







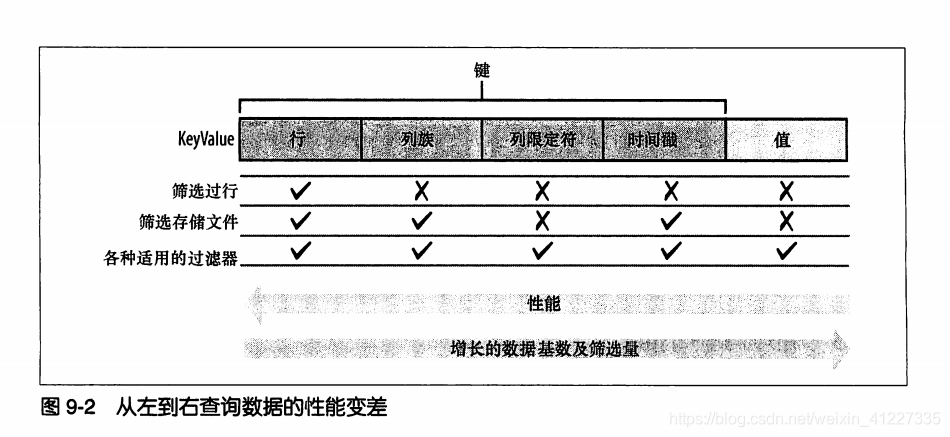
1.用户可以指定行键检索一行数据,可有效减少查询时间。
2.设定列族可减少查询的存储文件。
3.存储文件(store file)中每个单元格都保存了时间戳,
所以用户如果查询近一两个小时修改过的单元格,
HBase会跳过例如只包含4小时前数据的存储文件。
4.列限定符(column qualifier)查询,查询时指定特定的咧或定义过滤器包含或排除某个列。
由于系统需检查每个传到过滤器的KeyValue,所以性能只有小幅提升。
5.值筛选,最广泛,用户只能使用过滤器在服务器端筛选值。
系统需检查每个单元格,也只能小幅提升性能。
6.HBase高表与宽表
高表指多行少列,宽表指少行多列;
高表性能更好;因为按照行键查询更快,并且HBase只能按行分片。
7.但问题:若数据一行很长,一个HFile存不下
解决:分开存成多行。
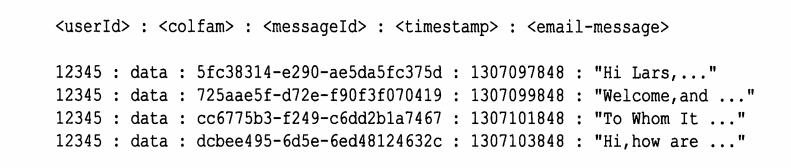
宽表:行键=userId
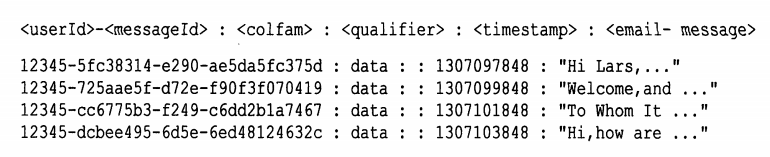
高表:行键=userId+messageId
正题:
8.实际使用中,时间序列的数据很多,例如传感器、日志、股票交易系统的数
据的行键都是按时间的,这样HBase存储的时候就会有大量数据涌入一个
Region,而已个Region只能由一个RegionServer管理,读写过分集中与一台服
务器上,不利于负载均衡。
9.解决:对罕见进行自定义处理,将数据分散到不同的Region上去。
10.方式:
1.加盐(salting)
先用时间戳的hash值余RegionServer的数量
得到一个前缀加到行键前。

2.随机化行键
将行键利用MD5散列函数随机化,将数据分散到不同region上。
缺点:不能行键按时间顺序扫描。
适用场景:每次只需读一行的数据。
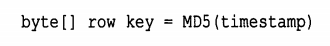
3.字段交换/提升权重
利用组合行键的方式
调整行键中多个字段的前后顺序;
或提取列键中的值放到行键的前端。














 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









