






前置知识
BM25简介
BM25算法(Best Matching 25)是一种广泛用于信息检索领域的排名函数,用于在给定查询(Query)时对一组文档(Document)进行评分和排序。BM25在计算Query和Document之间的相似度时,本质上是依次计算Query中每个单词和Document的相关性,然后对每个单词的相关性进行加权求和。BM25算法一般可以表示为如下形式:
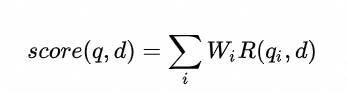
上式中,q 和 d 分别表示用来计算相似度的Query和Document, qi 表示 q 的第 i 个单词,R(qi, d) 表示单词 qi 和文档 d 的相关性,Wi 表示单词 qi 的权重,计算得到的 score(q, d) 表示 q 和 d 的相关性得分,得分越高表示 q 和 d 越相似。Wi 和 R(qi, d) 一般可以表示为如下形式:
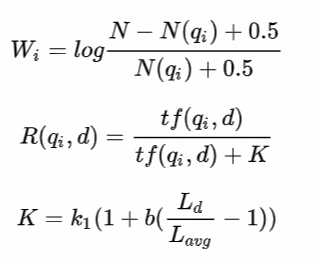
其中,N 表示总文档数,N(qi) 表示包含单词 qi 的文档数,tf(qi, d) 表示qi 在文档 d 中的词频,Ld 表示文档 d 的长度,Lavg 表示平均文档长度,k1 和 b 是分别用来控制 tf(qi, d) 和 Ld 对得分影响的超参数。
稀疏向量生成
在检索场景中,为了让BM25算法的Score方便进行计算,通常分别对Document和Query进行编码,然后通过点积的方式计算出两者的相似度。得益于BM25原理的特性,其原生支持将Score拆分为两部分Sparse Vector,DashText提供了encode_document以及encode_query两个接口来分别实现这两部分向量的生成,其生成链路如下图所示:

最终生成的稀疏向量可表示为:
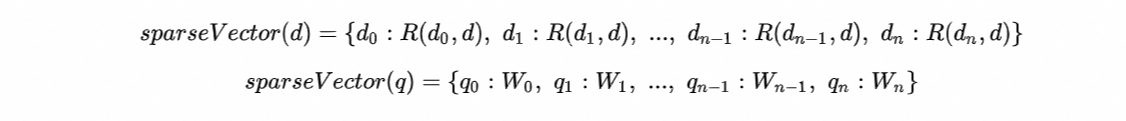
Score/距离计算
生成d和q的稀疏向量后,就可以通过简单的点积进行距离计算,即将相同单词上的值对应相乘再求和,通过稀疏向量计算距离的方式如下所示:
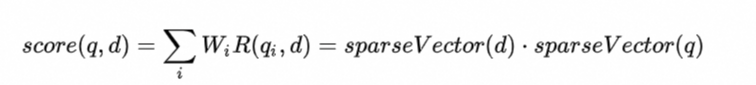
上述计算方式本质上是通过点积来计算的,score 越大表示越相似,如果需要结合Dense Vector一起进行距离度量时,需要对齐距离度量方式。也就是说,在结合Dense Vector+Sparse Vector的场景中,距离计算只支持点积度量方式。
如何自训练模型
考虑到内置的BM25 Model是基于通用语料( 中文Wiki语料)训练得到,在特定领域下通常不能表现出最佳的效果。因此,在一些特定场景下,通常建议训练自定义BM25模型。使用DashText来训练自定义模型时一般需要遵循以下步骤:
Step1:确认使用场景
当准备使用SparseVector来进行信息检索时,应提前考虑当前场景下的Query以及Document来源,通常需要提前准备好一定数量Document来入库,这些Document通常需要和特定的业务场景直接相关。
Step2:准备语料
根据BM25原理,语料直接决定了BM25模型的参数。通常应按照以下几个原则来准备语料:
- 语料来源应尽可能反映对应场景的特性,尽可能让 N(qi) 能够反映对应真实场景的词频信息。
- 调节合理的语料切片长度和切片数量,避免出现语料当中只有少量长文本的情况。
一般情况下,如无特殊要求或限制,可以直接将Step1准备的一系列Document组织为语料即可。
Step3:准备Tokenizer
Tokenizer决定了分词的结果,分词的结果则直接影响Sparse Vector的生成,在特定领域下使用自定义Tokenizer会达到更好的效果。DashText提供了两种扩展Tokenizer的方式:
- 使用自定义词表:DashText内置的Jieba Tokenizer支持传入自定义词表。(Java SDK暂不支持该功能)
Python示例:
- 使用自定义Tokenizer:DashText支持任务自定义的Tokenizer,只需提供一个符合
Callable[[str], List[str]]签名的Tokenize函数即可。
Python示例:
Step4:训练模型
实际上,这里的“训练”本质上是一个“统计”参数的过程。由于训练自定义模型的过程中包含着大量Tokenizing/Hashing过程,所以可能会耗费一定的时间。DashText提供了SparseVectorEncoder.train接口可以用来训练模型。
Step5:调参优化(可选)
模型训练完成后,可以准备部分验证数据集以及通过微调 k1 和 b 来达到最佳的召回效果。调节k1和b一般需要遵循以下原则:
- 调节k1 (1.2 < k1 < 2)可控制Document词频对Score的影响,k1 越大Document的词频对Score的贡献越小。
- 调节b (0 < b < 1)可控制文档长度对Score的影响,b 越大表示文档长度对权重的影响越大
一般情况下,如无特殊要求或限制,不需要调整 k1 和 b。
Step6:Finetune模型(可选)
实际场景下,可能会存在需要补充训练语料来增量式地更新BM25模型参数的情况。DashText的SparseVectorEncoder.train接口原生支持模型的增量更新。需要注意的是,模型更改之后,使用旧模型进行编码并已入库的向量就失去了时效性,一般需要重新入库。
示例代码
以下是一个简单完整的自训练模型示例。
Python示例:
API参考
DashText API详情可参考: dashtext · PyPI
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









