







前言
1、Hadoop简介
1.1 Hadoop起源
Hadoop起源于Google的三大论文:
- GFS:Google的分布式文件系统Google File System
- MapReduce:Google的MapReduce开源分布式并行计算框架
- BigTable:一个大型的分布式数据库
演变关系:
- GFS—->HDFS
- Google MapReduce—->Hadoop MapReduce
- BigTable—->HBase
Hadoop名字不是一个缩写,是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
1.2 Hadoop主流版本
- Apache基金会hadoop
- Cloudera版本(Cloudera’s Distribution Including -Apache Hadoop,简称“CDH”)
- Hortonworks版本(Hortonworks Data Platform,简称“HDP”)

1.3 Hadoop框架
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
- HDFS为海量的数据提供了存储。
- MapReduce为海量的数据提供了计算。
Hadoop框架包括以下四个模块:
- Hadoop Common: 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。
- Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。
- Hadoop Distributed File System (HDFS): 分布式文件系统,提供对应用程序数据的高吞吐量访问。
- Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。
1.4 Hadoop应用场景
- 在线旅游
- 移动数据
- 电子商务
- 能源开采与节能
- 基础架构管理
- 图像处理
- 诈骗检测
- IT安全
- 医疗保健
1.5 大数据技术神态体系图

2、Hadoop部署
这里我们以Apache Hadoop为例子
Apache Hadoop官网
Apache Hadoop官方部署手册
2.1 单机模式(适合开发,测试)
1.解压3.2.1安装包与java环境包
[root@hadoop1 ~]# ls
hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz
[root@hadoop1 ~]# useradd -u 1000 hadoop ## 添加hadoop用户
[root@hadoop1 ~]# mv * /home/hadoop/ ## 将目录移到hadoop家目录
[root@hadoop1 ~]# su - hadoop ## 切到hadoop用户
[hadoop@hadoop1 ~]$ ls
hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz
[hadoop@hadoop1 ~]$ tar zxf hadoop-3.2.1.tar.gz
[hadoop@hadoop1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@hadoop1 ~]$ ls
hadoop-3.2.1 hadoop-3.2.1.tar.gz jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
2.设置软链接
[hadoop@hadoop1 ~]$ ln -s jdk1.8.0_181/ java
[hadoop@hadoop1 ~]$ ln -s hadoop-3.2.1 hadoop
[hadoop@hadoop1 ~]$ ls
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181
hadoop-3.2.1 java jdk-8u181-linux-x64.tar.gz
3.编辑配置文件
[hadoop@hadoop1 ~]$ cd hadoop/etc/hadoop/
[hadoop@hadoop1 hadoop]$ ls
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
container-executor.cfg log4j.properties
core-site.xml mapred-env.cmd
hadoop-env.cmd mapred-env.sh
hadoop-env.sh mapred-queues.xml.template
hadoop-metrics2.properties mapred-site.xml
hadoop-policy.xml shellprofile.d
hadoop-user-functions.sh.example ssl-client.xml.example
hdfs-site.xml ssl-server.xml.example
httpfs-env.sh user_ec_policies.xml.template
httpfs-log4j.properties workers
httpfs-signature.secret yarn-env.cmd
httpfs-site.xml yarn-env.sh
kms-acls.xml yarnservice-log4j.properties
kms-env.sh yarn-site.xml
[hadoop@hadoop1 hadoop]$ vim hadoop-env.sh
54 export JAVA_HOME=/home/hadoop/java
55
56 # Location of Hadoop. By default, Hadoop will attempt to determine
57 # this location based upon its execution path.
58 export HADOOP_HOME=/home/hadoop/hadoop
4.单机模式配置
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@hadoop1 hadoop]$ mkdir input
[hadoop@hadoop1 hadoop]$ cp etc/hadoop/*.xml input/
[hadoop@hadoop1 hadoop]$ ls input/
capacity-scheduler.xml hdfs-site.xml kms-site.xml
core-site.xml httpfs-site.xml mapred-site.xml
hadoop-policy.xml kms-acls.xml yarn-site.xml
[hadoop@hadoop1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar
[hadoop@hadoop1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
[hadoop@hadoop1 hadoop]$ ls
bin include lib LICENSE.txt output sbin
etc input libexec NOTICE.txt README.txt share
[hadoop@hadoop1 hadoop]$ cd output/
[hadoop@hadoop1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@hadoop1 output]$ cat *
1 dfsadmin

