指定要导出的密钥的格式。 本质上导出的密钥是按字节存储在内存中的一段内容,所以我们要在栈上申请一个足够长的新缓冲区来暂时保存,并在随后的 CryptEncrypt 加密过程中使用它。
if (!CryptEncrypt(hSessionKey, 0, TRUE, 0, (LPBYTE)lpszSrcTemp, &dwUsedBuffSize, dwTotolBuffSize))
{
ShowError("CryptEncrypt");
break;
}
DWORD dwTotalSize = 0;
char* lpByteBase64 = NULL;
DWORD dwByteBase64 = 0;
// Customized format key, ciphertext and related string length
// KeyLen(4) + TotalLen(4) + Key + ciphertext
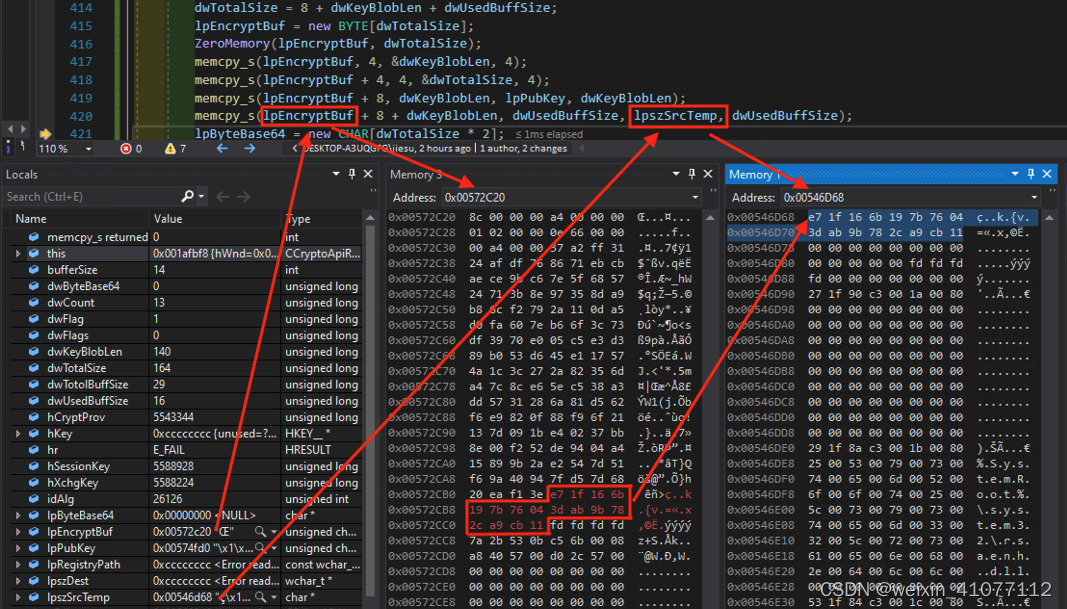
dwTotalSize = 8 + dwKeyBlobLen + dwUsedBuffSize;
lpEncryptBuf = new BYTE[dwTotalSize];
ZeroMemory(lpEncryptBuf, dwTotalSize);
memcpy_s(lpEncryptBuf, 4, &dwKeyBlobLen, 4);
memcpy_s(lpEncryptBuf + 4, 4, &dwTotalSize, 4);
memcpy_s(lpEncryptBuf + 8, dwKeyBlobLen, lpPubKey, dwKeyBlobLen);
memcpy_s(lpEncryptBuf + 8 + dwKeyBlobLen, dwUsedBuffSize, lpszSrcTemp, dwUsedBuffSize);
lpByteBase64 = new CHAR[dwTotalSize * 2];
if (NULL == lpByteBase64)
{
ShowError("lpByteBase64 is null");
break;
}
ZeroMemory(lpByteBase64, dwTotalSize * 2);
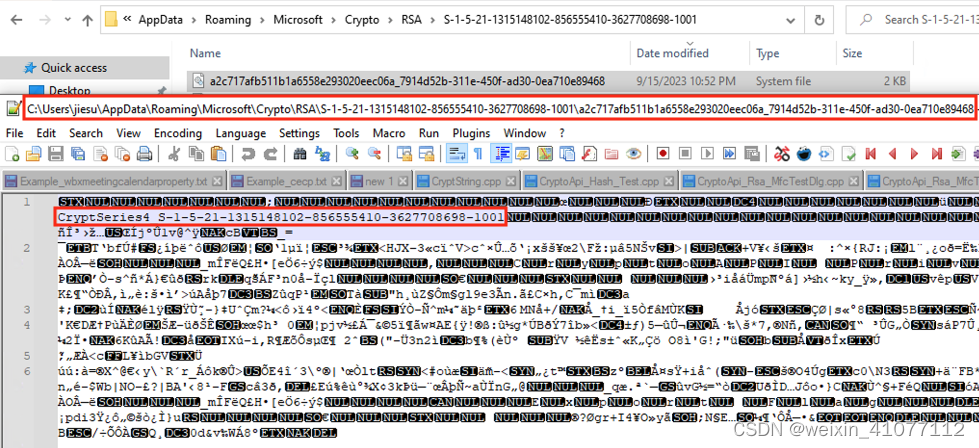
dwByteBase64 = Base64Encode(lpByteBase64, (CHAR*)lpEncryptBuf, dwTotalSize);本例中自定义的密钥和密文合并字符串格式为【密钥长度(4) + 整个缓冲区长度(4) + 密钥内容 + 密文内容】,在获取到密钥和密文之后,申请一个足够长的缓冲区(按BTYE为单位申请)来存储以上四部分内容。其中开头的8个字节用来存储两个DWORD类型,分别为密钥长度和整个缓冲区长度。后续分别存储的密钥内容和密文内容,密文的长度就是整个缓冲区的长度减去8,再减去密钥的长度,如【图-7】所示。最后整个缓冲区内容可以在 Base64 Encode之后被持久化到文件或注册表中。
