







0x01、前言
Ganglia是UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia的核心包含gmond、gmetad以及一个Web前端。主要是用来监控系统性能,如:cpu 、mem、硬盘利用率,I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
ganglia还是很受欢迎的一个集群监控软件,能够在短短几秒之内就能知道数以千计的服务器运行状态,是一个企业监控/管理的软件,下面一起来看看如何配置服务器及客户端节点。
1、在这里,本文介绍配置的监控节点如下:
| 服务名称 | 节点 |
|---|---|
| 服务端 | 10.1.1.51 |
| 客户端 | 10.1.1.50 |
| 客户端 | 10.1.1.251 |
注意:服务端只能有一个,客户端可以有很多个,并且服务端是需要安装gmated的,如果你服务端也要监控它的运行状态的话,那么也要装上gmond;客户端只需要安装gmond就可以了。
在这里本文不介绍如何安装ganglia,只介绍配置服务端和客户端,如果你需要安装的步骤请自行搜索,敬请谅解。
0x0x2、服务端配置(10.1.1.51)
- 修改gmetad.conf文件,修改两个地方,一个是设置集群的名字及监控的客户端ip、端口;另外一个是设置信任的主机,相当于设置白名单。
vim /etc/ganglia/gemtad.conf # 这个路径可能不一样,你需要找一下这个gmetad.conf文件在哪
#data_source "my cluster" localhost # 这个是默认的
data_source "my cluster" 10 10.1.1.51:8649 10.1.1.1.251:8649 10.1.1.50:8649 # 前面第一个是“my **”是集群名称,后面是需要监控的客户端的ip地址
# trusted_hosts 127.0.0.1 169.229.50.165 my.gmetad.org # 这个是默认的
trusted_hosts 127.0.0.1 10.1.1.51 10.1.1.251 10.1.1.50 # 添加这些信任的客户端ip
- 修改ganglia.conf,这个文件路径同样也是你需要查找一下,可能路径不太一样,后面将不再提醒这个路径问题
可能你们的需要注意复制才行: sudo cp /etc/ganglia-webfrontend/apache.conf /etc/apache2/sites-enabled/ganglia.conf(很关键的一步)