2.2 伪分布式(Pseudo-Distributed)
数据节点DN与NN在一台主机(hadoop1)上
2.2.1 配置文件
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@hadoop1 hadoop]$ vim core-site.xml
[hadoop@hadoop1 hadoop]$ vim hdfs-site.xml

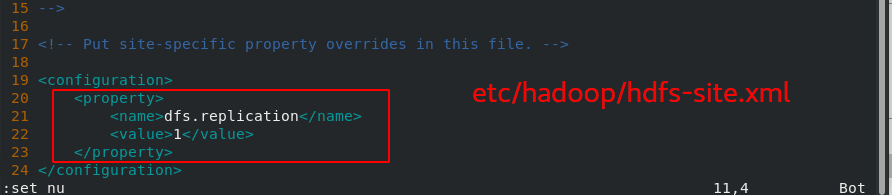
2.2.2 配置免密
[root@hadoop1 ~]# echo westos |passwd --stdin hadoop ## 给hadoop用户增加密码
Changing password for user hadoop.
passwd: all authentication tokens updated successfully.
配置免密
[hadoop@hadoop1 hadoop]$ ssh-keygen
[hadoop@hadoop1 hadoop]$ ssh-copy-id localhost
格式化
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@hadoop1 hadoop]$ bin/hdfs namenode -format
开启hadoop
[hadoop@hadoop1 hadoop]$ sbin/start-dfs.sh
添加环境变量
[hadoop@hadoop1 ~]$ vim .bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/hadoop/bin:$HOME/java/bin
[hadoop@hadoop1 ~]$ source .bash_profile
查看
[hadoop@hadoop1 ~]$ jps
14640 SecondaryNameNode
14309 NameNode
14429 DataNode
14815 Jps
测试上传下载
[hadoop@hadoop1 ~]$ hdfs dfs -mkdir -p /user/hadoop #Make the HDFS directories required to execute MapReduce jobs
[hadoop@hadoop1 ~]$ cd hadoop
[hadoop@hadoop1 hadoop]$ hdfs dfs -put input/ # Copy the input files into the distributed filesystem:
[hadoop@hadoop1 hadoop]$ hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2021-03-23 10:50 input
[hadoop@hadoop1 hadoop]$ hdfs dfs -ls input
Found 9 items
-rw-r--r-- 1 hadoop supergroup 8260 2021-03-23 10:50 input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 774 2021-03-23 10:50 input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 11392 2021-03-23 10:50 input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 775 2021-03-23 10:50 input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2021-03-23 10:50 input/httpfs-site.xmlHUTDOWN_MSG: Shutting down NameNode at server1/172.25.200.1
-rw-r--r-- 1 hadoop supergroup 3518 2021-03-23 10:50 input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 682 2021-03-23 10:50 input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 758 2021-03-23 10:50 input/mapred-site.xml
-rw-r--r-- 1 hadoop supergroup 690 2021-03-23 10:50 input/yarn-site.xml
[hadoop@hadoop1 hadoop]$ rm -fr output/ input/
[hadoop@hadoop1 hadoop]$ hdfs dfs -ls input
Found 9 items
-rw-r--r-- 1 hadoop supergroup 8260 2021-03-23 10:50 input/capacity-scheduler.xml
-rw-r--r-- 1 hadoop supergroup 774 2021-03-23 10:50 input/core-site.xml
-rw-r--r-- 1 hadoop supergroup 11392 2021-03-23 10:50 input/hadoop-policy.xml
-rw-r--r-- 1 hadoop supergroup 775 2021-03-23 10:50 input/hdfs-site.xml
-rw-r--r-- 1 hadoop supergroup 620 2021-03-23 10:50 input/httpfs-site.xml
-rw-r--r-- 1 hadoop supergroup 3518 2021-03-23 10:50 input/kms-acls.xml
-rw-r--r-- 1 hadoop supergroup 682 2021-03-23 10:50 input/kms-site.xml
-rw-r--r-- 1 hadoop supergroup 758 2021-03-23 10:50 input/mapred-site.xml
-rw-r--r-- 1 hadoop supergroup 690 2021-03-23 10:50 input/yarn-site.xml
[hadoop@hadoop1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
[hadoop@hadoop1 hadoop]$ hdfs dfs -get output ## 下载到本地
[hadoop@hadoop1 hadoop]$ hdfs dfs -rm -r output ## 删除
[hadoop@hadoop1 hadoop]$ sbin/stop-dfs.sh ## 停止服务
9870端口web访问