改进后的源码分析(解密部分):
lpSrcBuf = new BYTE[nLen];
int iTotalSrcLen = 0;
if (lpSrcBuf != NULL)
{
ZeroMemory(lpSrcBuf, nLen);
iTotalSrcLen = Base64Decode((char*)lpSrcBuf, lpszSource, strlen_safe(lpszSource));
}
else
{
AfxMessageBox(_T("OnBnClickedBtnAesDe lpSrcBuf is NULL"), MB_ICONERROR);
break;
}
std::wstring strSID;
std::wstring strContainer;
if (true == GetProcessSID(strSID))
{
strContainer = s_pszDeContainer;
strContainer += _T("_");
strContainer += strSID;
}
if (!CryptAcquireContext(&hCryptProv, strContainer.c_str(), MS_ENH_RSA_AES_PROV, PROV_RSA_AES, dwFlags))
{
ShowError("CryptAcquireContext");
break;
}
// Adopt customized format key, ciphertext and related string length
// KeyLen(4) + TotalLen(4) + Key + PlainText
DWORD dwBlobSize = 0;
memcpy_s(&dwBlobSize, 4, lpSrcBuf, 4);
if (dwBlobSize >= iTotalSrcLen - 8)
{
AfxMessageBox(_T("OnBnClickedBtnAesDe: error in dwBlobSize >= iTotalSrcLen - 8"), MB_ICONERROR);
break;
}
DWORD dwTotalSize = 0;
memcpy_s(&dwTotalSize, 4, lpSrcBuf + 4, 4);
if (iTotalSrcLen != dwTotalSize)
{
AfxMessageBox(_T("OnBnClickedBtnAesDe: error in iTotalSrcLen != dwTotalSize"), MB_ICONERROR);
break;
}
if (!CryptImportKey(hCryptProv, lpSrcBuf + 8, dwBlobSize, 0, 0, &hSessionKey))