vim /etc/apache2/sites-enabled/ganglia.conf
Alias /ganglia /usr/share/ganglia-webfrontend
<Directory "/usr/share/ganglia-webfrontend">
AllowOverride All
Order allow,deny
Allow from all
Deny from none
</Directory>
0x03、客户端配置(10.1.1.51、10.1.1.50、10.1.1.251)
需要注意的是,客户端在Ubuntu和CentOS上是不同的包名:
Ubuntu 是安装 Ganglia-monitor;CentOS 是安装ganglia-gmond
- 配置客户端10.1.1.51、10.1.1.50、10.1.1.251,gmond.conf
vim /etc/ganglia/gmond.conf
修改以下内容:
globals {
daemonize = yes
setuid = yes
user = ganglia
debug_level = 0
max_udp_msg_len = 1472
mute = no
deaf = no
host_dmax = 604800 /*secs 超过这个秒数未汇报数据,那么节点则会被清除掉,86400为一天,这里配置的是7天*/
cleanup_threshold = 60 /*secs 原来是300,这里修改为60是为了更新及时 */
gexec = no
send_metadata_interval = 0
}
cluster {
#name = "unspecified"
name = "my cluster" # cluster名称就是在gmetad.conf里配置的data_source名称
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#mcast_join = 239.2.11.71
host = 10.1.1.51 # 填写服务器端ip地址,表示当前的客户端发送udp报文给谁
port = 8649
ttl = 1
}
/* You can specify as many udp_recv_channels as you like as well. */
udp_recv_channel {
#mcast_join = 239.2.11.71
port = 8649
#bind = 239.2.11.71
}
至此,基础的监控功能的服务端、客户端配置完成,下面来看一下成果
0x04、查看ganglia-web,监控数据
打开:http://10.1.1.51:8088/ganglia即可看到监控的数据,如下:

