







版权声明:本文为博主原创文章,未经博主允许不得转载
论文:R-FCN: Object Detection via Region-based Fully Convolutional Networks
链接:https://arxiv.org/abs/1605.06409
何凯明大神的文章
1.概述
RCNN 在目标检测上取得了很大的成功,比如 SPPnet、Fast R-CNN、Faster R-CNN 等,这些方法的典型特征都是 一个二分网络,以 ROI Pooling 为界,前面子网络用于特征提取,后面子网络用于目标检测(Per ROI),带来的问题是后面的子网络需要对每一个 ROI(Candidate)进行重复计算。
文章是这么说的,This decomposition [8] was historically resulted from the pioneering classification architectures, such as AlexNet [10] and VGG Nets [23], that consist of two subnetworks by design — a convolutional subnetwork ending with a spatial pooling layer, followed by several fully-connected (fc) layers。
But recent state-of-the-art image classification networks such as Residual Nets (ResNets) [9] and GoogLeNets [24, 26] are by design fully convolutional. By analogy, it appears natural to use all convolutional layers to construct the shared convolutional subnetwork in the object detection architecture, leaving the RoI-wise subnetwork no hidden layer. However, as empirically investigatedin this work, this naïve solution turns out to have considerably inferior detection accuracy that does not match the network’s superior classification accuracy.
为了解决这个问题,在ResNet网络层中插入RoI-wise subnetwork,由于RoI的参数不共享,所以以损失速度的代价下提高了目标检测的精度。
原文是这么说的,We argue that the aforementioned unnatural design is caused by a dilemma of increasing translation invariance for image classification vs. respecting translation variance for object detection.
inserts the RoI pooling layer into convolutions — this region-specific operation breaks down translation invariance,and the post-RoI convolutional layers are no longer translation-invariant when evaluated across different regions
也就是说:
● 分类问题: 具有平移不变性(Translation Invariance);
● 检测问题 :具有平移敏感性 (Translation Variance);
那么问题来了,怎么插入Roi pooling呢?本文为了解决分类的平移不变性,作者构建了position-sensitive score
maps。每一个position-sensitive score map融合位置信息。在position-sensitive score maps上,再添加一个RoI pooling layer融合所有的信息。整个网络可以通过端到端学习,fig1显示了R-FCN的过程。作者用101层的Residual Net,R-FCN取得了83.6%的mAP在VOC2007上,2012上取得了82.0%。同时时间170ms每张图片,是Faster RCNN的2.5倍以上。Tab1介绍了插入的RoI pooling的位置,可以看到 R-CNN 整个网络都用作检测,Faster后面10层用于检测,而作者新提出的方法则是将101层全部用于共享。


2.论文详解
R-FCN 沿用了 Faster RCNN 的网络结构,如fig2所示:

Backbone architecture:
去掉原始ResNet101的最后一层全连接层,保留前100层,再接一个1*1*1024的全卷积层(100层输出是2048,为了降维,再引入了一个1*1的卷积层)
Position-sensitive score maps & Position-sensitive RoI pooling:
Scores Maps 的组合是卷积层的关键部分,描述了目标的 Score 信息,每一个 Score Map 对应目标的一部分,比如上图中黄色 Map 表示左上角,其C+1维通道表示了分类类别(C个类别+1个背景)
Pooling :bin(Pool之后得到的9个不同的颜色块) 的尺寸描述为 (W/k,H/k),每一个 bin 用如下公示来描述,也就是平均,注意一点ROI pooling是每个feature map单独做,不是多个channel一起的
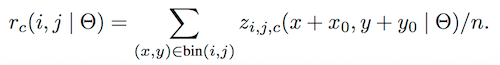
Vote:多个 bin 求和得到每个类的Score,并通过 Softmax 进行分类。

box regression:
We further address bounding box regression [7, 6] in a similar way. Aside from the above k2(C +1)-dconvolutional layer, we append a sibling 4k2-d convolutional layer for bounding box regression。
Then it is aggregated into a 4-d vector by average voting. This 4-d vector parameterizes abounding box as t = (tx, ty, tw, th)。
Training:

3.实验结果

参考:https://blog.csdn.net/linolzhang/article/details/75137050
https://zhuanlan.zhihu.com/p/30867916
补充:
空洞卷积:参考https://www.zhihu.com/question/54149221
感受野计算:(kernel-1)*stride+上一层感受野 空洞的kernel参考知乎链接。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









