







读书笔记
前沿
在PAT里考图都和实际背景捆绑在了一起,所以一定要熟悉图的概念,将题目中的信息和图的一些概念想联系,这样你才能更好看清问题的本质,
图的定义
图由顶点Vertex和边Edge组成,每条边的两端都必须是图的两个顶点。而记号G(V,E)表示图G的顶点集合为V,边集为E。
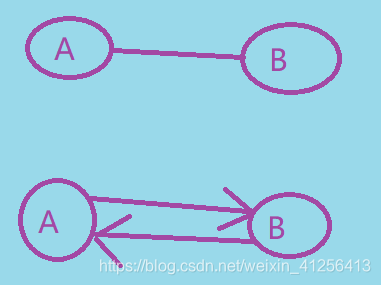
一般来说:图可以分为有向图和无向图。有向图是所有边都有方向,无向图是所有边都是双向的。
顶点的度是指和该顶点相连的边的条数。对于有向图来说:顶点的出边条数称为该顶点的出度,顶点的入边条数称为该顶点的入度。
顶点和边都可以有权重。顶点的权值称为点权,边的权值称为边权。
可能在数据结构里都没有怎么重视点权这个东西,都注意线权。所以在这里特别提醒。点权可以是城市中的资源数目,边权可以是两个城市之间的来往所需要的时间或费用
图的存储
邻接矩阵
const int maxn = 1001;
int G[maxn][maxn];
算法笔记给出的建议是邻接矩阵只适合顶点数目不太大(一般不超过1000)的题目。
邻接表
设G(V,E)的顶点为0,1,2…N-1,每个顶点都可能有若干条出边,把同一个顶点的这些出边放在一个列表中,N个顶点有N个列表:为Adj[0],Adj[1]…Adj[N-1]。就是邻接表。
如果顶点不是数字:可以使用map进行映射转换。
怎么存储
const int maxn = 10001;
vector<int> Adj[maxn];
Adj[0],Adj[1]…都是边(vector<int>)。maxn代表顶点数量。
权值表示
struct Node{
int v; //边的终点编号
int w; // 边权
Node(int _v,int _w):v(_v),w(_w){
}
}
vector<Node> Adj[maxn];
这里要啰嗦一句:对于无向图来说:可以把无向图的边看出有正向和负向的两条有向边组成。这个道理大家应该都懂。但是在PAT中:题目输入的是
点1,点2,边权。
//邻接矩阵
weight为边权
G[点1][点2] = weight
G[点2][点1] = weight
//邻接表
G[点1].push_back(Node(点2,weight));
G[点2].push_back(Node(点1,weight));
一定别忘了是双边的,不能肯定会出错。
连通分量和强连通分量
连通分量:在无向图中,如果两个顶点之间可以相互到达,那么就称这两个顶点连通。如果图G(V,E)的任意两个顶点都连通,则称图G为连通图,否则,称图G为非连通图,且称其中的极大连通子图为连通分量。
强连通分量:在有向图中:如果两个顶点的任意两个顶点可以各自通过一条有向路径到达另一个顶点,就称这两个顶点强连通。如果图G(V,E)的任意两个顶点都强连通,则图G为强连通图;否则:称图G为连通图。且称其中的极大强连通子图为强连通分量。
怎么判断图是不是连通分量(强连通分量)?DFS或BFS。
图的遍历
图的遍历不难,DFS,BFS。但是怎么通过遍历获取信息才是最难的。
DFS
DFS的伪代码
DFS(u){
vis[u] = true;
for(从u出发能到达的所有顶点v)
if vis[v] == false
DFS(v);
}
DFSTrave(G){
for(G所有顶点u)
if vis[u] == false
DFS(u);
}
BFS
BFS的伪代码
BFS(u){
queue q;
inq[u] = true;
while(q非空){
取出q的队首元素u进行访问。
for(从u出发可到达的所有顶点v){
if(inq[v]==false){
将v入队
inq[v]=true;
}
}
}
}
BFSTrave(G){
for(G所有顶点u){
if(inq[u]==false)
BFS(u);
}
}
最短路径
书上介绍了Dijkstra算法,Bellman-Ford算法,SPFA算法和Floyd算法。
Dijkstra
伪代码
const int INF = 0X3FFFFFFF;
// s是起点,d[]是起点到各个点的最短距离,初始化都为INF
Dijkstra(G,d[],pre[],s){
初始化
for(循环n此){
u = 使d[u]最小的还未访问的顶点的标号
记u已被访问
for(从u出发能到达的所有顶点v){
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