可以看到在服务端设置的默认集群名字:my cluster
至于节点名字显示问题,已经在上图中介绍了,请注意留看
先来随便看一个节点的数据,下面展示的是50节点的数据:
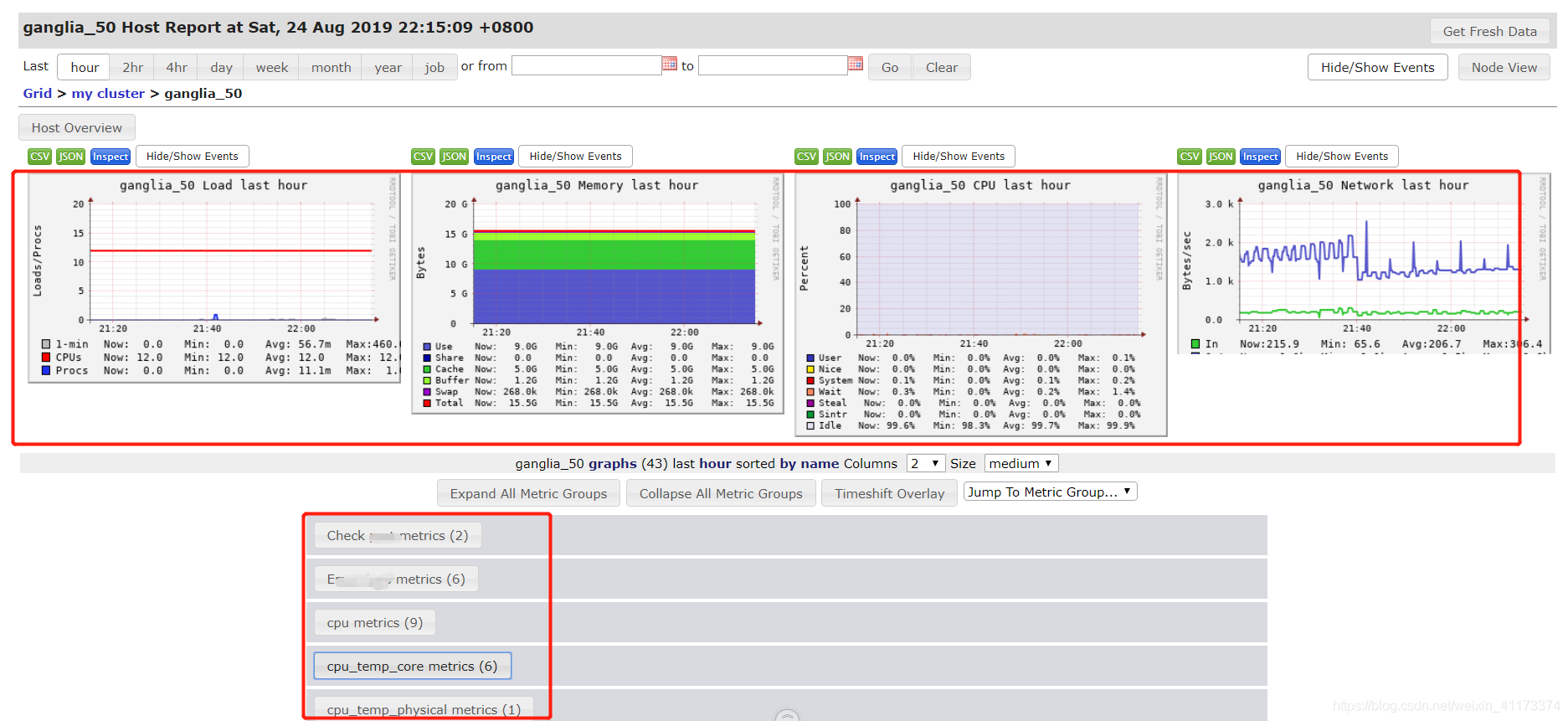
来看看负载情况,这个是ganglia默认监控的数据,可以看出这个软件有多方便,自带好一些监控的服务
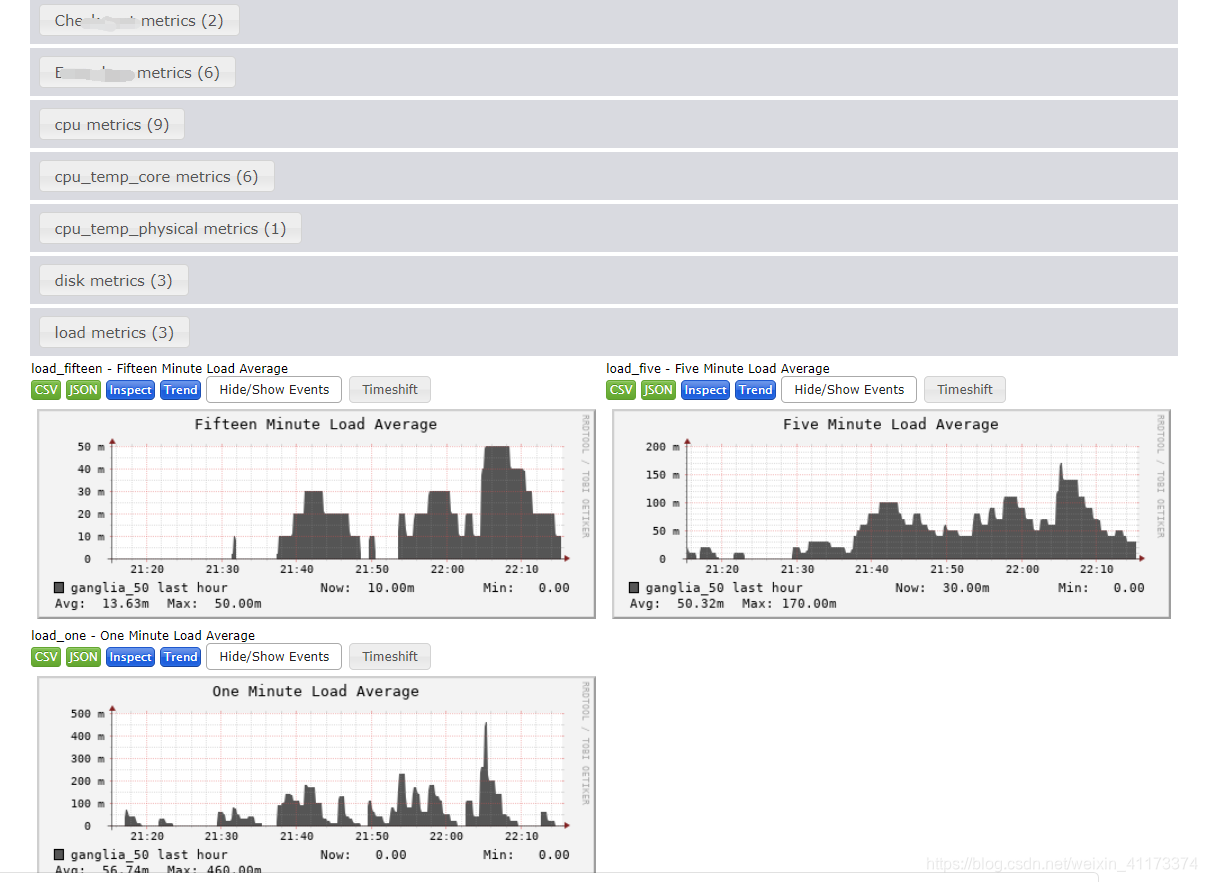
至此,基础的ganglia监控数据已经配置完毕,下面我们来设置一些额外的监控,比如监控cpu温度。
0x05、使用Python自定义扩展ganglia插件
这里只是介绍最简单的自定义插件扩展,监控CPU的温度,本教程使用的插件是来源于ganglia官网的插件,如需下载插件,请右键点击这里进行下载
这个插件资源包含很多监控服务的了,能满足所有的企业的基本监控需求,可以多尝试自定义去扩展监控服务
- 首先去客户端节点配置
请确保gmond.conf文件里面存在这一行配置,下面这个路径就是用来自定义扩展插件的:
vim /etc/ganglia/gmond.conf
include (’/etc/ganglia/conf.d/*.conf’)
然后创建目录conf.d,这个目录默认是不存在的
mkdir /etc/ganglia/conf.d
切换到conf.d目录下,创建自定义的python扩展插件的配置文件:modpython.conf
cd /etc/ganglia/conf.d
touch modpython.conf
然后保存以下内容:
modules {
module {
name = "python_module"
path = "/usr/lib/ganglia/modpython.so"
params="/etc/ganglia/python_modules"
}
}
include("/etc/ganglia/conf.d/*.pyconf")
然后上传刚刚下载的资源里面,cpu_temp/conf.d/cpu_temp.pyconf,将cpu_temp.pyconf上传
rz -y # 弹出窗口之后,选择cpu_temp.pyconf文件上传
然后在/etc/ganglia/目录下创建目录python_modules,并且上传cpu_temp/python_modules/cpu_temp.py,上传cpu_temp.py脚本
mkdir /etc/ganglia/python_modules
cd /etc/ganglia/python_modules
rz -y # 弹出窗口之后,选择cpu_temp.py文件上传
