







 本文详细介绍了RNN、双向LSTM、Transformer及其变体BERT的工作原理和区别。RNN通过记忆单元处理序列信息,BRNN结合未来和过去上下文,双向LSTM增强了信息捕捉能力。Transformer通过自注意力机制解决了长序列信息丢失问题,而BERT则通过预训练和微调在NLP任务中取得了显著效果。
本文详细介绍了RNN、双向LSTM、Transformer及其变体BERT的工作原理和区别。RNN通过记忆单元处理序列信息,BRNN结合未来和过去上下文,双向LSTM增强了信息捕捉能力。Transformer通过自注意力机制解决了长序列信息丢失问题,而BERT则通过预训练和微调在NLP任务中取得了显著效果。
最近接到一些秋招面试,发现自己对于好多网络结构都模糊了,刚好最近在调研模型,就趁这个机会把之前的常见模型知识梳理一下。
主要参考文档:
https://jalammar.github.io/illustrated-transformer/
https://blog.csdn.net/jojozhangju/article/details/51982254
1.Recurrent Neural Network(RNN)
循环神经网络(RNN)指的是一个序列当前的输出与之前的输出也有关。具体的表现形式为网络会对前面的信息进行记忆,保存在网络的内部状态中,并应用于当前输出的计算中,即隐含层之间的节点不再无连接而是有链接的,并且隐含层的输入不仅包含输入层的输出还包含上一时刻隐含层的输出。
经典RNN结构在时间上进行展开:
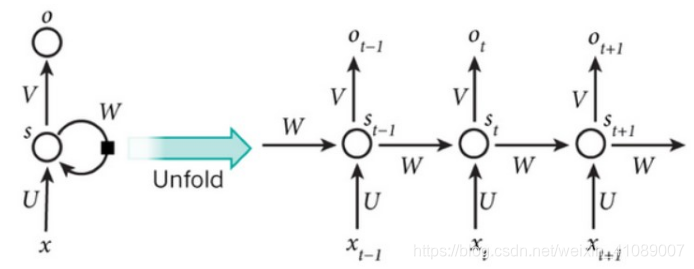
计算过程:

需要注意的是:
隐含层状态被认为是网络的记忆单元。包含了前面所有步的隐含层状态。而输出层的只与当前步的有关。在实践中,为了降低网络的复杂度,往往只包含前面若干步而不是所有步的隐含层输出。
这里体现出和传统神经网络的区别:
在传统的神经网络中,每一个网络层的参数是不共享的。而在RNN中,每输入一步,每一层各自都共享参数U,V,W,其反映着RNN每一步都在做相同的事情,只是输入不同。因此,这大大降低了网络中需要学习的参数。具体的说是,将RNN进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么到之间的U矩阵与到之间的U是不同的,但是RNN中却是一样的,同理对于隐含层与隐含层之间的W、隐含层与输出层之间的V也是一样的。
图中每一步都会有输出,但是每一步都要有输出并不是必须的。比如,我们需要预测一条语句所表达的情绪,我们仅仅需要关系最后一个单词输入后的输出,而不需要知道每个单词输入后的输出。同理,每步都需要输入也不是必须的。循环神经网络(RNN)的关键之处在于隐含层,隐含层能够捕捉序列的信息。
2.Bi-directional Recurrent Neural Network(BRNN)
如果能像访问过去的上下文信息一样,访问未来的上下文,这样对于许多序列标注任务是非常有益的。例如,在最特殊字符分类的时候,如果能像知道这个字母之前的字母一样,知道将要来的字母,这将非常有帮助。同样,对于句子中的音素分类也是如此。
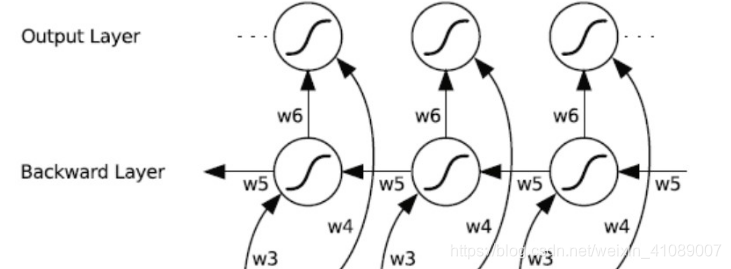
双向循环网络的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络,而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一个时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