2.3 完全分布式
准备两个节点:hadoop2,hadoop3
2.3.1 为所有节点配置nfs共享文件系统
将家目录作为hadop1,hadoop2,hadoop3的共享目录
先停止2.2的伪分布式
[hadoop@hadoop1 sbin]$ ./stop-dfs.sh ##必须保证关闭
[root@hadoop1 ~]# yum install -y nfs-utils ##安装nfs共享文件系统,三个节点同时安装
hadoop1操作
[root@server1 ~]# vim /etc/exports
[root@server1 ~]# cat /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server1 ~]# systemctl enable --now nfs
[root@server1 ~]# showmount -e
Export list for server1:
/home/hadoop *
hadoop2操作(hadoop3与之操作相同)
[root@hadoop2 ~]# useradd -u 1000 hadoop
[root@hadoop2 ~]# ll -d /home/hadoop/
drwx------ 2 hadoop hadoop 62 Mar 22 23:15 /home/hadoop/
[root@hadoop2 ~]# mount 172.25.200.1:/home/hadoop/ /home/hadoop/
[root@hadoop2 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1165460 16645996 7% /
devtmpfs 1011448 0 1011448 0% /dev
tmpfs 1023468 0 1023468 0% /dev/shm
tmpfs 1023468 16984 1006484 2% /run
tmpfs 1023468 0 1023468 0% /sys/fs/cgroup
/dev/vda1 1038336 135080 903256 14% /boot
tmpfs 204696 0 204696 0% /run/user/0
172.25.200.1:/home/hadoop 17811456 3136512 14674944 18% /home/hadoop
[root@hadoop2 ~]# vim /etc/rc.d/rc.local #在开机启动后自动挂载
mount 172.25.200.1:/home/hadoop/ /home/hadoop/
[root@hadoop2 ~]# source /etc/rc.d/rc.local
2.3.2 配置完全分布式
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@hadoop1 hadoop]$ vim core-site.xml
[hadoop@hadoop1 hadoop]$ vim workers ## 必须要有解析
[hadoop@hadoop1 hadoop]$ vim hdfs-site.xml
[hadoop@hadoop1 hadoop]$ hdfs namenode -format ##格式化
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@hadoop1 hadoop]$ sbin/start-dfs.sh ##启动节点
Starting namenodes on [hadoop1]
Starting datanodes
Starting secondary namenodes [hadoop1]
[hadoop@hadoop1 hadoop]$ jps ##hadoop1只作为计算调度节点
8340 Jps
7989 NameNode
8220 SecondaryNameNode
[root@hadoop3 ~]# su - hadoop ##hadoop2和hadoop3作为数据节点
[hadoop@hadoop3 ~]$ jps
4236 DataNode
4332 Jps



后台web可查看两个数据节点
2.3.3 测试
[hadoop@hadoop1 hadoop]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@hadoop1 hadoop]$ hdfs dfs -mkdir input
[hadoop@hadoop1 hadoop]$ hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2021-03-31 11:06 input
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop/
[hadoop@hadoop1 hadoop]$ cd etc/hadoop/
[hadoop@hadoop1 hadoop]$ hdfs dfs -put * input