至此,自定义扩展算完成了100%,也可以说完成了90%,为什么呢,因为脚本cpu_temp.py不是一定能够运行成功的,每个人的服务器的cpu温度缓存文件路径不一定都是一样的,首先我们来检查一下脚本能否正常启动读取数据:
python2 cpu_temp.py
如果你看到报错,并且是说找不到文件路径,或者文件路径不存在的错误的话,建议你去搜索一下cpu温度的相关缓存文件在哪,然后再和脚本的路径对比,你就可以修改脚本文件,最终得以正确运行脚本
下面我已经注释了修改的路径,如果你们的修改之后,这个路径还是不对的话,你们你们可以直接搜索下面这条命令,然后将搜索出来的文件路径和脚本的路径进行对比,就很快改好这个脚本了:
sudo find / -name coretemp*
下面我放一下我修改后的代码:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
# @Time : 2019/8/15 19:43
# @Author : qizai
# @File : cpu_temp.py
# @Software: PyCharm
import os
descriptors = list()
sysdir = '/sys/devices/platform/'
handler_dict = dict()
def metric_init(params):
global descriptors
try:
coretemp_list = [i for i in os.listdir(sysdir) if i.startswith('coretemp')]
except OSError:
print 'No dir named' + sysdir
os._exit(1)
if not coretemp_list:
print 'No dir name starts with coretemp'
os._exit(1)
for coretemp in coretemp_list: # 记得全部都要对应加上这个路径 /hwmon/hwmon1,不然全部都是找不到的,你们根据自己服务器来对应修改
coreinput_list = [i for i in os.listdir(sysdir + coretemp + '/hwmon/hwmon1') if i.endswith('_input')]
try:
with open(sysdir + coretemp + '/hwmon/hwmon1' + '/temp1_label','r') as f:
phy_id_prefix = f.read().split()[-1]
except IOError:
