






2022年10月10日,在大数据集群跑任务,爆出超时错误,在同事建议下,增大broadcast join时长重跑程序。
Caused by: java.util.concurrent.TimeoutException: Futures timed out after [300 seconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:223)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:227)
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:220)
at org.apache.spark.sql.execution.exchange.BroadcastExchangeExec.doExecuteBroadcast(BroadcastExchangeExec.scala:146)
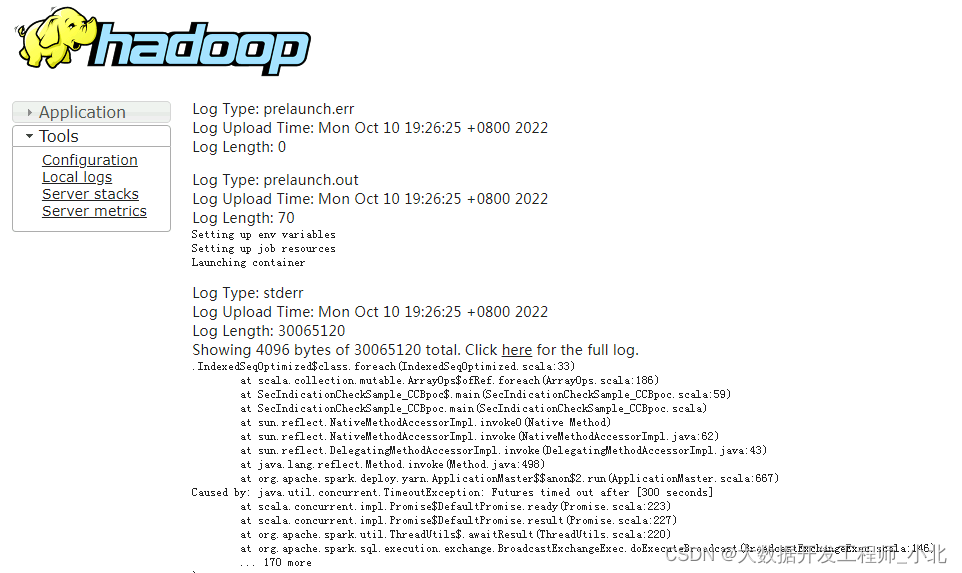

在等待期间,突然就有个疑问,这个broadcast不是广播变量吗,为什么这里会出现这个问题。代码中有倒是有加mapjoin优化,莫非spark on hive层面的mapjoin其实就是spark的广播变量?

1.mapjoin定义:mapjoin会把小表全部加载到内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,由于在map端是进行了join操作,省去了reduce运行的时间,算是hive中的一种优化。
2.所以这里的内存应该指的就是executor了,每个executor保存一份小表副本,再由executor下的task进行拉取,这里基本就是广播变量的原理了。

总结:1.优化场景:sql 场景小表需要left join大表,默认25m即是小表 2.使用方法:
select /*+ MAPJOIN(s) */ name,score from bigtable b join smalltable s
tips:RDD不可作为广播变量进行广播,为什么呢,下一篇见。















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









