







Python学习
Python Pandas库的学习
这篇文章主要就是关于python第三方库Pandas的一些基础学习,主要根据https://nbviewer.jupyter.org/github/MLEveryday/practicalAI-cn/blob/master/notebooks/03_Pandas.ipynb 来学习的
数据准备
在开始前将学习用到数据线导入到自己电脑中
在这里,如果按照课程中所写直接导入urllib包的话可能会报request方法的丢失,因此直接导入urllib.request,这样数据就直接存在项目默认文件夹下了。
import urllib.request
url = "https://raw.githubusercontent.com/GokuMohandas/practicalAI/master/data/titanic.csv"
response = urllib.request.urlopen(url)
html = response.read()
with open('titanic.csv', 'wb') as f:
f.write(html)
数据的输入输出
导入pandas库之后,为方便命名为pd,进行最基本的数据的输入输出。pandas支持多种格式数据的输入输出,excel、scv、fwf等,十分方便。
# 读取数据
df = pd.read_csv("titanic.csv", header=0)
# 输出数据
df.to_csv("titanic2.csv", index=False)
# 打印最初5行
print(df.head(5))
# 打印最后5行
print(df.tail(5))
作图
pandas中还支持对数据进行各种格式图形的制作与处理
在这里如果直接运行教程中的代码,会发现虽没有报错但无法显示图像出来,因此我们要show一下。
# 导入matplotitle包
import matplotlib.pyplot as plt
# 画直方图
print(df.describe())
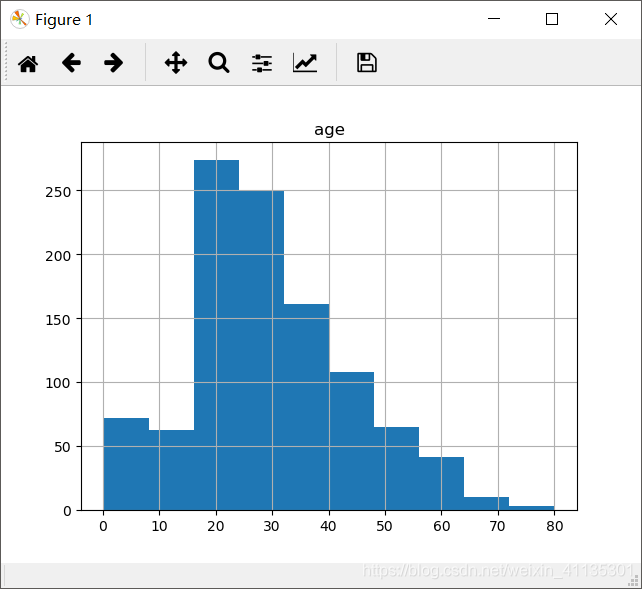
df.hist('age')
plt.show()
这样我们就可以看到这样一张age的直方图
简单的数据分析函数
pandas最重要的功能就是其基于numpy的数据分析功能,在这里我们只根据课程介绍几个最基本的函数,更多更详细的函数看官方库。
# 唯一值
print(df["embarked"].unique())
# 条件筛选
print(df[df["sex"] == "female"].head(5))
# 排序
print(df.sort_values("age", ascending=False).head(5))
# 分组及运算
sex_group = df.groupby("survived")
print(sex_group.mean())
# 根据索引提取,和matlab中方法一致
print(df.iloc[0, :])
print(df.iloc[0, 2])
# 根据标签的索引提取,注意iloc loc 和直接切片区别
print(df.loc[0, 'age'])
数据预处理
在进行正式的数据处理前一般会对数据进行预处理,以下是pandas一些简单的预处理办法。
# 具有至少一个nan的值
print(df[pd.isnull(df).any(axis=1)].head(5))
# 删除具有nan 的行
df = df.dropna() # 删除
df = df.reset_index() # 重新排序
print(df.head(5))
# 删除多行列
df = df.drop(["name", "cabin", "ticket"], axis=1)
print(df.head(5))
# 映射特征值,或者说是一种替换,在分组时候有用
df['sex'] = df['sex'].map({'female': 0, 'male': 1}).astype(int)
print(df.head(5))
# 创建新的特征值
def get_family_size(sibsp, parch):
family_size = sibsp + parch
return family_size
df["family_size"] = df[["sibsp", "parch"]].apply(lambda x: get_family_size(x["sibsp"], x["parch"]), axis=1)
print(df.head(5))
# 更换标签
df = df[['pclass', 'index', 'sex']]
写在最后
上面根据课程Pandas一些最基本操作,以及解决课程中利用PyCharm编程时的一些问题,其他更加细致的操作看官方库。。。














 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