print 'No temp1_label file'
os._exit(1)
for coreinput in coreinput_list:
build_descriptor(coretemp,coreinput,phy_id_prefix)
return descriptors
def build_descriptor(coretemp,coreinput,phy_id_prefix):
global handler_dict
if coreinput == 'temp1_input':
name = 'cpu_temp_physical_' + phy_id_prefix
description = 'Physical CPU id ' + phy_id_prefix + ' Temperature'
groups = 'cpu_temp_physical'
handler_dict[name] = sysdir + coretemp + '/hwmon/hwmon1' + '/temp1_input'
else:
with open(sysdir + coretemp + '/hwmon/hwmon1' + '/' + coreinput[:-6] + '_label','r') as f:
coreid = f.read().split()[-1]
name = 'cpu_temp_core_' + phy_id_prefix + '_' + coreid
description = 'Physical CPU id ' + phy_id_prefix + ' Core ' + coreid + ' Temperature'
groups = 'cpu_temp_core'
handler_dict[name] = sysdir + coretemp + '/hwmon/hwmon1' + '/' + coreinput
call_back = metric_handler
d = {'name': name,
'call_back': call_back,
'time_max': 60,
'value_type': 'float',
'units': 'C',
'slope': 'both',
'format': '%.1f',
'description': description,
'groups': groups
}
try:
call_back(name)
descriptors.append(d)
except:
print 'Build descriptor Failed'
def metric_handler(name):
try:
with open(handler_dict.get(name),'r') as f:
temp = f.read()
except:
temp = 0
temp_float = int(temp) / 1000.0
return temp_float
def metric_cleanup():
pass
if __name__ == '__main__':
metric_init({})
for d in descriptors:
v = d['call_back'](d['name'])
print "----------------------------------------------------------------------------------------"
print 'value for %s is %.1f %s' % (d['name'],v,d['units'])
for k,v in d.iteritems():
print k,v
0x06、重启服务端、客户端
在这里我又要提醒各位,重启的时候,貌似也有一定的顺序,个人测试了发现,重启顺序如下:
sudo /etc/init.d/gmetad restart # 最先要重启服务端(或者理解为,先启动服务器)
sudo /etc/init.d/ganglia-monitor restart # 然后再启动客户端
sudo /etc/init.d/apache2 restart # 再启动Apache
上面重启的步骤当中,最主要就是:启动服务端要比启动客户端早才行,不然你在ganglia-web看不到客户端这些节点的,或者看到节点也是看不到数据的,我在这里已经踩坑很久了,找了很久原因才找到是这个原因,希望能够帮助你们。
0x07、最后来看一下自定义插件能否生效
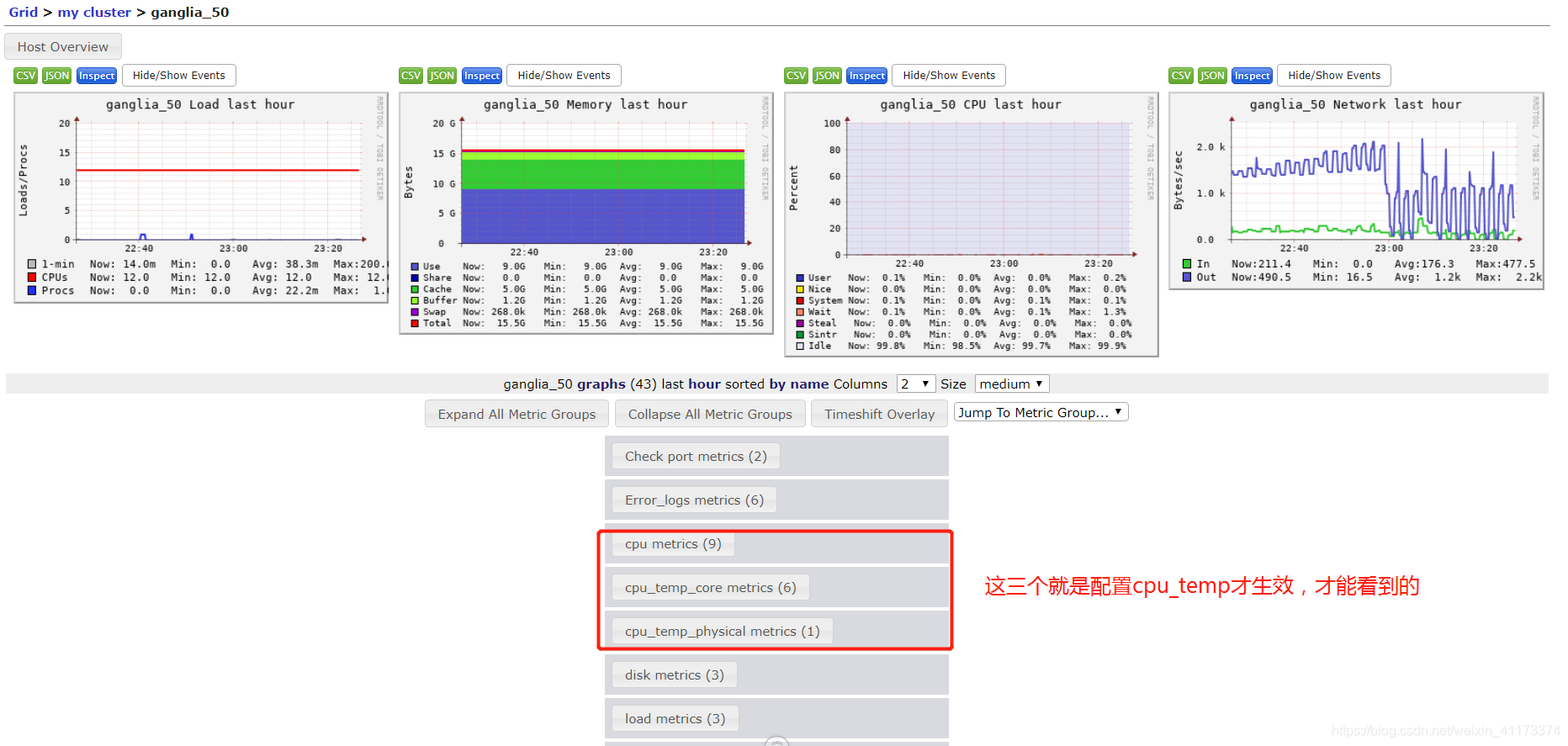
如果你细心的话,在前面截图当中,你已经见到过这个监控服务了,本人在写这篇博客的时候,是已经配置好了的,所以你在前面见到这个监控服务当然是正常的。
但如果是新的节点,只是默认配置的话,是没有这个监控cpu温度的,因为前面也说了每个服务器的cpu温度缓存文件是不一定都是同一个,所以ganglia开发者是很难适配我们所有的用户的。
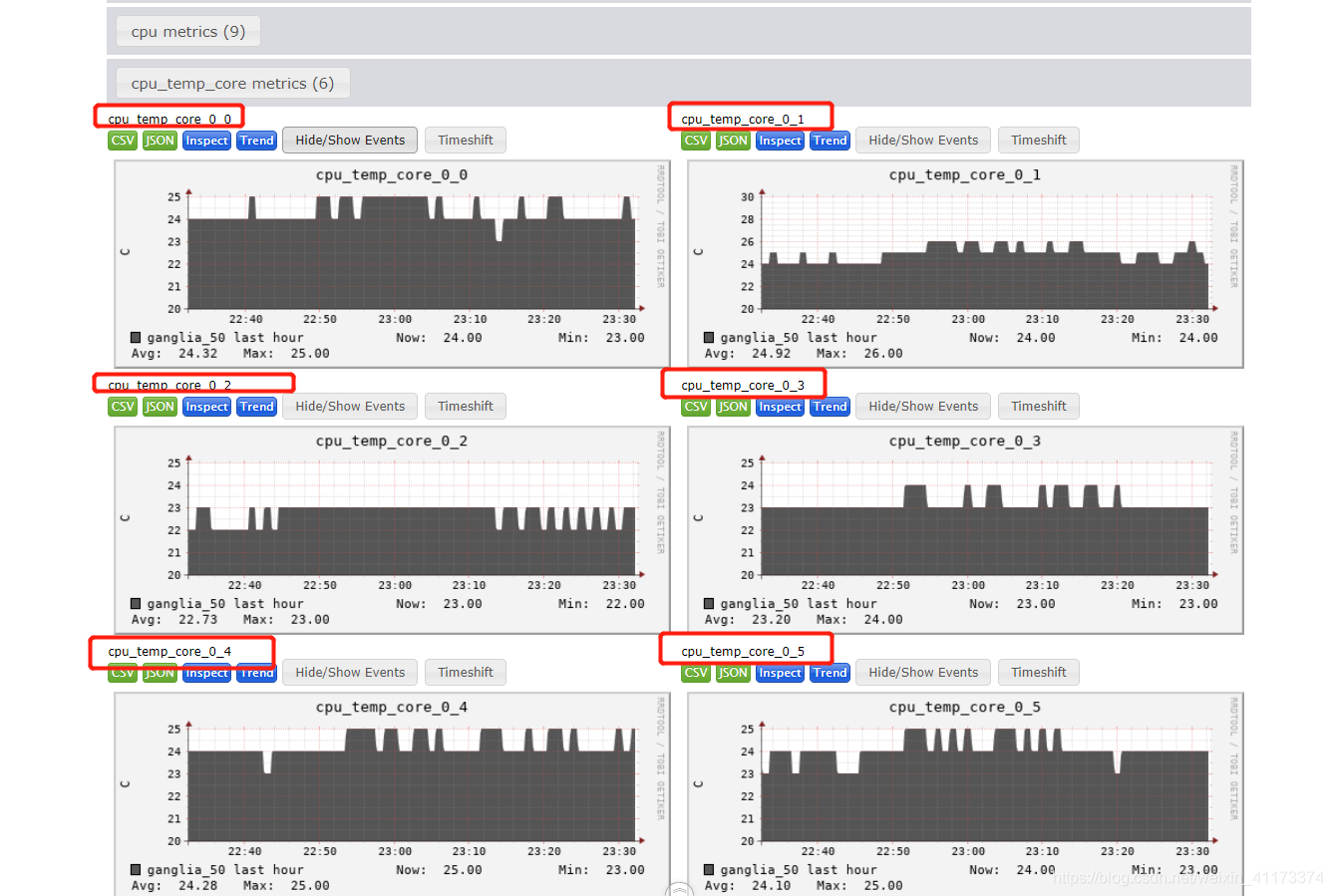
至此本文教程写完了,希望能够帮助到各位在运维路上的小伙伴们,觉得不错点个赞呗
感谢认真读完的这篇教程的您
先别走呗,这里有可能有你需要的干货文章:















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