{
ShowError("CryptImportKey");
break;
}
LPBYTE lpSrcEncrpt = lpSrcBuf + 8 + dwBlobSize;
DWORD dwEncrptBufSize = dwTotalSize - 8 - dwBlobSize;
if (!CryptDecrypt(hSessionKey, 0, TRUE, 0, lpSrcEncrpt, &dwEncrptBufSize))
{
ShowError("CryptDecrypt");
break;
}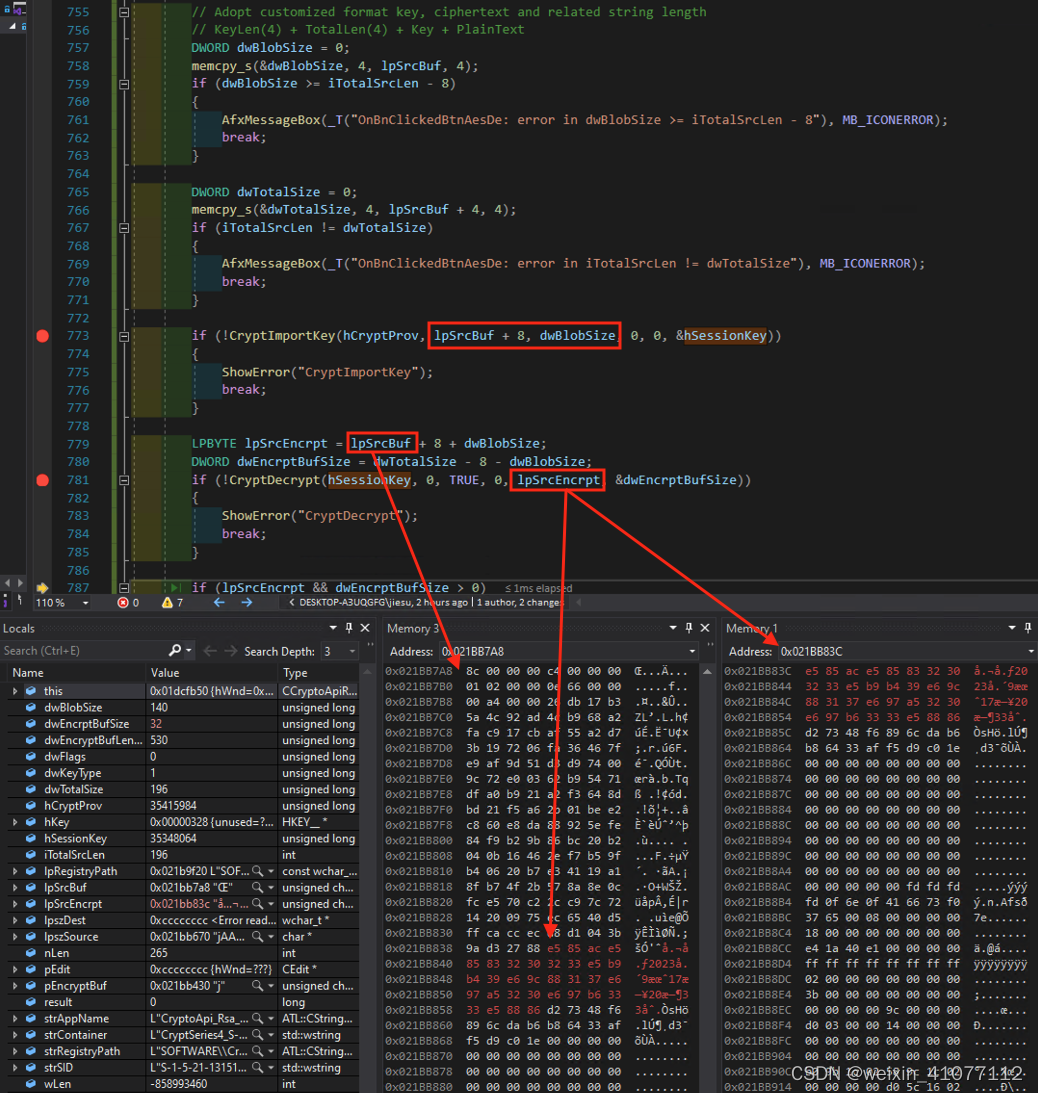
如【图-8】所示,异步的解密程序在读出持久化的内容后,按照约定好的格式反向读出密钥和密文,再通过自定义的密钥容器来执行解密操作。可以很清楚地看到,内存中解密后的内容的编码,正是明文字符对应的 UTF-8 格式的编码。如果输出的地方需要宽字符集,那么还要对明文内容做一次 UTF8 的转码操作。
| 字符 | 编码10进制 | 编码16进制 | Unicode编码10进制 | Unicode编码16进制 |
| 公 | 15041964 | E585AC | 20844 | 516C |
| 元 | 15041923 | E58583 | 20803 | 5143 |
| 2 | 50 | 32 | 50 | 32 |
| 0 | 48 | 30 | 48 | 30 |
| 2 | 50 | 32 | 50 | 32 |
| 3 | 51 | 33 | 51 | 33 |
| 年 | 15055284 | E5B9B4 | 24180 | 5E74 |
| 9 | 57 | 39 | 57 | 39 |
| 月 | 15113352 | E69C88 | 26376 | 6708 |
| 1 | 49 | 31 | 49 | 31 |
| 7 | 55 | 37 | 55 | 37 |
| 日 | 15112101 | E697A5 | 26085 | 65E5 |
| 2 | 50 | 32 | 50 | 32 |
| 0 | 48 | 30 | 48 | 30 |
| 时 | 15112118 | E697B6 | 26102 | 65F6 |
| 3 | 51 | 33 | 51 | 33 |
| 3 | 51 | 33 | 51 | 33 |
| 分 | 15042694 | E58886 | 20998 | 5206 |
例程源代码请访问:https://github.com/345967018/WBBestPractice028CryptoApiRsaMfcTestEnhanced.git















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