后台web查看


2.4 热增加节点(hadoop热插拔节点)
新增加hadoop4节点,操作与hadoop2,3相似
安装nfs
[root@hadoop4 ~]# yum install -y nfs-utils
[root@hadoop4 ~]# useradd -u 1000 hadoop
[root@hadoop4 ~]# mount 172.25.200.1:/home/hadoop/ /home/hadoop/
[root@hadoop4 ~]# su - hadoop
[hadoop@hadoop4 bin]$ pwd
/home/hadoop/hadoop/bin
[hadoop@hadoop4 bin]$ hdfs --daemon start datanode
[hadoop@hadoop4 bin]$ jps
3780 DataNode
3844 Jps
[hadoop@hadoop4 bin]$ cd
[hadoop@hadoop4 ~]$ ls
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181 zookeeper-3.4.9
hadoop-3.2.1 java jdk-8u181-linux-x64.tar.gz
[hadoop@hadoop4 ~]$ hdfs dfs -put jdk-8u181-linux-x64.tar.gz
[hadoop@hadoop4 ~]$ hdfs dfs -put hadoop-3.2.1.tar.gz





2.5 热删除节点
[hadoop@hadoop1 hadoop]$ cat hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop/etc/hadoop/excludes</value>
</property>
</configuration>
第一次必须重启整个集群,把这个功能写入,不然没法热删除
[hadoop@hadoop1 sbin]$ pwd
/home/hadoop/hadoop/sbin
[hadoop@hadoop1 sbin]$ ./stop-dfs.sh
[hadoop@hadoop1 sbin]$ ./start-dfs.sh
重启后修改excludes文件,直接刷新有效
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@hadoop1 hadoop]$ vim excludes
hadoop3
[hadoop@hadoop1 hadoop]$ hdfs dfsadmin -refreshNodes

3、Hadoop热备(hdfs高可用)
hadoop1 hadoop5作为计算控制节点,hadoop234作为日志节点。
3.1 清理环境并安装zookeeper
1. 清理环境并安装zookeeper
[hadoop@hadoop1 ~]$ cd hadoop/sbin/
[hadoop@hadoop1 sbin]$ ./stop-dfs.sh ##关掉集群
[hadoop@hadoop1 sbin]$ ps ax
[hadoop@hadoop1 ~]$ rm -fr /tmp/* ##删除/tmp/下的文件 ,不行就使用root用户
[hadoop@hadoop1 ~]$ tar zxf zookeeper-3.4.9.tar.gz ##解压,做协调器
切到hadoop2,因为做了nfs,文件是同步的
[hadoop@hadoop2 ~]$ cd zookeeper-3.4.9/
[hadoop@hadoop2 zookeeper-3.4.9]$ ls
bin dist-maven LICENSE.txt src
build.xml docs NOTICE.txt zookeeper-3.4.9.jar
CHANGES.txt ivysettings.xml README_packaging.txt zookeeper-3.4.9.jar.asc
conf ivy.xml README.txt zookeeper-3.4.9.jar.md5
contrib lib recipes zookeeper-3.4.9.jar.sha1
[hadoop@hadoop2 zookeeper-3.4.9]$ cd conf
[hadoop@hadoop2 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[hadoop@hadoop2 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@hadoop2 conf]$ ls
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
[hadoop@hadoop2 conf]$ vim zoo.cfg ##文件修改的内容如下,目录需要自己创建
[hadoop@hadoop2 conf]$ grep server. zoo.cfg
server.1=172.25.200.2:2888:3888
server.2=172.25.200.3:2888:3888
server.3=172.25.200.4:2888:3888
[hadoop@hadoop2 conf]$ mkdir /tmp/zookeeper
[hadoop@hadoop2 conf]$ echo 1 > /tmp/zookeeper/myid ##写入id号,主机和文件中对应
[hadoop@hadoop3 ~]$ mkdir /tmp/zookeeper
[hadoop@hadoop3 ~]$ echo 2 > /tmp/zookeeper/myid
[hadoop@hadoop4 ~]$ mkdir /tmp/zookeeper
[hadoop@hadoop4 ~]$ echo 3 > /tmp/zookeeper/myid

3.2 在各节点启动服务
1.启动节点
[hadoop@hadoop2 zookeeper-3.4.9]$ pwd
/home/hadoop/zookeeper-3.4.9
[hadoop@hadoop2 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop3 ~]$ cd zookeeper-3.4.9/
[hadoop@hadoop3 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop4 ~]$ cd zookeeper-3.4.9/
[hadoop@hadoop4 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2.查看状态(leader节点,follow节点)
[hadoop@hadoop4 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
[hadoop@hadoop4 zookeeper-3.4.9]$


3.3 Hadoop配置
1. 编辑 core-site.xml 文件:
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@hadoop1 hadoop]$ vim core-site.xml
<!-- 指定 hdfs 的 namenode 为 masters (名称可自定义)-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<!-- 指定 zookeeper 集群主机地址,访问端口2181-->
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.200.2:2181,172.25.200.3:2181,172.25.200.4:2181</value>
</property>
</configuration>
2. 编辑 hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 指定 hdfs 的 nameservices 为 masters,和 core-site.xml 文件中的设置保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<!-- masters 下面有两个 namenode 节点,分别是 h1 和 h2 (名称可自定义)-->
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
<!-- 指定 h1 节点的 rpc 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.200.1:9000</value>
</property>
<!-- 指定 h1 节点的 http 通信地址,2代版本的端口是50070 -->
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.200.1:9870</value>
</property>
<!-- 指定 h2 节点的 rpc 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.200.5:9000</value>
</property>
<!-- 指定 h2 节点的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.200.5:9870</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.200.2:8485;172.25.200.3:8485;172.25.200.4:8485/masters</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,每个机制占用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免密码 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
3.4 配置hadoop5
[root@hadoop5 ~]# yum install nfs-utils -y ##安装nfs
[root@hadoop5 ~]# useradd -u 1000 hadoop
[root@hadoop5 ~]# mount 172.25.200.1:/home/hadoop/ /home/hadoop/
[root@hadoop5 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1159864 16651592 7% /
devtmpfs 1011448 0 1011448 0% /dev
tmpfs 1023468 0 1023468 0% /dev/shm
tmpfs 1023468 16964 1006504 2% /run
tmpfs 1023468 0 1023468 0% /sys/fs/cgroup
/dev/vda1 1038336 167848 870488 17% /boot
tmpfs 204696 0 204696 0% /run/user/0
172.25.200.1:/home/hadoop 17811456 3071232 14740224 18% /home/hadoop
[root@hadoop5 ~]# vim /etc/rc.d/rc.local
mount 172.25.200.1:/home/hadoop/ /home/hadoop/
[root@server5 ~]# su - hadoop

3.5 启动 hdfs 集群(按顺序启动)
1)在三个 DN 上依次启动 zookeeper 集群(三台操作一致),现在server4是leader
[hadoop@hadoop2 zookeeper-3.4.9]$ pwd
/home/hadoop/zookeeper-3.4.9
[hadoop@hadoop2 zookeeper-3.4.9]$ bin/zkServer.sh start ## 启动命令
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop2 zookeeper-3.4.9]$ bin/zkServer.sh status ## 查看状态
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop2]$ jps ## 可以查看到多了QuorumPeerMain节点
4803 QuorumPeerMain
5208 Jps
2)在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@hadoop2]$ hdfs --daemon start journalnode ## 启动命令
[hadoop@hadoop2]$ jps ## 可以查看到多了JournalNode节点
4803 QuorumPeerMain
5443 Jps
5402 JournalNode
3)格式化 HDFS 集群(hadoop1)
[hadoop@hadoop1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@hadoop1 hadoop]$ bin/hdfs namenode -format
Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2
[hadoop@hadoop1 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.0.5:/tmp
^C[hadoop@hadoop1 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.200.5:/tmp
VERSION 100% 215 233.5KB/s 00:00
seen_txid 100% 2 3.3KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 105.5KB/s 00:00
fsimage_0000000000000000000 100% 401 548.8KB/s 00:00
4) 格式化 zookeeper (只需在 h1 上执行即可)
$ bin/hdfs zkfc -formatZK
(注意大小写)
5)启动 hdfs 集群(只需在 h1 上执行即可)
$ sbin/start-dfs.sh
6) 查看各节点状态
[hadoop@server1 hadoop]$ jps
1431 NameNode
1739 DFSZKFailoverController
2013 Jps
[hadoop@server5 ~]$ jps
1191 NameNode
1293 DFSZKFailoverController
1856 Jps
[hadoop@server2 ~]$ jps
1493 JournalNode
1222 QuorumPeerMain
1400 DataNode
1594 Jps
[hadoop@server3 ~]$ jps
1578 Jps
1176 QuorumPeerMain
1329 DataNode
1422 JournalNode
[hadoop@server4 ~]$ jps
1441 Jps
1153 QuorumPeerMain
1239 DataNode
1332 JournalNode




3.6 测试故障自动切换
[hadoop@server1 hadoop]$ jps
1431 NameNode
2056 Jps
1739 DFSZKFailoverController
[hadoop@server1 hadoop]$ kill -9 1431
[hadoop@server1 hadoop]$ jps
1739 DFSZKFailoverController
2089 Jps
#杀掉 h1 主机的 namenode 进程后依然可以访问,此时 h2 转为 active 状态接管 namenode
[hadoop@server1 hadoop]$ sbin/hadoop-daemon.sh start namenode # 恢复namenode节点
启动 h1 上的 namenode,此时为 standby 状态。



4、yarn 热备(RM的高可用)
方法与hdfs高可用类似
4.1 配置
[hadoop@hadoop1 hadoop]$ vim hadoop-env.sh
export HADOOP_MAPRED_HOME=/home/hadoop/hadoop
[hadoop@hadoop1 hadoop]$ vim mapred-site.xml
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
1) 编辑 mapred-site.xml 文件
<configuration>
<!-- 指定 yarn 为 MapReduce 的框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2)编辑 yarn-site.xml 文件
<configuration>
<!-- 配置可以在 nodemanager 上运行 mapreduce 程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 激活 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的集群 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<!-- 定义 RM 的节点-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.200.1</value>
</property>
<!-- 指定 RM2 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.200.5</value>
</property>
<!-- 激活 RM 自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置 RM 状态信息存储方式,有 MemStore 和 ZKStore-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置为 zookeeper 存储时,指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.200.2:2181,172.25.200.3:2181,172.25.200.4:2181</value>
</property>
</configuration>
4.2 启动
[hadoop@hadoop1 hadoop]$ pwd ##master端
/home/hadoop/hadoop
[hadoop@hadoop1 hadoop]$ sbin/start-yarn.sh ##启动
Starting resourcemanager
Starting nodemanagers
[hadoop@hadoop1 hadoop]$ jps
8720 ResourceManager ##启动成功
4024 SecondaryNameNode
7069 NameNode
9038 Jps
7423 DFSZKFailoverController
[hadoop@hadoop5 ~]$ yarn --daemon start resourcemanager ##server5这个master端需要手工启动
[hadoop@hadoop5 ~]$ jps
4433 DFSZKFailoverController
4983 ResourceManager
4315 NameNode
5036 Jps
[hadoop@server2 zookeeper-3.4.9]$ jps ##slave端,如果NM起来掉线,可能是内存不足
5172 JournalNode
6004 NodeManager
5271 DataNode
4649 DFSZKFailoverController
6123 Jps
3918 QuorumPeerMain
4.3 测试
















 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









